–ß—Ç–æ —Ç–∞–∫–æ–µ A-Parser?
–≠—Ç–æ –±—ã—Å—Ç—Ä—ã–π –ø–∞—Ä—Å–µ—Ä —Å —É–∫–ª–æ–Ω–æ–º –Ω–∞ —É–Ω–∏–≤–µ—Ä—Å–∞–ª—å–Ω–æ—Å—Ç—å, —É–¥–æ–±–Ω–æ—Å—Ç—å –∏ –ø—Ä–æ–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å.
–ù–∞ –¥–∞–Ω–Ω—ã–π –º–æ–º–µ–Ω—Ç —É–º–µ–µ—Ç –ø–∞—Ä—Å–∏—Ç—å:
–ü–æ–∏—Å–∫–æ–≤—ã–µ —Å–∏—Å—Ç–µ–º—ã
Bing
Yahoo
Yandex
QIP - –ø–∞—Ä—Å–∏–Ω–≥ —è–Ω–¥–µ–∫—Å–∞ —á–µ—Ä–µ–∑ search.qip.ru —Å –≤—ã–¥–∞—á–µ–π –¥–æ 5000 —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ —Å –æ–¥–Ω–æ–≥–æ –∑–∞–ø—Ä–æ—Å–∞
- –ü–∞—Ä—Å–µ—Ä AOL, —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω–Ω—ã–π —á–µ—Ä–µ–∑ –ø–∞—Ä—Å–µ—Ä Net::HTTP —Å –æ–ø—Ü–∏—è–º–∏ Parse custom result, Use pages –∏ –¥—Ä.
–ö–∞–∂–¥—ã–π –ø–∞—Ä—Å–µ—Ä –º–æ–∂–µ—Ç –ø–∞—Ä—Å–∏—Ç—å —Å—Å—ã–ª–∫–∏, –∞–Ω–∫–æ—Ä—ã, —Å–Ω–∏–ø–ø–µ—Ç—ã, –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —Å—Ç—Ä–∞–Ω–∏—Ü
–î–ª—è –≥—É–≥–ª–∞ —É–º–µ–µ—Ç –æ–±—Ö–æ–¥–∏—Ç—å –æ–≥—Ä–∞–Ω–∏—á–µ–Ω–∏–µ –≤ 1000 —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤(—Å–∫–æ—Ä–æ –∏ –¥–ª—è –≤—Å–µ—Ö –æ—Å—Ç–∞–ª—å–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ —Ç–∞–∫ –∂–µ –±—É–¥–µ—Ç), —Ç.–µ. –ø–æ –æ–¥–Ω–æ–º—É –∑–∞–ø—Ä–æ—Å—É —Å–æ–±–∏—Ä–∞–µ—Ç –≤—Å—é –≤—ã–¥–∞—á—É
–ü–æ–¥—Å–∫–∞–∑–∫–∏ –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º
–°–µ—Ä–≤–∏—Å—ã –ø–æ–∏—Å–∫–∞ –∫–ª—é—á–µ–≤—ã—Ö —Å–ª–æ–≤
Yandex WordStat - —Å–æ–±–∏—Ä–∞–µ—Ç –≤—Å–µ –∫–µ–π–≤–æ—Ä–¥—ã –∏ –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ –ø–æ–∫–∞–∑–æ–≤ –¥–æ —É–∫–∞–∑–∞–Ω–Ω–æ–π —Å—Ç—Ä–∞–Ω–∏—Ü—ã. –¢–∞–∫ –∂–µ —Å–æ–±–∏—Ä–∞–µ—Ç –¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω—ã–µ –∫–µ–π–≤–æ—Ä–¥—ã, –ø–æ–∫–∞–∑—ã –ø–æ –≥–ª–∞–≤–Ω–æ–º—É –∫–µ–π–≤–æ—Ä–¥—É –∏ –¥–∞—Ç—É –æ–±–Ω–æ–≤–ª–µ–Ω–∏—è —Å—Ç–∞—Ç–∏—Å—Ç–∏–∫–∏. –ú–æ–∂–µ—Ç —Å–∞–º –ø–æ–¥—Å—Ç–∞–≤–ª—è–µ—Ç –Ω–∞–π–¥–µ–Ω–Ω—ã–µ –∫–ª—é—á–µ–≤—ã–µ —Å–ª–æ–≤–∞ –≤ –∑–∞–ø—Ä–æ—Å—ã –¥–æ —É–∫–∞–∑–∞–Ω–Ω–æ–≥–æ —É—Ä–æ–≤–Ω—è.
–ü–æ–¥—Å–∫–∞–∑–∫–∏ –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º

–ü–æ–¥—Å–∫–∞–∑–∫–∏ –∏ —Ä–µ–ª–µ–π—Ç–µ–¥ –∫–µ–∏ Google
–î–ª—è –ø–æ–¥—Å–∫–∞–∑–æ–∫ –≥—É–≥–ª–∞ —É–º–µ–µ—Ç –∞–≤—Ç–æ–º–∞—Ç–∏—á–µ—Å–∫–∏ —Å–æ–±–∏—Ä–∞—Ç—å –≤—Å–µ –∫–µ–∏(–ø–æ–¥—Å—Ç–∞–Ω–æ–≤–∫–∏ –¥–æ —É–∫–∞–∑–∞–Ω–Ω–æ–≥–æ —É—Ä–æ–≤–Ω—è), –¥–ª—è –≤—Å–µ—Ö –æ—Å—Ç–∞–ª—å–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ —Ç–∞–∫–∞—è –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Å–∫–æ—Ä–æ —Ç–∞–∫ –∂–µ –ø–æ—è–≤–∏—Ç—Å—è
–ü–∞—Ä–∞–º–µ—Ç—Ä—ã —Å–∞–π—Ç–æ–≤ –∏ –¥–æ–º–µ–Ω–æ–≤
SE::Google::Position - –ø—Ä–æ–≤–µ—Ä–∫–∞ –ø–æ–∑–∏—Ü–∏–∏ –¥–æ–º–µ–Ω–∞ –ø–æ –∫–ª—é—á–µ–≤–æ–º—É —Å–ª–æ–≤—É –≤ –≥—É–≥–ª–µ
Google PageRank - PR —Å—Ç—Ä–∞–Ω–∏—Ü –∏ –¥–æ–º–µ–Ω–æ–≤
SE::Google::SafeBrowsing - –ø—Ä–æ–≤–µ—Ä–∫–∞ –¥–æ–º–µ–Ω–∞ –≤ –±–ª–µ–∫–ª–∏—Å—Ç–µ –≥—É–≥–ª–∞(–ø–æ–¥–ø–∏—Å—å harm –≤ –≤—ã–¥–∞—á–∏)
DMOZ - –Ω–∞–ª–∏—á–∏–µ —Å–∞–π—Ç–∞ –≤ –∫–∞—Ç–∞–ª–æ–≥–µ DMOZ
Google TrustRank - –ø—Ä–æ–≤–µ—Ä–∫–∞ —Å–∞–π—Ç–∞ –Ω–∞ —Ç—Ä–∞—Å—Ç –≥—É–≥–ª–∞(–¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω—ã–π –±–ª–æ–∫ —Å—Å—ã–ª–æ–∫ –≤ –≤—ã–¥–∞—á–µ –∏ —Ç.–ø.)
