

Источник
http://www.seocafe.info/raskrutka-v-obschih-chertah/36326-sobiraem-nch-hvost-mikro-nch-dlya-ankor-faila.html[свернуть]
Внимание, я не стану расказывать вам о продвижении под лонг-тейл. я раскажу о работе с анкор-файлом.
Как все происходит, в худшем случае? готовиться нужно к худшему. поисковая система анализирует в конкретной тематике конкретного языка вхождения в анкоры сайтов топа высокочастоток, низкочастоток и среднечастоток, таким образом, создавая некие паттерны, шаблоны для определенной тематики*языка, для определения органичности, после чего не дает прорваться в топ всем, кто слишком явно конфликтует с паттерном своим анкор-файлом.
Да, вы могли заметить, что органичность - это не то, что похоже на правду, а то, как себя ведет большинство. именно, так и есть. Вы можете возмутиться, мол, а что, если в тематике все, кто в топе, работают по черному? Ответ очевиден, - тогда в топ не выйдет тот, кто делает действительно органично
Просто, следует запомнить, что "органично" - это так, как в топе, а не так, как пишут в бложеках.
пускай анкор-файл сайта - это файл, содержащий в себе все анкоры, их количества и все лендинги, на которые они покупались. такой вот анкор-файл составляет еще и поисковик, кроме сеошника. если, вдруг, попадается сайт, чей анкор файл совсем-совсем не похож на анкор-файлы тех, кто уже в топе - он никогда не будет в топе, рядом с ними.
Да, многие это не знают, или не учитывают, но, тем не менее, попадают в топы. потому, что, чаще всего, анкор-файлы логичны. никто не будет закупать 100500 ссылок с точным вхождением одного НЧ, при этом, покупая несколько ссылок с анкорами ВЧ. Не спорю, такие методики существуют. о них я пока промолчу.
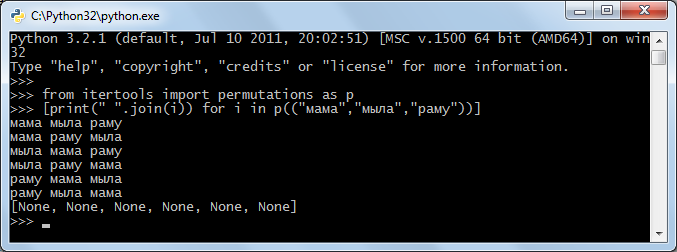
И так, теперь о составлении анкор-файла. все весьма просто. берем тот же кей-коллектор, парсим им адвордс 2м уровнем глубинного парсинга:
"наобумным" набором тематических ключей. берем результат, парсим им подсказки вордстата, набиваем список минус-слов (руцями), удаляем из общего списка все, содержащее минус-слова (коллектор умеет). дальше пишем скрипт, пример частичной реализации на питоне:
который увеличивает размер анкор-файла в несколько раз, путем дописывания в него всех комбинаций порядков слов каждой строки. дальше мы удаляем повторяющиеся строки (в том же кейколлекторе есть такая функция, и через np++ можно сделать, вот метод:
Делается это все в два клика.
1. Итак открываем ваш текстовый документ
2. Выделяем весь текст
3. Идем в меню TextFX -> TextFX Tools -> Sort lines case insensitive
При этом опция “Sort outputs only UNIQUE lines” должна быть ВКЛЮЧЕНА
Вот и все – получаем отсортированные строки без повторов и дублей.
),
проверяем частоту всех ключей в гугле. удаляем все те, точная частота которых по миру = "-". если частота сгенеренного ключа больше ноля - оставляем его. Последние действия по чистке анкор-файла делались для того, чтобы уйти от мусора. к примеру, попадется нам ключ "купить пластиковые окна в москве", у которого точная частота по миру = 590 запросов в месяц. а скрипт не умный, может нам сделать и такую картинку из этого ключа: "москве пластиковые купить окна в", у которого частота "-", полюбуйтесь:
почему мы для русскоязычных запросов юзаем гугл? гугл дает больше информации и меньше преувеличивает, так что даже для анализа московского рынка, лучше использовать гугл, если руки ровные.
Что теперь у нас есть? у нас есть список практически всех ключей тематики. полнота его уже, в любом случае, будет вызывать уважение, но, если у вас есть время и ресурсы - можете увеличивать количество итераций рекурсивного поиска и лучше работать над начальным пулом. правда, дальнейшая подобная работа неизбежно приведет к экспоненциальному росту количества мусора в анкор-файле, а, значит, - к росту количества минус-слов. Но, более того, у нас есть их частоты. сами частоты нам нужны только для того, чтобы имееть какую-то оценку степени актуальности анкоров для обывателей. зачем? чтобы ориентировочно знать, сколько ссылок на какие анкоры закупать.
Можно начать закупать ссылочное и мониторить адекватность анкор-файла. Как вы можете догадаться, мониторинг анкор-файла - это сравнение идеальной картинки анкор-файла и текущей. да, подразумевается, что у нас есть, как минимум, язл, хотя лично я предпочитаю ахрефс. Зачем мониторить адекватность реальной картины, если мы сами закупаем ссылки? да незачем, в принципе, если у вас нету достойных противников с умными сеошниками, которые будут вас валить.
Так что дальше? дальше можно закупать ссылки, в соответствии с соотношениями, заданными нашим анкор-файлом и обьективной картиной гугла (внимание! не вздумайте сейчас возмутиться и говорить, что, мол, мы по рф, нам картина гугла пофигу. не пофигу, даже если вы сами этого не осознаете. дело в том, что гугл имеет 30% рынка рф и этого достаточно, чтобы выявить процентные соотношения запросов. они не будут конфликтовать с внутренними данными яндекса, даже если будут конфликтовать с показаниями вордстата, который, если вы еще не поняли, - любит ввести в заблуждение), а можно закупать ссылки в соответствии с соотношениями конкурентов в топе. Такой выбор становится актуальным в случае, если в топе конкуренты имеют другой анкор-файл. что делать?
Вот ответ: если у вас достаточные бюджеты, чтобы двигать в этом серпе пять и больше сайтов, то делайте и двигайте как можно больше сайтов по вашей методике, таким образом, создавая паттерн для поисковика, конфликтующий с существующим паттерном, но достаточно настойчивый, чтобы его нельзя было заигнорить и забанить (если вы, конечно, не спалите, что все сайты ваши).
если таких бюджетов нету, то можете забить на показатели частотностей в вашем анкор-файле и анализируйте беки топа, что, кстати, сложнее, так как иногда поисковик подмешивает разные паттерны в одну выдачу, якобы разнообразя таким образом выдачу. следовательно, анализ конкуроты сводится к тому, чтобы определить, какие законы можно нарушать, а какие у всего топа одинаковые
- 15.10.2013 11:42
- 0
 15.10.2013 11:54
15.10.2013 11:54Прочитал. Сложилось впечатление, что автор имел в виду не сбор НЧ, как таковой, а стратегию попадания в топ выдачи ("Делай как все"). Но насколько перспективы попадания в топ перекрывают риск вылета из него вместе с другими сайтами, увлекшимися черными методами, неясно. По сбору НЧ - возможно и сработает метод (особенно в конкурентных тематиках), надо тестить. ТС, раз уж опубликовали, с Вас тест:)
- 0
- 15.10.2013 11:55Человечный Android


