Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
Итак, продолжаем серию статей с рецептами применения A-parser: комплексные примеры с одновременным использованием различного функционала парсера.
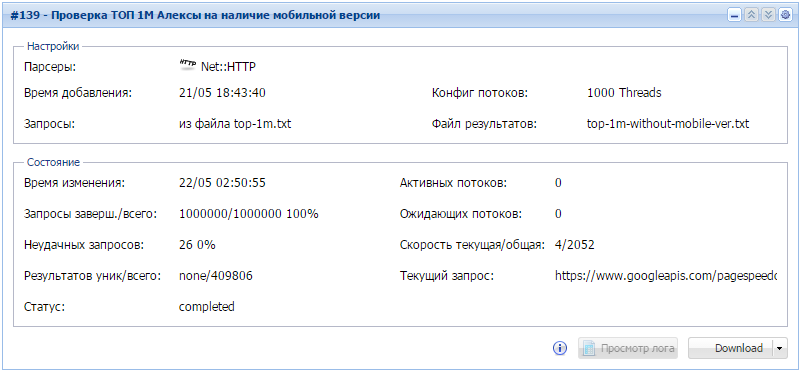
Проверяем наличие мобильной версии для 1000000 сайтов
Работаем с большими объемами данных и учимся искать совпадения в raw data.
- за 8 часов работы данного задания мы узнали что почти 41% самых посещаемых сайтов не имеют мобильных версий. Кто знает, возможно обзаведясь мобильной версией, они стали бы еще более посещаемыми?
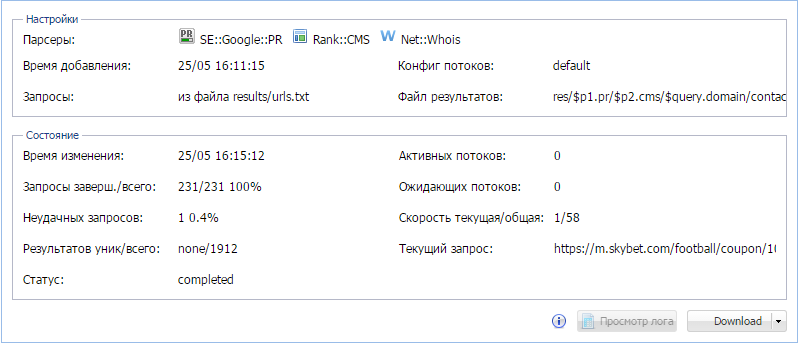
По списку запросов получаем страницы, CMS, PR, e-mail из whois
Комплексное задание, выполняемое в 2 этапа, в котором мы учимся работать с несколькими парсерами, регулярными выражениями, а также красиво выводим результаты во многоуровневые каталоги и несколько файлов.
- на первом этапе используется 1 парсер, на втором - 3
- в конструкторе результатов используется регулярное выражения для извлечения необходимой информации
- результаты выводятся в виде вложенных папок и текстовых файлов по следующей схеме:
Код:Узнать позиции по кеям, как?PR_1 \Joomla \domain.com contacts.txt cache.txt \Drupal \WordPress \no CMS PR_2 PR_3
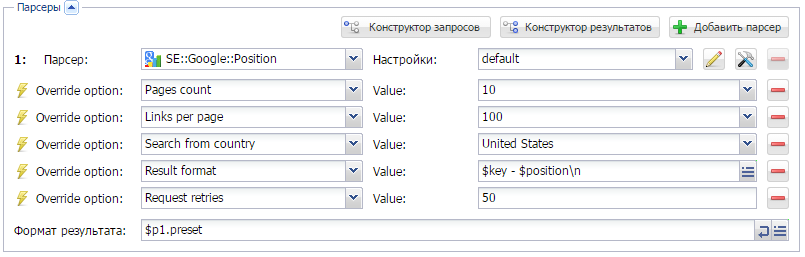
Знакомимся с парсеромSE::Google::Position и проверяем на каком месте в поисковой выдачи находится ключевое слово.
Детальнее о самом парсере здесь.
Предыдущие сборники:
A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 342, Просмотров: 53336)
- 27.05.2015 13:47Опытный



- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
- 0
- 02.06.2015 14:26Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
Очередной, 4-й выпуск сборника рецептов. Поехали!