Whois - –¥–∞—Ç–∞ —ç–∫—Å–ø–∞–π—Ä–∞ –¥–æ–º–µ–Ω–∞
Bing LangDetect - –ø—Ä–æ–≤–µ—Ä–∫–∞ —è–∑—ã–∫–∞ –¥–æ–º–µ–Ω–∞\—Å—Å—ã–ª–∫–∏
Net::DNS - –ø–∞—Ä—Å–µ—Ä —Ä–µ–∑–æ–ª–≤–∏—Ç –¥–æ–º–µ–Ω—ã –≤ IP –∞–¥—Ä–µ—Å–∞
–ü–∞—Ä—Å–∏–Ω–≥ –∫–æ–Ω—Ç–µ–Ω—Ç–∞
HTML::LinkExtractor - –ø–∞—Ä—Å–∏—Ç –≤–Ω–µ—à–Ω–∏–µ –∏ –≤–Ω—É—Ç—Ä–µ–Ω–Ω–∏–µ —Å—Å—ã–ª–∫–∏ —Å —É–∫–∞–∑–∞–Ω–Ω–æ–≥–æ —Å–∞–π—Ç–∞, –º–æ–∂–µ—Ç —Ö–æ–¥–∏—Ç—å –ø–æ –≤–Ω—É—Ç—Ä–µ–Ω–Ω–∏–º —Å—Å—ã–ª–∫–∞–º –¥–æ –≤—ã–±—Ä–∞–Ω–Ω–æ–≥–æ —É—Ä–æ–≤–Ω—è.
Net::HTTP - —Å–∫–∞—á–∏–≤–∞–µ—Ç —É–∫–∞–∑–∞–Ω–Ω—É—é —Å—Ç—Ä–∞–Ω–∏—Ü—É, –ø–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç –º–Ω–æ–≥–æ—Å—Ç—Ä–∞–Ω–∏—á–Ω—ã–π –ø–∞—Ä—Å–∏–Ω–≥.
–ü–ª–∞–Ω–∏—Ä—É–µ—Ç—Å—è –µ—â–µ –º–Ω–æ–≥–æ –ø–∞—Ä—Å–µ—Ä–æ–≤ –≤ –±–ª–∏–∂–∞–π—à–µ–º –±—É–¥—É—â–µ–º, –≤—Å–µ —Å–æ–∑–¥–∞–Ω–Ω–æ –¥–ª—è —Ç–æ–≥–æ —á—Ç–æ–±—ã –±—ã—Å—Ç—Ä–æ –¥–æ–±–∞–≤–ª—è—Ç—å –Ω–æ–≤—ã–µ –ø–∞—Ä—Å–µ—Ä—ã.
–û–±—Ä–∞–±–æ—Ç–∫–∞ –∏ —Ñ–∏–ª—å—Ç—Ä–∞—Ü–∏—è —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤
–§–∏–ª—å—Ç—Ä–∞—Ü–∏—è –ª—é–±–æ–≥–æ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ –ø–æ –≤—Ö–æ–∂–¥–µ–Ω–∏—é —Å—Ç—Ä–æ–∫–∏, —ç–∫–≤–∏–≤–∞–ª–µ–Ω—Ç–Ω–æ—Å—Ç–∏ —Å—Ç—Ä–æ–∫, —Ä–µ–≥—É–ª—è—Ä–Ω–æ–º—É –≤—ã—Ä–∞–∂–µ–Ω–∏—é, –±–æ–ª—å—à–µ, –º–µ–Ω—å—à–µ, —Ä–∞–≤–Ω–æ –∏ —Ç.–ø.
–£–Ω–∏–∫–∞–ª–∏–∑–∞—Ü–∏—è –ª—é–±–æ–≥–æ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ –ø–æ —Å—Ç—Ä–æ–∫–µ, –¥–æ–º–µ–Ω—É, –≥–ª–∞–≤–Ω–æ–º—É –¥–æ–º–µ–Ω—É, –ø–∞–ø–∫–µ, —Å—Ç—Ä–æ–∫–µ –±–µ–∑ —É—á–µ—Ç–∞ –ø–∞—Ä–∞–º–µ—Ç—Ä–æ–≤.
–ü–∞—Ä—Å–∏–Ω–≥ –ª—é–±–æ–≥–æ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ —Å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ–º —Ä–µ–≥—É–ª—è—Ä–Ω—ã—Ö –≤—ã—Ä–∞–∂–µ–Ω–∏–π.
–ù–µ –±—ã–ª–æ –±—ã –Ω–∏–∫–∞–∫–æ–≥–æ A-Parser'–∞ –µ—Å–ª–∏ –±—ã –Ω–µ –æ–Ω –Ω–µ –∏–º–µ–ª –≤—Å–µ –Ω–∏–∂–µ–ø–µ—Ä–µ—á–∏—Å–ª–µ–Ω–Ω—ã–µ –ø—Ä–µ–∏–º—É—â–µ—Å—Ç–≤–∞, –æ—Å—Ç–∞–≤–ª—è—è –æ—Å—Ç–∞–ª—å–Ω—ã–µ –ø–∞—Ä—Å–µ—Ä—ã –¥–∞–ª–µ–∫–æ –≤ —Å—Ç–æ—Ä–æ–Ω–µ:
- –ü–æ–ª–Ω–æ—Å—Ç—å—é –∏–Ω—Ç–µ—Ä–∞–∫—Ç–∏–≤–Ω—ã–π –º–µ–≥–∞-—é–∑–∞–±–∏–ª—å–Ω—ã–π –≤–µ–± –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å
- –ë—ã—Å—Ç—Ä–æ–µ –¥–æ–±–∞–≤–ª–µ–Ω–∏–µ –∑–∞–¥–∞–Ω–∏–π - Quick Task, –∫–æ–≥–¥–∞ –Ω–µ –Ω—É–∂–Ω—ã –Ω–∏–∫–∞–∫–∏–µ –Ω–∞—Å—Ç—Ä–æ–π–∫–∏, –∞ —Ö–æ—á–µ—Ç—Å—è —Ç–æ–ª—å–∫–æ –ø–æ–±—ã—Å—Ç—Ä–æ–º—É —Å–ø–∞—Ä—Å–∏—Ç—å —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã
- –Ý–∞—Å—à–∏—Ä–µ–Ω–Ω—ã–π —Ä–µ–¥–∞–∫—Ç–æ—Ä –∑–∞–¥–∞–Ω–∏–π, –ø–æ–∑–≤–æ–ª—è–µ—Ç –∫–æ–º–±–∏–Ω–∏—Ä–æ–≤–∞—Ç—å –Ω–µ—Å–∫–æ–ª—å–∫–æ –ø–∞—Ä—Å–µ—Ä–æ–≤ –≤ –æ–¥–Ω–æ–º –∑–∞–¥–∞–Ω–∏–∏, –∫ –ø—Ä–∏–º–µ—Ä—É –º–æ–∂–Ω–æ –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω–æ –ø–∞—Ä—Å–∏—Ç—å —Å—Å—ã–ª–∫–∏ —Å–æ –≤—Å–µ—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º, –¥–µ–ª–∞—Ç—å —É–Ω–∏–∫ –ø–æ –≤—Å–µ–º —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞–º –ø—Ä—è–º–æ –≤ –ø—Ä–æ—Ü–µ—Å—Å–µ —Ä–∞–±–æ—Ç—ã –∏ —Ç.–¥.
- –û—á–µ—Ä–µ–¥—å –∑–∞–¥–∞–Ω–∏–π - —Å—Ç–∞—Ç–∏—Å—Ç–∏–∫–∞ –≤ —Ä–µ–∞–ª—å–Ω–æ–º –≤—Ä–µ–º–µ–Ω–∏, –≤—ã–ø–æ–ª–Ω–µ–Ω–∏–µ –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω–æ –Ω–µ—Å–∫–æ–ª—å–∫–∏—Ö –∑–∞–¥–∞–Ω–∏–π –∏ —Ç.–¥.
