

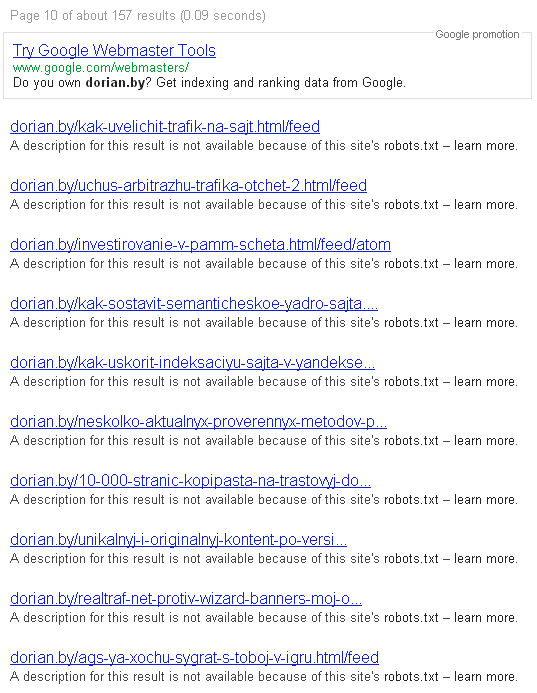
В индексе гугла есть вот такие страницы. В роботс.txt они запрещены к индексации, но гугл все равно почему-то держит их в индексе и в соплях. Причем гугл сам в дескрипшене пишет что страницы закрыты от индексации, но почему-то индексирует их...
 07.05.2013 19:54
07.05.2013 19:54- 0
- 07.05.2013 21:25Крабец


- Регистрация: 28.09.2012
- Сообщений: 334
- Репутация: 103
grazer,
этот вариант вам не подходит ?Скрытый текст (вы должны войти под своим логином или зарегистрироваться и иметь 1 сообщение(ий)):У вас нет прав чтобы видеть скрытый текст, содержащийся здесь.- 0
- 07.05.2013 21:31
Servent-of-Inos, нет, не подходит.
- 0
-
 07.05.2013 21:37
07.05.2013 21:37grazer, в панели ГВМ, есть инструменты удаления, можно постранично, можно каталогами, можно и по признаку в урле (к примеру feed), исчезают из индекса на следующий день.
Но, гугл же видит что они запрещены, и с недавних пор стал информировать (см. снипет), чтоб не нервничали - не должен он за это наказывать.- 1
Спасибо сказали:
grazer(07.05.2013), - 07.05.2013 22:10Гуру
- Регистрация: 09.10.2011
- Сообщений: 1,813
- Репутация: 251
grazer, этих страниц нет в индексе. Можете проверить вбив site:урл_страницы текст_с_страницы.
Как удалять. Если кратко то добавте тег
<META NAME="robots" CONTENT="noindex,nofollow"> на страницы которые нужно удалить. Откройте в роботс чтобы бот смог тег прочитать. Сколько времени удет незнаю. Это зависит от любит не любит бот сайт :)
Можно и через удаление урл, но сначала прочитайте
Когда НЕ следует использовать инструмент удаления URL- 0
- 07.05.2013 22:27
pyramida, страницы есть, контента который на них - нет.
через ГВМ удалял до 10к страниц за раз - номально- 0
- 07.05.2013 22:31Опытный

- Регистрация: 28.09.2011
- Сообщений: 269
- Репутация: 60
Я даже и не парюсь по поводу этих страниц в соплях гугла. Вроде ни на что не влияют.
Или я не прав, и стоит заморочиться с их удалением?- 0
- 07.05.2013 22:34Гуру
- Регистрация: 09.10.2011
- Сообщений: 1,813
- Репутация: 251
Пустые чтоли? Сообщение от genjnat
Сообщение от genjnat 
Инструмент удаляет страницы на 90 дней без возможности повторного включения. Понимаете чем может грозить? Сообщение от genjnat
---------- Сообщение добавлено 23:04 ---------- Предыдущее 23:02 ----------
Не доказанно, что есть квота на выделенно время сканирования ботом сайта. Представте если он должен просканировать только 20 страниц в день? Что будет если в пачке окажутся пустые страницы или малозначимые? Они тоже будут отнимать время. Сообщение от Textoslov - 0
- 08.05.2013 12:37чем оно может грозить? объясните :) Сообщение от pyramida
да, по ходу, никак - сам подымал недавно такую тему http://webmasters.ru/forum/f4/o-tom-...ots-txt-42988/, но собственно фишка в том, что он же их не индексирует - он просто выводит адреса этих страниц, что типа он о них знает, но контент не имеет права индексировать :) Сообщение от grazer
не думаю, что по этому поводу нужно париться, если конечно отношение страниц в основном индексе и дополнительном так важно, именно как численный показатель :)- 0
- 08.05.2013 23:55Гуру
- Регистрация: 09.10.2011
- Сообщений: 1,813
- Репутация: 251
случайно удалите, а потом вопрос на форуме "почему не индексируется" зададите :) Сообщение от dmg.shark - 0




Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
Как удалить сайт из индекса поисковиков. | Вопросы от новичков | 6 | 10.10.2012 20:14 |
Как удалить страницы я яши и гугла? | Вопросы от новичков | 7 | 27.09.2012 11:57 |
Яша выкидывает страницы из индекса | Вопросы от новичков | 7 | 18.12.2011 10:10 |
Как удалить страницу из индекса? | Вопросы от новичков | 12 | 18.11.2011 13:23 |
как удалить страницы дубли??? | Вопросы от новичков | 0 | 02.10.2010 03:36 |
---------- addurl adsense avito cpa html proxy radikal woocommerce wordpress yandex youtube zennoposter аккаунт баннер блог быть вконтакт вопрос год гугл деть добавить думать есть ключ контент магазин место может накрутка нужный отзыв оффера парсер партнёрка партнёрская программа первый программа продажа продвижение прокси просто работа работать регистрация рубль сайт сервис скрипт сообщение софт ссылка стать страница тема трафик хостинг цена шаблоны
Тем:
77,590Сообщений:
763,126Пользователей:
30,080Сейчас на сайте:
1 пользователей и 148 гостей