Анализ выдачи гугла на наличие ключа в тайтле и дескрипшене
Пользуемся возможностями шаблонизатора Template Toolkit. Используем циклы и поиск. А также сохраняем разные результаты в разные файлы.
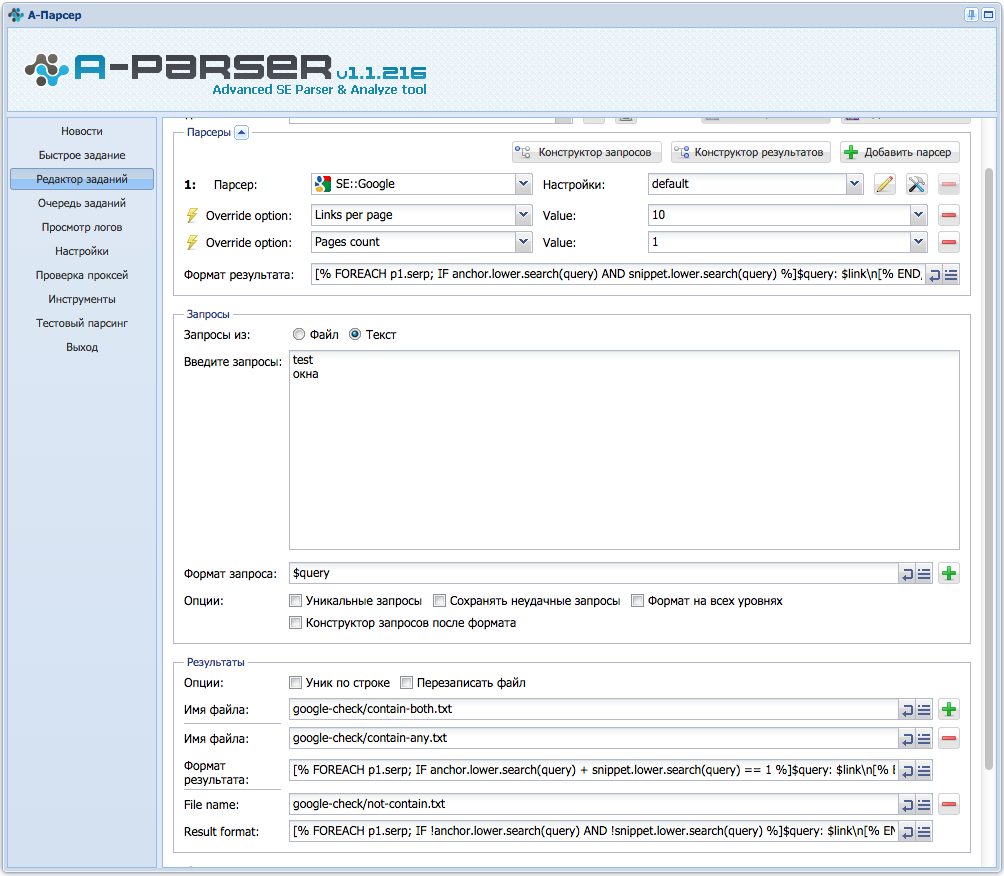
В данном примере осуществляется поиск ключа в анкорах и сниппетах, и в зависимости от результата, сохраняет их в 1 из 3 соответствующих файлов. Все подробности, а также сохранение в 4-ре файла по ссылке выше.
Парсинг товаров с сайта
Парсим интернет-магазин и формируем свою HTML-страницу с результатами.

Суть задания заключается в том, чтобы спарсить названия и характеристики товара из интернет-магазина, сохранив привязку к категории и фото товара. Как все это сделать - по ссылке выше.
Скачиваем файлы
Сохраняем на жесткий диск различные документы из поисковой выдачи, с определением их типа, а также возможностью формировать уникальное имя файла.