- –í—Å—Ç—Ä–æ–µ–Ω–Ω—ã–µ –ø–æ–¥—Å–∫–∞–∑–∫–∏ –¥–ª—è —ç–ª–µ–º–µ–Ω—Ç–æ–≤ —É–ø—Ä–∞–≤–ª–µ–Ω–∏—è –ø–æ–∑–≤–æ–ª—è—é—Ç –ø—Ä–æ—Å–º–∞—Ç—Ä–∏–≤–∞—Ç—å —Ö–µ–ª–ø –Ω–µ–ø–æ—Å—Ä–µ–¥—Å—Ç–≤–µ–Ω–Ω–æ –≤ –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å–µ
- –ü–æ–¥–¥–µ—Ä–∂–∫–∞ —Ä—É—Å—Å–∫–æ–≥–æ –∏ –∞–Ω–≥–ª–∏–π—Å–∫–æ–≥–æ —è–∑—ã–∫–∞
- –û–≥—Ä–æ–º–Ω–∞—è —Å–∫–æ—Ä–æ—Å—Ç—å —Ä–∞–±–æ—Ç—ã
- –ü–æ–¥–¥–µ—Ä–∂–∫–∞ –¥–≤—É—Ö —Å–∞–º—ã—Ö –ø–æ–ø—É–ª—è—Ä–Ω—ã—Ö –ø–ª–∞—Ç—Ñ–æ—Ä–º - Linux –∏ Windows, –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å –ø–æ–¥ Windows —Ñ–∞–∫—Ç–∏—á–µ—Å–∫–∏ –Ω–µ –æ—Ç–ª–∏—á–∞–µ—Ç—Å—è –æ—Ç Linux –≤–µ—Ä—Å–∏–∏
- –û—Ç–∫—Ä—ã—Ç–∞—è —Ä–∞–∑—Ä–∞–±–æ—Ç–∫–∞, –±–∞–≥—Ç—Ä–µ–∫–µ—Ä, –≤—ã—Å–ª—É—à–∏–≤–∞–Ω–∏–µ –≤—Å–µ—Ö –º–Ω–µ–Ω–∏–π –∏ –∏—Ö —Ä–µ–∞–ª–∏–∑–∞—Ü–∏—è
- –ü–µ—Ä–≤–æ–∫–ª–∞—Å—Å–Ω–∞—è —Ç–µ—Ö –ø–æ–¥–¥–µ—Ä–∂–∫–∞, –∑–Ω–∞–∫–æ–º–∞—è –º–Ω–æ–≥–∏–º –ø–æ –º–æ–µ–º—É —Å—Ç–∞—Ä–æ–º—É –ø—Ä–æ–µ–∫—Ç—É - A-Poster'—É
- –î–∞–Ω–Ω—ã–π —Å–ø–∏—Å–æ–∫ –º–æ–∂–Ω–æ –µ—â–µ –¥–æ–ª–≥–æ –ø—Ä–æ–¥–æ–ª–∂–∞—Ç—å, –≤ –±–ª–∏–∂–∞–π—à–µ–µ –≤—Ä–µ–º—è –≤—Å–µ —É–Ω–∏–∫–∞–ª—å–Ω—ã–µ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç–∏ –∏ –ø–æ–¥—Ä–æ–±–Ω–æ–µ –∏—Ö –æ–ø–∏—Å–∞–Ω–∏–µ –ø–æ—è–≤–∏—Ç—Å—è –≤ Wiki
–ë–æ–ª–µ–µ –ø–æ–¥—Ä–æ–±–Ω–æ–µ –æ–ø–∏—Å–∞–Ω–∏–µ –∏ —Å–∫—Ä–∏–Ω—à–æ—Ç—ã
Wiki - –¥–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω–∞—è –∏–Ω—Ñ–æ—Ä–º–∞—Ü–∏—è, –∏–Ω—Å—Ç—Ä—É–∫—Ü–∏–∏ –∏ —Ç.–¥.
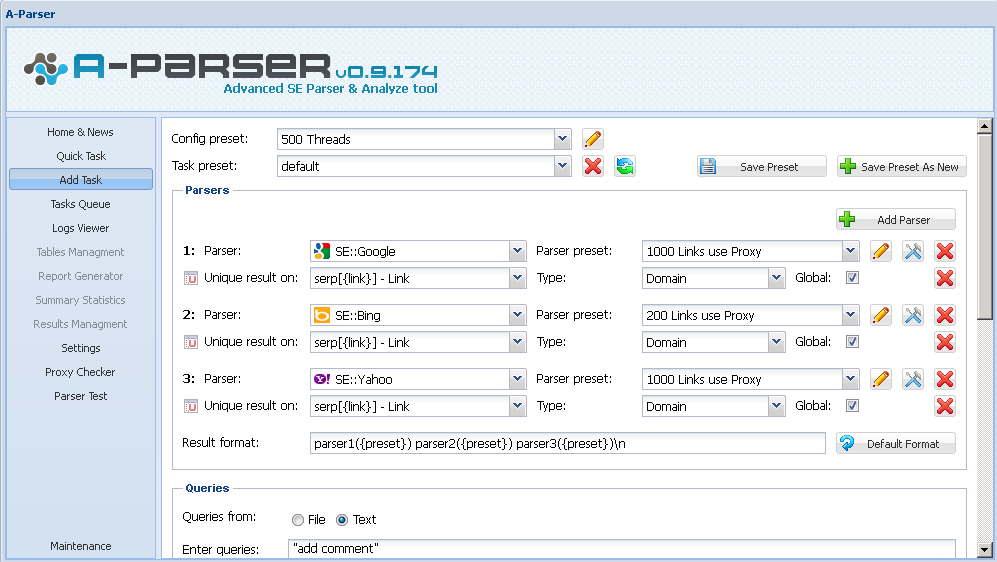
–°–∫—Ä–∏–Ω—à–æ—Ç –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å–∞:
–ù–∞ –¥–∞–Ω–Ω–æ–º —Å–∫—Ä–∏–Ω—à–æ—Ç–µ –ø–æ–∫–∞–∑–∞–Ω –ø—Ä–∏–º–µ—Ä –¥–æ–±–∞–≤–ª–µ–Ω–∏—è –∑–∞–¥–∞–Ω–∏—è –Ω–∞ –ø–∞—Ä—Å–∏–Ω–≥ –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω–æ —Ç—Ä—ë—Ö –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º - Google, Bing –∏ Yahoo, –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω—ã–π —É–Ω–∏–∫ –ø–æ –¥–æ–º–µ–Ω—É –≤—Å–µ—Ö —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤
–¶–µ–Ω–æ–≤–∞—è –ø–æ–ª–∏—Ç–∏–∫–∞
–í–Ω–∏–º–∞–Ω–∏–µ, —Ü–µ–Ω–æ–≤–∞—è –ø–æ–ª–∏—Ç–∏–∫–∞ –∏–∑–º–µ–Ω–∏–ª–∞—Å—å —Å 10.07.2012!