- Регистрация: 21.11.2011
- Сообщений: 1,111
- Репутация: 275
KK не у всех есть, да и скопировать статью дело не хитрое, а проверить...
- 0
- 15.10.2013 14:20
Поверьте, автор статьи не из пальца высосал написанное.
- 0






Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
реализовать чтение Excel файла из файла PHP | Создание сайтов | 1 | 27.08.2013 14:28 |
Требуется микро-займ. | Прочее | 5 | 16.05.2012 13:50 |
Низкочастотное продвижение или собираем длинный хвост | Дайджест блогосферы | 1 | 06.02.2011 04:35 |
Теперь и микро дайджест! | Дайджест блогосферы | 3 | 13.07.2010 13:37 |
---------- addurl admitad adsense adult avito cpa html proxy upnetwork woocommerce zennoposter аккаунт баннер бурж вконтакт вопрос год деть думать есть кейс конечный контент место может можно накрутка нужный отзыв оффера парсер партнёрка партнёрская программа пенсионный первый платир после продажа прокси просто работа работать регистрация рубль сайт сервис скрипт сообщение софт ссылка стать страница тема хороший хостинг хрумер цена шаблоны яндекс
Тем:
77,598Сообщений:
763,231Пользователей:
30,080Сейчас на сайте:
0 пользователей и 83 гостей