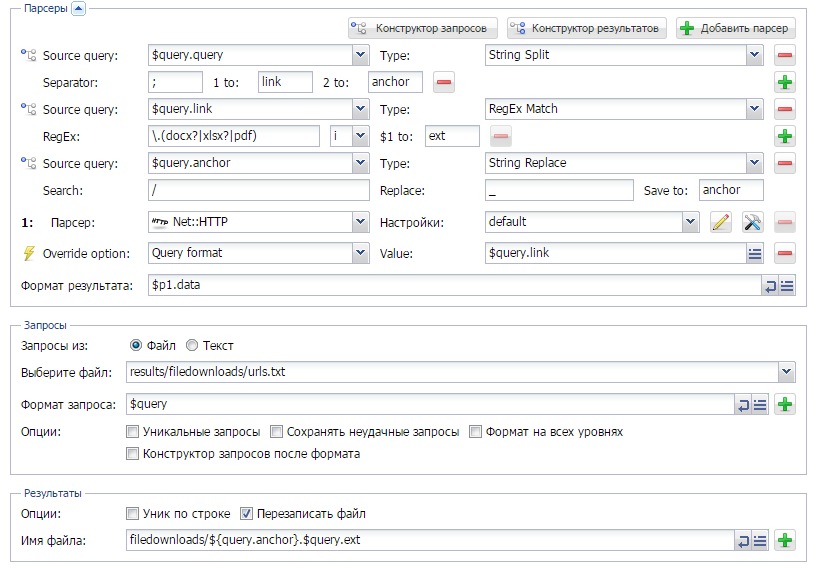
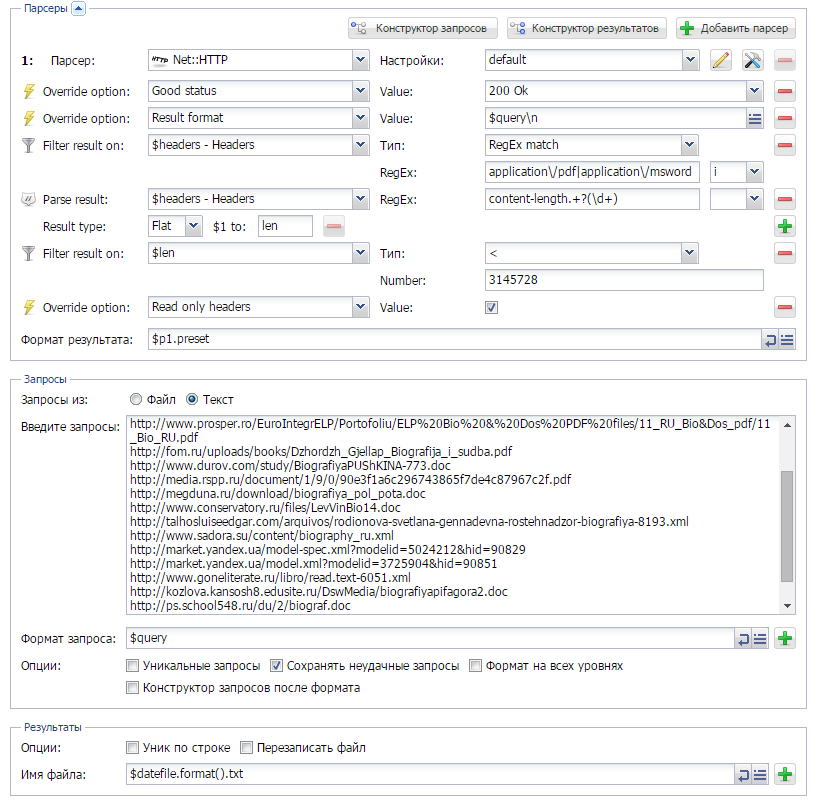
Ну а здесь нам необходимо парсить из выдачи Гугла ссылки на документы формата doc, xls и pdf. Так же необходимо скачивать данные документы, при этом обеспечить уникальность имени файла. Детали - по ссылке выше.
Предыдущие сборники:- 0
- 18.06.2015 15:16Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
5-й выпуск сборника рецептов. Здесь мы научимся парсить ссылки из страниц, где их подгружает JS-скрипт, будем собирать паблик прокси и составлять карту сайта.