–¶–µ–Ω–∞ –ª–∏—Ü–µ–Ω–∑–∏–∏ - 200$, –ê–±–æ–Ω–µ–Ω—Ç—Å–∫–∞—è –ø–ª–∞—Ç–∞ - 15$ / 3 –º–µ—Å—è—Ü–∞, –ø–µ—Ä–≤—ã–π –≥–æ–¥ –±–µ–∑ –∞–±–æ–Ω–µ–Ω—Ç—Å–∫–æ–π –ø–ª–∞—Ç—ã. –£—Å–ª–æ–≤–∏—è –ø–æ –∞–±–æ–Ω–µ–Ω—Ç—Å–∫–æ–π –ø–ª–∞—Ç–µ —Ç–∞–∫ –∂–µ —Ä–∞—Å–ø—Ä–æ—Å—Ç—Ä–∞–Ω—è—é—Ç—Å—è –∏ –Ω–∞ —Å—É—â–µ—Å—Ç–≤—É—é—â–∏—Ö –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π!
–ê —Ç–∞–∫ –∂–µ —Å–ø–µ—Ü –ø—Ä–µ–¥–ª–æ–∂–µ–Ω–∏–µ - –≤—Å–µ–º –∫–ª–∏–µ–Ω—Ç–∞–º A-Parser'–∞ –±–µ—Å–ø–ª–∞—Ç–Ω–æ –ø—Ä–∏–≤–∞—Ç–Ω—ã–µ –ø—Ä–æ–∫—Å–∏ –Ω–∞ 20 –ø–æ—Ç–æ–∫–æ–≤ –Ω–∞ 2 –Ω–µ–¥–µ–ª–∏!
–í—Å–µ–º –∫–ª–∏–µ–Ω—Ç–∞–º –∫—Ç–æ –∏–º–µ–µ—Ç –ª–∏—Ü–µ–Ω–∑–∏—é –Ω–∞ A-Poster - —Ü–µ–Ω–∞ –≤—Å–µ–≥–æ 150$
–ê —Ç–∞–∫ –∂–µ A-Parser + A-Poster –≤—Å–µ–≥–æ –∑–∞ 300$!
–õ–∏—Ü–µ–Ω–∑–∏—è –ø–æ–∑–≤–æ–ª—è–µ—Ç –∑–∞–ø—É—Å–∫–∞—Ç—å A-Parser –Ω–∞ –æ–¥–Ω–æ–º —Å–µ—Ä–≤–µ—Ä–µ\–∫–æ–º–ø—å—é—Ç–µ—Ä–µ. –ü–µ—Ä–µ–Ω–æ—Å–∏—Ç—å –º–æ–∂–Ω–æ –±–µ—Å–ø–ª–∞—Ç–Ω–æ, –Ω–µ–ª—å–∑—è –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω–æ –Ω–∞ –Ω–µ—Å–∫–æ–ª—å–∫–∏—Ö –∑–∞–ø—É—Å–∫–∞—Ç—å.
A-Parser - –ø—Ä–æ–¥–≤–∏–Ω—É—Ç—ã–π –ø–∞—Ä—Å–µ—Ä –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(–û—Ç–≤–µ—Ç–æ–≤: 339, –ü—Ä–æ—Å–º–æ—Ç—Ä–æ–≤: 47976)
- 11.07.2012 20:26–û–ø—ã—Ç–Ω—ã–π



- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–ü–æ—Å–ª–µ–¥–Ω–∏–π —Ä–∞–∑ —Ä–µ–¥–∞–∫—Ç–∏—Ä–æ–≤–∞–ª–æ—Å—å oleg_ug; 12.07.2012 –≤ 12:56. –ü—Ä–∏—á–∏–Ω–∞: –∫—Ä–∞—Å–Ω—ã–º –ø–∏—Å–∞—Ç—å –Ω–µ–ª—å–∑—è
- 1
–°–ø–∞—Å–∏–±–æ —Å–∫–∞–∑–∞–ª–∏:
SlarkStudio(07.12.2013), - 16.07.2012 13:23–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.69
–ù–æ–≤—ã–π –ø–∞—Ä—Å–µ—ÄSE::Yandex::TIC - –ø—Ä–æ–≤–µ—Ä–∫–∞ –∏–Ω–¥–µ–∫—Å–∞ —Ü–∏—Ç–∏—Ä–æ–≤–∞–Ω–∏—è –¥–æ–º–µ–Ω–∞, –∞ —Ç–∞–∫ –∂–µ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–µ –≤—ã–¥–∞—á–∏ –Ø–Ω–¥–µ–∫—Å WordStat –∏ Bing, –ø–æ–¥—Ä–æ–±–Ω–µ–µ —Ç—É—Ç
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #192: Fix Members Area work with https
–û—à–∏–±–∫–∞ #193: Fix SE::Yandex::WordStat russian html entities
–û—à–∏–±–∫–∞ #194: Fix SE::Bing for parsing 10+ results and fix links regex
–û—à–∏–±–∫–∞ #195: Fix UTF-8 for restore unique from file
–£–ª—É—á—à–µ–Ω–∏–µ #196: Add Yandex TIC parser - SE::Yandex::TIC- 0
- 08.08.2012 13:49–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.166
–ë–æ–ª—å—à–æ–µ –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–π, –¥–æ–≤–æ–¥–∏–º –ø–∞—Ä—Å–µ—Ä –¥–æ –∏–¥–µ–∞–ª—å–Ω–æ–≥–æ —Å–æ—Å—Ç–æ—è–Ω–∏—è!
–ê —Ç–∞–∫ –∂–µ –ø–ª–∞–Ω–æ–≤—ã–µ —Ñ–∏–∫—Å—ã –≤ —Å–≤—è–∑–∏ —Å –∏–∑–º–µ–Ω–µ–Ω–∏–µ–º –≤—ã–¥–∞—á–∏ –¥–ª—è SE::Google –∏ SE::Yandex.
–í —Å–ª–µ–¥—É—é—â–∏—Ö –≤–µ—Ä—Å–∏—è—Ö –æ–∂–∏–¥–∞–µ—Ç—Å—è –Ω–æ–≤—ã–π HTTP –¥–≤–∏–∂–æ–∫, –∫–æ—Ç–æ—Ä—ã–π –Ω–µ –ø–æ–ø–∞–ª –≤ —Ç–µ–∫—É—â—É—é –≤–µ—Ä—Å–∏—é –≤ —Å–≤—è–∑–∏ —Å –ø—Ä–æ–¥–æ–ª–∂–∏—Ç–µ–ª—å–Ω—ã–º —Ç–µ—Å—Ç–∏—Ä–æ–≤–∞–Ω–∏–µ–º.