Подгрузка ссылок через JS
Есть очень много сайтов, где контент загружается специальным скриптом (AJAX). К примеру, это может быть поиск на сайте. И как спарсить с таких сайтов информацию? Ведь если посмотреть код страницы в браузере - то, к примеру, ссылки там есть, а парсер их не видит... Решение есть, и оно довольно не сложное. Как это сделать - по ссылке выше.

Сборщик паблик прокси: как лучше и насколько это эффективно
Всем известно, что в интернете есть очень много сайтов, где выкладывают публичные прокси (что это на Википедии). Если возникает необходимость в использовании таких прокси - появляется проблема в их сборе, при этом, естественно нужны только живые. Наверное так же известно, что используя А-парсер, можно их собирать. А вот как это делать и насколько это эффективно - читайте по ссылке выше.

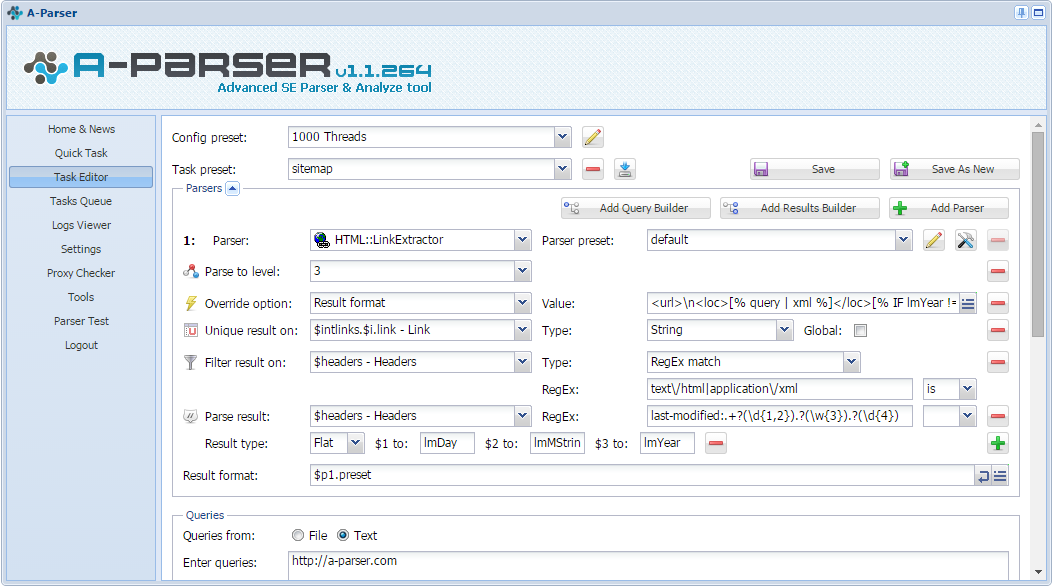
Карта сайта с помощью A-parser
Карта сайта простыми словами - это XML-файл, который помогает поисковикам лучше индексировать сайт. Некоторые SEOшники считают ее отсутствие грубейшей ошибкой. Существует очень много сервисов и инструментов для создания таких карт, ну а мы попробуем создать ее с помощью A-parser. Что из этого получится, и как это делать - читайте по ссылке выше.
Предыдущие сборники:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- 0
- 10.07.2015 12:22Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
6-й выпуск сборника рецептов. Здесь мы попробуем собирать скрытые номера мобильных телефонов из доски объявлений и научимся сохранять результаты работы А-парсера в таблицы с возможностью сортировки.
Парсим базу мобильных телефонов
Базы телефонов могут использоваться по-разному, но основной вид их использования - рассылка смс рекламного характера. А если базу еще и возможно отсортировать по городу, интересу или другим характеристикам, т.е. сделать таргетированную рассылку, то эффективность сильно возрастает. Подобные базы собираются разными способами, мы же поговорим о том, как это сделать с помощью А-парсера.
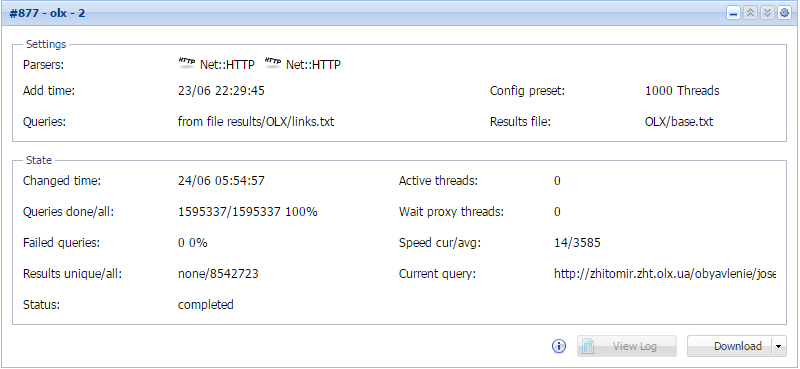
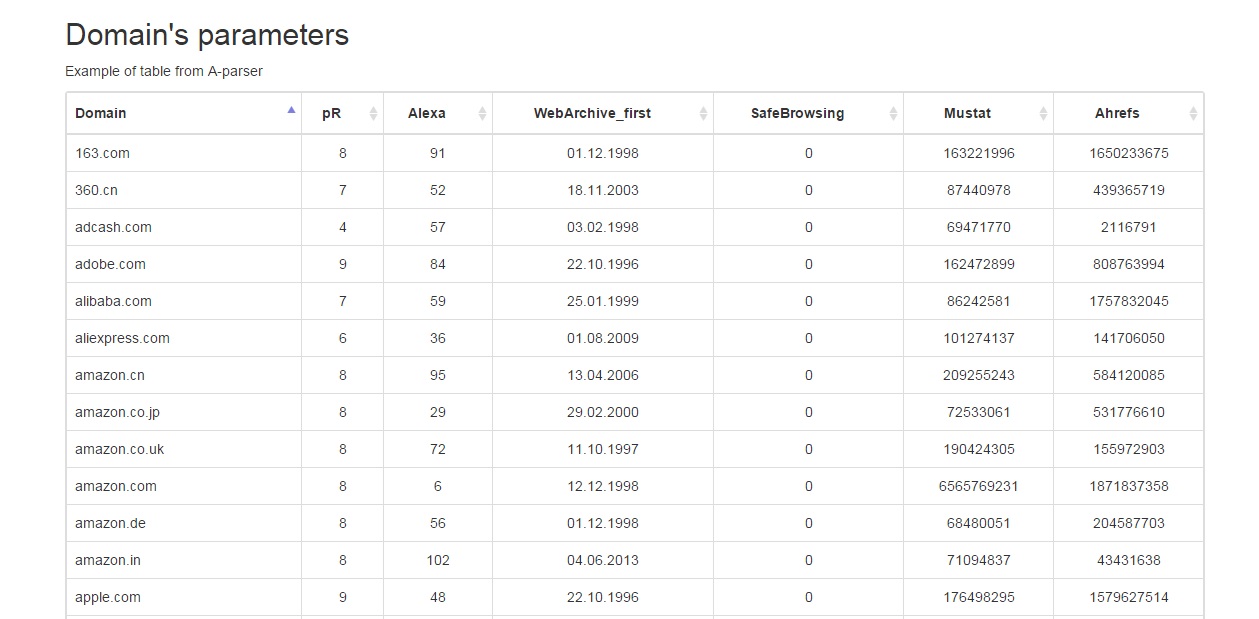
Вывод результатов в таблицу
Бывает, возникает необходимость в красивом и удобном выводе данных, полученных в результате парсинга. И если обычного текстового вида недостаточно, нужно искать другие способы вывода. Об одном таком способе и пойдет речь в статье по ссылке выше.
Предыдущие сборники:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- 0
- 15.07.2015 15:01Новичок
- Регистрация: 16.05.2014
- Сообщений: 1
- Репутация: 0
Отличный инструмент! Выручает во многих моментах
- 0
- 22.07.2015 13:57Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - версия 1.1.269 - получение списка задач по API, только мобильные для WordStat
Два месяца у нас работает профессиональный саппорт, который помогает составлять задания любой степени сложности. Доработана документация, регулярно появляются интересные решения на нашем форуме, которые теперь собраны в едином Каталоге примеров. Также создан большой FAQ, в котором собраны ответы на часто задаваемые вопросы.