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #163: Some bug in proxycheker
–û—à–∏–±–∫–∞ #197: Fix not save results after stop\pause + start
–û—à–∏–±–∫–∞ #198: Fix encoding for non-english for Google, Bing and Yahoo parsers
–û—à–∏–±–∫–∞ #199: Fix non-english queries parsing with SE::Yahoo
–û—à–∏–±–∫–∞ #201: Fix Google snippets regex
–û—à–∏–±–∫–∞ #202: Fix parse custom results with arrays -> server crash
–û—à–∏–±–∫–∞ #204: Fix SE::Yandex next page regex
–û—à–∏–±–∫–∞ #210: Fix crash on end of file when file used as iterator
–£–ª—É—á—à–µ–Ω–∏–µ #206: Add gzip support for SE::Yandex::TIC
–£–ª—É—á—à–µ–Ω–∏–µ #207: UTF-8 auto detect for HTML::LinkExtractor
–£–ª—É—á—à–µ–Ω–∏–µ #209: Add gzip support for SE::Google- 0
- 17.08.2012 13:03–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.182
–û—á–µ–Ω—å –≤–∞–∂–Ω—ã–µ –∏–∑–º–µ–Ω–µ–Ω–∏—è:
- –ù–æ–≤—ã–π –±–æ–ª–µ–µ –±—ã—Å—Ç—Ä—ã–π HTTP –¥–≤–∏–∂–æ–∫
- –£–º–µ–Ω—å—à–µ–Ω–∏–µ –ø–æ—Ç—Ä–µ–±–ª–µ–Ω–∏—è –ø–∞–º—è—Ç–∏
- –û–±—â–µ–µ —É–≤–µ–ª–∏—á–µ–Ω–∏–µ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç–∏ –∑–∞ —Å—á–µ—Ç –≤–Ω—É—Ç—Ä–µ–Ω–Ω–∏—Ö –æ–ø—Ç–∏–º–∏–∑–∞—Ü–∏–π
–£–ª—É—á—à–µ–Ω–∏—è:
- HTML::LinkExtractor: –Ω–æ–≤—ã–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã {cleananchor} - –∞–Ω–∫–æ—Ä –±–µ–∑ html –∫–æ–¥–∞, –∏ {nofollow} - –æ–ø—Ä–µ–¥–µ–ª—è–µ—Ç –µ—Å—Ç—å –ª–∏ nofollow –ø–∞—Ä–∞–º–µ—Ç—Ä
- HTML::LinkExtractor: –æ–ø—Ü–∏—è Subdomains are internal - —Å—á–∏—Ç–∞–µ—Ç —Å—Å—ã–ª–∫–∏ —Å–æ –≤—Å–µ—Ö —Å–∞–±–¥–æ–º–µ–Ω–Ω–æ–≤ –∫–∞–∫ –≤–Ω—É—Ç—Ä–µ–Ω–∏–µ
- –ú–∞–∫—Ä–æ—Å {queriesfile} –≤ Results -> File name - –ø–æ–¥—Å—Ç–∞–≤–ª—è–µ—Ç –Ω–∞–∑–≤–∞–Ω–∏–µ —Ñ–∞–π–ª–∞ —Å –∑–∞–ø—Ä–æ—Å–∞–º–∏
–ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∏—è:
- –ü–æ–ø—Ä–∞–≤–ª–µ–Ω –ø–∞—Ä—Å–µ—Ä SE::Google –≤ —Å–≤—è–∑–∏ —Å –∏–∑–º–µ–Ω–µ–Ω–∏–µ–º —Ñ–æ—Ä–º–∞—Ç–∞ –≤—ã–¥–∞—á–∏
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #211: Fix SE::Google results count regex
–û—à–∏–±–∫–∞ #212: Fix SE::Google snippets regex
–û—à–∏–±–∫–∞ #217: Delete tasks with iterator's from completed queue after parser restarting
–£–ª—É—á—à–µ–Ω–∏–µ #200: New fast HTTP engine
–£–ª—É—á—à–µ–Ω–∏–µ #205: Reduce memory usage by using new http engine
–£–ª—É—á—à–µ–Ω–∏–µ #213: Add posibility to use {query} inside arrays in Results format
–£–ª—É—á—à–µ–Ω–∏–µ #214: Add {cleananchor} and {nofollow} to results in HTML::LinkExtractor
–£–ª—É—á—à–µ–Ω–∏–µ #215: –ù–∞–∑–≤–∞–Ω–∏–µ –∏—Å—Ö–æ–¥–Ω–æ–≥–æ —Ñ–∞–π–ª–∞ –≤ results (New macros {queriesfile} in results file name)
–£–ª—É—á—à–µ–Ω–∏–µ #219: Add 'Subdomains are internal' option for HTML::LinkExtractor
–£–ª—É—á—à–µ–Ω–∏–µ #221: Many internal perfomance improvement and optimizations- 0
- 27.08.2012 13:03–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–û—Ç–∫—Ä—ã–ª–∞—Å—å –ø–∞—Ä—Ç–Ω–µ—Ä—Å–∫–∞—è –ø—Ä–æ–≥—Ä–∞–º–º–∞ –ø–æ –ø—Ä–æ–¥–∞–∂–µ A-Parser'a - 50$ —Å –∫–∞–∂–¥–æ–≥–æ –ø—Ä–∏–≤–µ–¥–µ–Ω–Ω–æ–≥–æ –∫–ª–∏–µ–Ω—Ç–∞. –ü–æ–¥—Ä–æ–±–Ω–µ–µ –Ω–∞ —Å–∞–π—Ç–µ –ø–∞—Ä—Å–µ—Ä–∞.
–Ý–µ–≥–∏—Å—Ç—Ä–∏—Ä—É–π—Ç–µ—Å—å –∏ —Å–≤—è–∂–∏—Ç–µ—Å—å —Å–æ –º–Ω–æ–π –¥–ª—è –∞–∫—Ç–∏–≤–∞—Ü–∏–∏ –∞–∫–∫–∞—É–Ω—Ç–∞.
–ü–æ–º–∏–º–æ ICQ 777889 —Ç–µ–ø–µ—Ä—å —Å–æ –º–Ω–æ–π –º–æ–∂–Ω–æ —Å–≤—è–∑–∞—Ç—å—Å—è —á–µ—Ä–µ–∑ jabber/gtalk forbidden2k@gmail.com- 0
- 31.08.2012 13:02–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.194
–ù–æ–≤—ã–µ –ø–∞—Ä—Å–µ—Ä—ã:-
SE::Yandex::Direct - –ø–∞—Ä—Å–µ—Ä direct.yandex.ru, –ø–∞—Ä—Å–∏—Ç —Å–ø–∏—Å–æ–∫ –≤—Å–µ—Ö –æ–±—ä—è–≤–ª–µ–Ω–∏–π(—Ç–∏—Ç–ª, —Ç–µ–∫—Å—Ç, –¥–æ–º–µ–Ω) –∏ –∫–æ–ª-–≤–æ –æ–±—ä—è–≤–ª–µ–Ω–∏–π –ø–æ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω–æ–º—É –∑–∞–ø—Ä–æ—Å—É
-
SE::Google::Images - –ø–∞—Ä—Å–µ—Ä Google Images, –ø–∞—Ä—Å–∏—Ç –ø—Ä—è–º—ã–µ —Å—Å—ã–ª–∫–∏ –Ω–∞ –∫–∞—Ä—Ç–∏–Ω–∫–∏, —Å–Ω–∏–ø–ø–µ—Ç—ã, —Ä–∞–∑—Ä–µ—à–µ–Ω–∏–µ –∏ —Ä–∞–∑–º–µ—Ä
–ù–æ–≤—ã–µ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç–∏:- –û–ø—Ü–∏—è, –ø–æ–∑–≤–æ–ª—è—é—â–∞—è –ø–∞—Ä—Å–∏—Ç—å —Ä–∞–∑–Ω—ã–µ –∑–∞–¥–∞–Ω–∏—è –∏—Å–ø–æ–ª—å–∑—É—é –æ–¥–Ω—É –±–∞–∑—É –¥–ª—è —É–Ω–∏–∫–∞–ª–∏–∑–∞—Ü–∏–∏, —Ç.–µ. —Ç–µ–ø–µ—Ä—å –º–æ–∂–Ω–æ –ø—Ä–∏ –ø–æ—è–≤–ª–µ–Ω–∏–∏ –Ω–æ–≤—ã—Ö –ø—Ä–∏–∑–Ω–∞–∫–æ–≤ —Ç–æ–π –∂–µ –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ –¥–æ–ø–∞—Ä—Å–∏—Ç—å —Ç–æ–ª—å–∫–æ –Ω–æ–≤—ã–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã –≤ —Å—Ç–∞—Ä—É—é –±–∞–∑—É
- –í–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∑–∞–ª–æ–≥–∏–Ω–∏—Ç—å—Å—è –≤ 2+ –ø–∞—Ä—Å–µ—Ä–∞ –≤ –æ–¥–Ω–æ–º –±—Ä–∞—É–∑–µ—Ä–µ
–í—Å–µ–≥–æ 12 —É–ª—É—á—à–µ–Ω–∏–π –∏ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–π
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #222: Fix iterator cleanup when set any error
–û—à–∏–±–∫–∞ #223: Fix work end when string with zero used in queries/subs files
–û—à–∏–±–∫–∞ #225: Fix server crash when use Unique queries + iterators + pause start
–û—à–∏–±–∫–∞ #228: Fix max size handling in http engine
–û—à–∏–±–∫–∞ #232: Fix pages count on active queue tab
–£–ª—É—á—à–µ–Ω–∏–µ #161: Add option for check existing results file for unique before task start(implemented with Keep Unique option)
–£–ª—É—á—à–µ–Ω–∏–µ #165: Show old results count when server restart
–£–ª—É—á—à–µ–Ω–∏–µ #224: New parser SE::Google::Images - parsing full urls to images, with snippets, width, height and size information
–£–ª—É—á—à–µ–Ω–∏–µ #226: New parser SE::Yandex::Direct - direct.yandex.ru parser with total ads count and all ads list(domain, title, text)
–£–ª—É—á—à–µ–Ω–∏–µ #227: Allow login to 2+ A-Parser's on same ip/domain
–£–ª—É—á—à–µ–Ω–∏–µ #230: Check unique level when restore tasks
–£–ª—É—á—à–µ–Ω–∏–µ #231: Disable editing default presets- 0
- 10.09.2012 13:15–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.200
–ù–æ–≤—ã–µ –ø–∞—Ä—Å–µ—Ä—ã:-
Rank::Ahrefs - –ø–∞—Ä—Å–µ—Ä –∫–æ–ª–∏—á–µ—Å—Ç–≤–∞ –±–µ–∫–ª–∏–Ω–∫–æ–≤ —Å —Å–µ—Ä–≤–∏—Å–∞ ahrefs.com, –ø–∞—Ä—Å–∏—Ç –æ–±—â–µ–µ —á–∏—Å–ª–æ –±–µ–∫–ª–∏–Ω–∫–æ–≤, –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —Å—Å—ã–ª–∞—é—â–∏—Ö—Å—è —Å—Ç—Ä–∞–Ω–∏—Ü, –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —É–Ω–∏–∫–∞–ª—å–Ω—ã—Ö IP-–∞–¥—Ä–µ—Å–æ–≤, –ø–æ–¥—Å–µ—Ç–µ–π –∫–ª–∞—Å—Å–∞ C –∏ –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —É–Ω–∏–∫–∞–ª—å–Ω—ã—Ö –¥–æ–º–µ–Ω–æ–≤
-
SE::Bing::Translator - –ø–µ—Ä–µ–≤–æ–¥—á–∏–∫ —á–µ—Ä–µ–∑ —Å–µ—Ä–≤–∏—Å www.bing.com/translator/, –ø–æ–¥–¥–µ—Ä–∂–∏–≤–∞–µ—Ç –≤—Å–µ —è–∑—ã–∫–∏ —Å–µ—Ä–≤–∏—Å–∞, –≤–∫–ª—é—á–∞—è –∞–≤—Ç–æ–æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ —è–∑—ã–∫–∞ –æ—Ä–∏–≥–∏–Ω–∞–ª–∞ —Ç–µ–∫—Å—Ç–∞
-
Rank::Category - –∞–≤—Ç–æ–º–∞—Ç–∏—á–µ—Å–∫–∏ –æ–ø—Ä–µ–¥–µ–ª—è–µ—Ç –∫–∞—Ç–µ–≥–æ—Ä–∏—é —Å–∞–π—Ç–∞ –Ω–∞ –∞–Ω–≥–ª–∏–π—Å–∫–æ–º —è–∑—ã–∫–µ, –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ —Ç–∞–∫–∏–µ –∂–µ –∫–∞–∫ –≤ dmoz.org, –Ω–∞–ø—Ä–∏–º–µ—Ä google.com - Computers/Internet/Searching
–ù–æ–≤—ã–µ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç–∏:- –î–æ–ø–æ–ª–Ω–∏—Ç–µ–ª—å–Ω—ã–µ –æ–ø—Ü–∏–∏ –ø–æ —Å–æ—Ö—Ä–∞–Ω–µ–Ω–∏—é —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ - –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –¥–æ–±–∞–≤–∏—Ç—å –ø—Ä–æ–∏–∑–≤–æ–ª—å–Ω—ã–π —Ç–µ–∫—Å—Ç –≤ –Ω–∞—á–∞–ª–æ –∏ –∫–æ–Ω–µ—Ü —Ñ–∞–π–ª–∞ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞, –º–æ–∂–µ—Ç –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è –∫ –ø—Ä–∏–º–µ—Ä—É –¥–ª—è –æ–±–æ–∑–Ω–∞—á–µ–Ω–∏—è –Ω–∞–∑–≤–∞–Ω–∏–π –∫–æ–ª–æ–Ω–æ–∫ –ø—Ä–∏ —Ñ–æ—Ä–º–∏—Ä–æ–≤–∞–Ω–∏–∏ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞ –≤ csv –≤–∏–¥–µ
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #236: Fix active slot counting when server restart
–£–ª—É—á—à–µ–Ω–∏–µ #234: Re-enable https with old http engine
–£–ª—É—á—à–µ–Ω–∏–µ #235: New parser Rank::Ahrefs - ahrefs.com parser (backlinks/pages/ips/subnets/domains count)
–£–ª—É—á—à–µ–Ω–∏–µ #237: –û–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ —Ç–µ–º–∞—Ç–∏–∫–∏ —Å–∞–π—Ç–∞
–£–ª—É—á—à–µ–Ω–∏–µ #238: Limit queries field length to 8192 characters
–£–ª—É—á—à–µ–Ω–∏–µ #239: More options in add task: prepend and append text in results file(e.g. for cols names)
–£–ª—É—á—à–µ–Ω–∏–µ #241: SE::Bing::Translator - translator between any 2 languages, with auto-detect- 1
–°–ø–∞—Å–∏–±–æ —Å–∫–∞–∑–∞–ª–∏:
evol22(13.09.2012), - 13.09.2012 20:40–ù–æ–≤–∏—á–æ–∫
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 04.07.2011
- –°–æ–æ–±—â–µ–Ω–∏–π: 12
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 3
- Webmoney BL:
 ?
?