Версия 1.1.269 является одной из последних в ветке 1.1.х, в скором времени будет доступна бета версия 1.2, которая принесет новый виток развития A-Parser, следите за новостями
Улучшения
- Теперь по API можно получить список активных заданий, а также опционально список завершенных заданий
- Для парсера
 SE::Yandex::WordStat добавлена возможность получать статистику только для мобильного трафика
SE::Yandex::WordStat добавлена возможность получать статистику только для мобильного трафика - В парсере
 HTML::LinkExtractor теперь обрабатываются только http(s) ссылки
HTML::LinkExtractor теперь обрабатываются только http(s) ссылки - При использовании автоопределения языка в парсере
 SE::Bing::Translator теперь можно вывести в результат язык исходного текста
SE::Bing::Translator теперь можно вывести в результат язык исходного текста
Исправления в связи с изменениями в выдачи
- Исправлен парсер
 SE::YouTube
SE::YouTube - Исправлен парсер
 Rank::MajesticSEO
Rank::MajesticSEO - Исправлен парсер
 SE::Ask
SE::Ask - Исправлен парсер
 SE::Yandex
SE::Yandex - Исправлен парсер
 Rank::Ahrefs
Rank::Ahrefs - Исправлен парсинг рекламных объявлений в
 SE::Google
SE::Google - Исправлен парсер
 Rank::Archive
Rank::Archive
Исправления
- В парсере SE::Bing::Translator исправлен парсинг арабского языка
- Парсер
 Net:: DNS не поддерживал кириллические домены
Net:: DNS не поддерживал кириллические домены - Исправлен парсинг подсказок в парсер SE::Google при использовании подстановок
- Парсер
 SE::Yahoo использовал много CPU
SE::Yahoo использовал много CPU
- 0
- 04.08.2015 13:21Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
7-й выпуск сборника рецептов. Здесь мы рассмотрим вариант парсинга RSS, будем скачивать картинки в зависимости от их характеристик и научимся фильтровать результат по хедерам.
Парсинг RSS
На сегодняшний день RSS остаются довольно популярным вариантом доставки новостей и контента пользователям. В связи с этим его используют почти на всех сайтах, где бывает более-менее периодическое обновление информации. А для нас это возможность быстро спарсить свежие обновления сайта, не анализируя сам сайт. И один из способов, как это сделать описан по ссылке выше.

Как фильтровать результат по определенным хедерам?
Как известно, А-парсер предназначен для парсинга, в основном, текстовой информации. Но кроме этого им вполне реально парсить и другие обьекты (файлы, картинки и т.п.). При этом существует возможность фильтровать их по заголовкам ответа сервера. Об этом по ссылке выше.
Скачивание картинок указанного разрешения и размера
Если выше мы фильтровали результат только по хедерам и рассматривали вариант с документами, то в данной статье мы будем скачивать картинки и фильтровать их по размеру и разрешению. Как это сделать - можно увидеть по ссылке выше.

Еще больше различных рецептов в нашем Каталоге примеров!
Предыдущие сборники:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- 0
- 18.08.2015 11:46Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
8-й выпуск сборника рецептов. В нем мы будем парсить базу организаций из каталога 2GIS, научимся парсить подсказки из Youtube и напишем кастомный парсер Google translate.