–ü—Ä–∏–æ–±—Ä–µ–ª –¥–∞–Ω–Ω–æ–µ —Ç–≤–æ—Ä–µ–Ω–∏–µ. –°–∫–æ—Ä–æ—Å—Ç—å, –∫–∞—á–µ—Å—Ç–≤–æ, —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã –ø—Ä–æ—Å—Ç–æ —Ñ–∞–Ω—Ç–∞—Å—Ç–∏–∫–∞. –Ý–µ–∞–ª—å–Ω–æ –æ—á–µ–Ω—å –≤—ã—Ä—É—á–∞–µ—Ç –∏ –ø–æ–º–æ–≥–∞–µ—Ç. –ï—Å–ª–∏ –í—ã –∏—â–∏—Ç–µ –ø–∞—Ä—Å–µ—Ä - –ª—É—á—à–µ –Ω–µ –Ω–∞–π—Ç–∏. –î–∞ –∏ –∞–≤—Ç–æ—Ä –ø–æ—Å—Ç–æ—è–Ω–Ω–æ –≤ —Å–µ—Ç–∏, –ø–æ–¥–¥–µ—Ä–∂–∫—É –æ—Å—É—â–µ—Å—Ç–≤–ª—è–µ—Ç. –ü–æ—Ç—Ä–µ–±–æ–≤–∞–ª–æ—Å—å –Ω–µ–º–Ω–æ–≥–æ –¥–æ—Ä–∞–±–æ—Ç–∞—Ç—å —Ñ—É–Ω–∫—Ü–∏–æ–Ω–∞–ª - –≤ —Ç–µ—á–µ–Ω–∏–∏ –ø–∞—Ä—É —á–∞—Å–æ–≤ –ø–æ–ª—É—á–∏–ª –≤—Å–µ –º–Ω–µ –Ω–µ–æ–±—Ö–æ–¥–∏–º–æ–µ. –ö –ø–æ–∫—É–ø–∫–µ —Ä–µ–∫–æ–º–µ–Ω–¥—É—é!!!
- 0
- 19.09.2012 14:13–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.209
–ù–æ–≤—ã–π –ø–∞—Ä—Å–µ—Ä Rank::CMS - –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ –±–æ–ª–µ–µ 200 –≤–∏–¥–æ–≤ CMS –Ω–∞ –æ—Å–Ω–æ–≤–µ –ø—Ä–∏–∑–Ω–∞–∫–æ–≤. –û–ø—Ä–µ–¥–µ–ª—è–µ—Ç –≤—Å–µ –ø–æ–ø—É–ª—è—Ä–Ω—ã–µ —Ñ–æ—Ä—É–º—ã, –±–ª–æ–≥–∏, CMS, –≥–µ—Å—Ç–±—É–∫–∏, –≤–∏–∫–∏ –∏ –º–Ω–æ–∂–µ—Å—Ç–≤–æ –¥—Ä—É–≥–∏—Ö —Ç–∏–ø–æ–≤ –¥–≤–∏–∂–∫–æ–≤.
Rank::CMS - –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ –±–æ–ª–µ–µ 200 –≤–∏–¥–æ–≤ CMS –Ω–∞ –æ—Å–Ω–æ–≤–µ –ø—Ä–∏–∑–Ω–∞–∫–æ–≤. –û–ø—Ä–µ–¥–µ–ª—è–µ—Ç –≤—Å–µ –ø–æ–ø—É–ª—è—Ä–Ω—ã–µ —Ñ–æ—Ä—É–º—ã, –±–ª–æ–≥–∏, CMS, –≥–µ—Å—Ç–±—É–∫–∏, –≤–∏–∫–∏ –∏ –º–Ω–æ–∂–µ—Å—Ç–≤–æ –¥—Ä—É–≥–∏—Ö —Ç–∏–ø–æ–≤ –¥–≤–∏–∂–∫–æ–≤.
–ü–æ—è–≤–∏–ª–∞—Å—å –≤–µ—Ä—Å–∏—è —Å User API, —Ç–µ–ø–µ—Ä—å –º–æ–∂–Ω–æ –∏–Ω—Ç–µ–≥—Ä–∏—Ä–æ–≤–∞—Ç—å A-Parser –≤ —Å–≤–æ–∏ —Å–∫—Ä–∏–ø—Ç—ã –∏ –ø—Ä–æ–≥—Ä–∞–º–º—ã, –±–æ–ª–µ–µ –ø–æ–¥—Ä–æ–±–Ω–æ –ø—Ä–æ API –æ–ø–∏—Å–∞–Ω–æ —Ç—É—Ç: User API, –≤–∑–∞–∏–º–æ–¥–µ–π—Å—Ç–≤–∏–µ —Å –¥—Ä—É–≥–∏–º–∏ –ø—Ä–æ–≥—Ä–∞–º–º–∞–º–∏ –∏ —Å–∫—Ä–∏–ø—Ç–∞–º–∏
–ò—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–∞—Ä—Å–µ—Ä
–û–±—â–µ–µ –ø–æ–≤—ã—à–µ–Ω–∏–µ —Å—Ç–∞–±–∏–ª—å–Ω–æ—Å—Ç–∏, —É–ª—É—á—à–µ–Ω–∏–µ –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å–∞ –∏ –¥—Ä—É–≥–∏–µ —Ñ–∏–∫—Å—ã.
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #157: Bug when use non-english presets name
–û—à–∏–±–∫–∞ #229: Need to auto-flush unique file because it may corrupt if process kill
–û—à–∏–±–∫–∞ #242: Fix server crash after restarting task with iterator error
–û—à–∏–±–∫–∞ #244: HTML::LinkExtractor fail with relative links starting with dot-shlash
–û—à–∏–±–∫–∞ #245: Query format fail for subqueries when use iterator + parse to level option
–û—à–∏–±–∫–∞ #247: Fix utf-8 check for subqueries files
–û—à–∏–±–∫–∞ #255: Fix SE::Yandex: gzip and next page regex
–£–ª—É—á—à–µ–Ω–∏–µ #243: Disable editing all fixed combobox
–£–ª—É—á—à–µ–Ω–∏–µ #246: Need to reload presets combobox's when adding/deleting presets
–£–ª—É—á—à–µ–Ω–∏–µ #251: New parser Rank::CMS - auto detect CMS type
–£–ª—É—á—à–µ–Ω–∏–µ #252: Implement User Api: ping and oneRequest(parser, preset, query)
–£–ª—É—á—à–µ–Ω–∏–µ #253: Fast proxy delivery for new threads- 0
- 28.09.2012 13:16–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 308
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–µ—Ä—Å–∏—è 0.9.220
–£–ª—É—á—à–µ–Ω–∏—è- –í –ø–∞—Ä—Å–µ—Ä
- –î–ª—è –ø–∞—Ä—Å–µ—Ä–∞
- –¢–µ–ø–µ—Ä—å –ø—Ä–∏ —ç–∫—Å–ø–æ—Ä—Ç–µ –ø—Ä–µ—Å–µ—Ç–∞ —Å–æ—Ö—Ä–∞–Ω—è—é—Ç—Å—è –≤—Å–µ –∑–Ω–∞—á–∏–º—ã–µ –Ω–∞—Å—Ç—Ä–æ–π–∫–∏(–∫—Ä–æ–º–µ —Å–∞–º–∏—Ö –∑–∞–ø—Ä–æ—Å–æ–≤).
–ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∏—è- –í —ç—Ç–æ–π –≤–µ—Ä—Å–∏–∏ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ —Å —É—Ç–µ—á–∫–æ–π —Å–æ–∫–µ—Ç–æ–≤ –ø—Ä–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–∏ SOCKS –ø—Ä–æ–∫—Å–∏, –∞ —Ç–∞–∫ –∂–µ –Ω–µ—Å–∫–æ–ª—å–∫–æ –¥—Ä—É–≥–∏—Ö –æ—à–∏–±–æ–∫ –≤–ª–∏—è—é—â–∏—Ö –Ω–∞ –æ–±—â—É—é —Å—Ç–∞–±–∏–ª—å–Ω–æ—Å—Ç—å –ø–∞—Ä—Å–µ—Ä–∞.
–°–≤—è–∑–∞–Ω–Ω—ã–µ –∑–∞–¥–∞—á–∏:–û—à–∏–±–∫–∞ #260: Fix SE::Yahoo regex(loop)
–û—à–∏–±–∫–∞ #262: Fix wrong proxy ban when malformed url used(status == 595)
–û—à–∏–±–∫–∞ #265: Fix sockets leak when use socks proxies in new http engine(important!)
–û—à–∏–±–∫–∞ #267: Fix warnings when fast stop parser test
–û—à–∏–±–∫–∞ #268: Fix handling cookie expire date(for too big date or unparsable date automatic set expire to now + 1 year)
–£–ª—É—á—à–µ–Ω–∏–µ #256: Add option for SE::Google for check not found resutls
–£–ª—É—á—à–µ–Ω–∏–µ #257: Convert to numeric results count for SE::Yandex
–£–ª—É—á—à–µ–Ω–∏–µ #258: Add more options to import/export presets
–£–ª—É—á—à–µ–Ω–∏–µ #263: –ó–æ–Ω—ã –ø–∞—Ä—Å–∏–Ω–≥–∞ Yandex (option Yandex domain allow select yandex.ua)
–£–ª—É—á—à–µ–Ω–∏–µ #264: Show warning for too many subrequests- 0


–¢—ç–≥–∏ —Ç–æ–ø–∏–∫–∞:
- a-parser,
- bing,
- dmoz,
- dns,
- google,
- harm,
- html,
- ip,
- linkextractor,
- nofollow,
- parser,
- parsers,
- qip,
- suggest,
- whois,
- wordstat,
- yahoo,
- yandex,
- –≤–µ—Ä—Å–∏—è,
- –≥—É–≥–ª,
- –¥–æ–º–µ–Ω,
- –∏–∑–º–µ–Ω–µ–Ω–∏–µ,
- –∫–µ–π–≤–æ—Ä–¥—ã,
- –∫–ª—é—á–µ–≤—ã–µ —Å–ª–æ–≤–∞,
- –Ω–æ–≤—ã–π,
- –ø–∞—Ä—Å–µ—Ä,
- –ø–æ–¥—Å–∫–∞–∑–∫–∏,
- –ø–æ–∏—Å–∫–æ–≤—ã–π,
- –ø—Ä–æ–¥–≤–∏–Ω—É—Ç—å,
- —Ä–µ–∑—É–ª—å—Ç–∞—Ç,
- —Å–≤—è–∑—å,
- —Å–∏—Å—Ç–µ–º–∞,
- —è–Ω–¥–µ–∫—Å
–ü–æ—Ö–æ–∂–∏–µ —Ç–µ–º—ã
| –¢–µ–º—ã | –Ý–∞–∑–¥–µ–ª | –û—Ç–≤–µ—Ç–æ–≤ | –ü–æ—Å–ª–µ–¥–Ω–∏–π –ø–æ—Å—Ç |
|---|---|---|---|
LTK Parser - –ø–∞—Ä—Å–µ—Ä –ø–æ–∏—Å–∫–æ–≤—ã—Ö –ø–æ–¥—Å–∫–∞–∑–æ–∫ –Ω–∞ —Ä–∞–∑–Ω—ã—Ö —è–∑—ã–∫–∞—Ö | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, –ª–∏—Ü–µ–Ω–∑–∏–∏ | 12 | 06.05.2012 21:10 |
–ü–∞—Ä—Å–µ—Ä –∫–æ–Ω—Ç–µ–Ω—Ç–∞ –ø–æ–¥ –¥–æ—Ä–≤–µ–∏ –∏ —Å–∞—Ç–µ–ª–ª–∏—Ç—ã X-Parser | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, —Å–µ—Ä–≤–∏—Å—ã | 0 | 15.08.2010 23:51 |
KD Parser - –ø–∞—Ä—Å–µ—Ä –∫–ª—é—á–µ–≤—ã—Ö —Å–ª–æ–≤ | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, –ª–∏—Ü–µ–Ω–∑–∏–∏ | 2 | 10.04.2010 21:47 |
–•–æ—Ä–æ—à–∏–π –ü–∞—Ä—Å–µ—Ä –Ø.–î–∏—Ä–µ–∫—Ç –∏ Wordstat - –ú–∞–≥–∞–¥–∞–Ω | –ü–æ–∏—Å–∫–æ–≤—ã–µ —Å–∏—Å—Ç–µ–º—ã | 10 | 24.11.2009 16:52 |
–•–æ—Ä–æ—à–∏–π –ü–∞—Ä—Å–µ—Ä –Ø.–î–∏—Ä–µ–∫—Ç –∏ Wordstat - –ú–∞–≥–∞–¥–∞–Ω | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, —Å–µ—Ä–≤–∏—Å—ã | 4 | 15.09.2009 19:38 |
---------- admitad adsense adult avito cpa direct dragon-soul m-analytics parser proxy romanov-crowd woocommerce zennoposter –∞–Ω–æ–Ω–∏–º–Ω—ã–π –±–∞–Ω–Ω–µ—Ä –≤–µ—Ä—Å—Ç–∫–∞ –≤–∫–æ–Ω—Ç–∞–∫—Ç –≤–æ–∑–º–æ–∂–Ω—ã–π –≤—Ä–µ–º–µ–Ω–∏—Ç—å –≥–æ–¥ –≥—Ä–∞–±–±–µ—Ä –≥—Ä—É–ø–ø–∞ –¥–µ—Ç—å –¥—É–º–∞—Ç—å –µ—Å—Ç—å –∑–∞–∫–∞–∑—á–∏–∫ –∏–Ω—Ç–µ—Ä–Ω–µ—Ç –∫–µ–π—Å –∫–æ–Ω—Ç–µ–∫—Å—Ç–Ω—ã–π –∫–æ–Ω—Ç–µ–Ω—Ç –º–µ—Å—Ç–æ –º–æ–∂–µ—Ç –º–æ–∂–Ω–æ –Ω–∞–∫—Ä—É—Ç–∫–∞ –æ—Ç–∑—ã–≤ –æ—á–µ–Ω—å –ø–∞—Ä—Å–∏–Ω–≥ –ø–µ–Ω—Å–∏–æ–Ω–Ω—ã–π –ø–æ–≥–æ–¥–∞ –ø—Ä–∞–∫—Ç–∏–∫ –ø—Ä–æ–≥—Ä–∞–º–º–∏—Å—Ç –ø—Ä–æ–∫—Å–∏ –ø—Ä–æ—Å—Ç–æ —Ä–∞–±–æ—Ç–∞—Ç—å —Ä–∞–∑–º–µ—â–µ–Ω–∏–µ —Ä–µ–∞–ª–∏—è —Ä–µ–∑–µ—Ä–≤–Ω—ã–π —Ä—É–±–ª—å —Å–∞–π—Ç —Å–µ–∫—Å —Å–µ—Ä–≤–∏—Å —Å–∏–¥–µ—Ç—å —Å—Ç–∞—Ç—å —Å—Ç–∞—Ç—å—è —Å—Ç—Ä–∞–Ω–∏—Ü–∞ —Ç–µ–º–∞ —É–∑–Ω–∞—Ç—å —Ñ–∏—à–∫–∞ —à–∞–±–ª–æ–Ω—ã
–¢–µ–º:
77,604–°–æ–æ–±—â–µ–Ω–∏–π:
763,363–ü–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π:
30,081–°–µ–π—á–∞—Å –Ω–∞ —Å–∞–π—Ç–µ:
0 –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ 100 –≥–æ—Å—Ç–µ–π