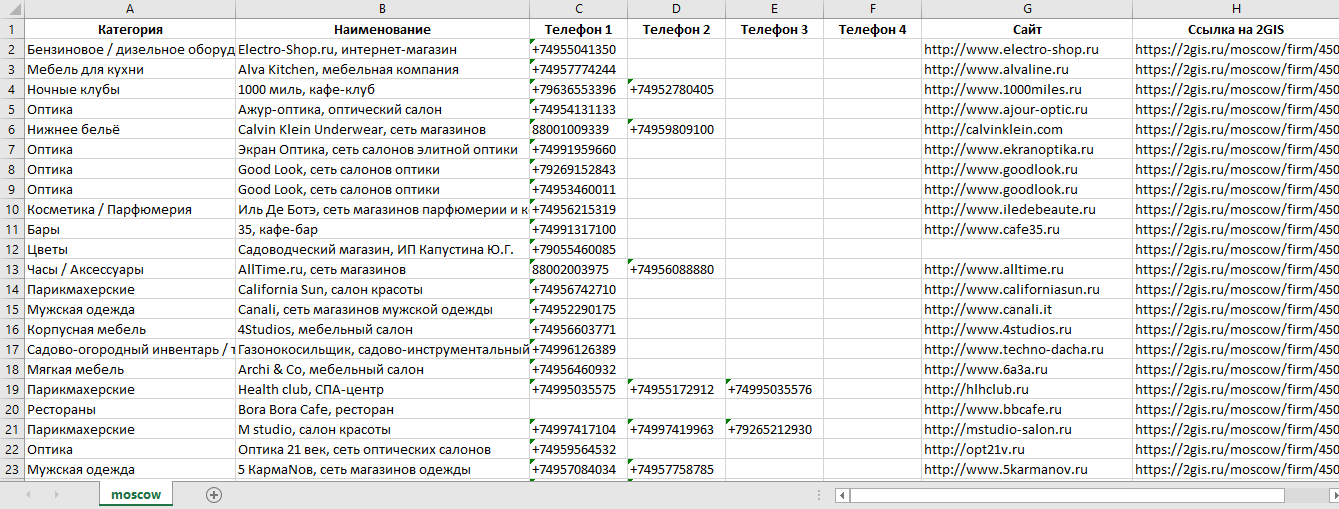
Парсинг 2GIS
2GIS - это довольно большой справочник организаций России (и не только...) с возможностью просмотра их расположения на карте. База содержит более 1580000 организаций в 270 городах России. После парсинга представляет интерес как справочник сайтов, электронных адресов и телефонов организаций.
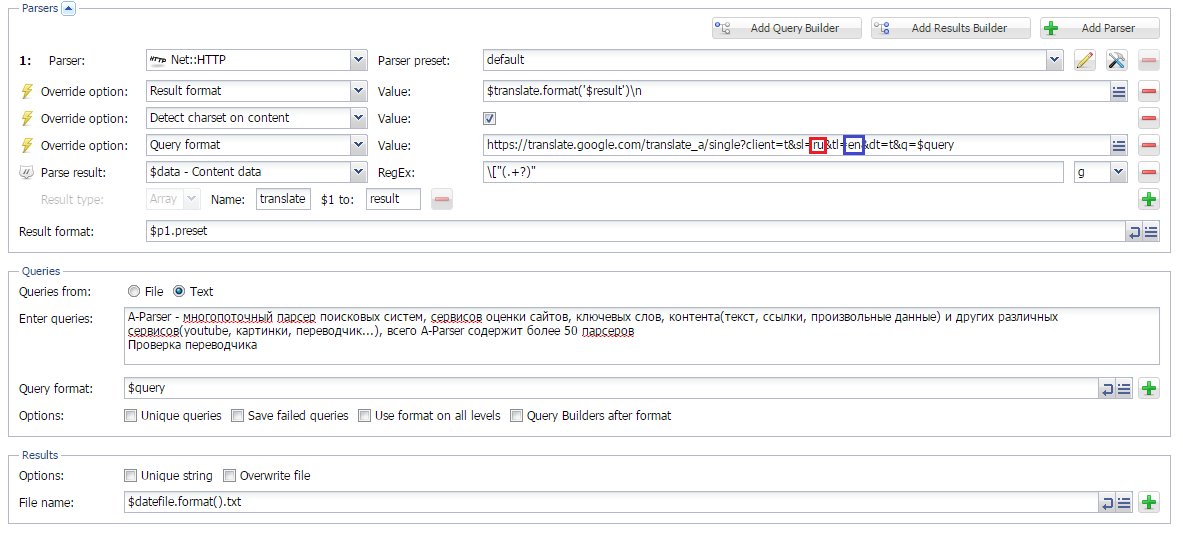
Парсинг Google Translate
В данной статье рассмотрен способ написания кастомного парсера Google translate на основе Net::HTTP. Также реализована возможность задавать направление перевода. Можно использовать для пакетного перевода больших обьемов текста.
Net::HTTP. Также реализована возможность задавать направление перевода. Можно использовать для пакетного перевода больших обьемов текста.
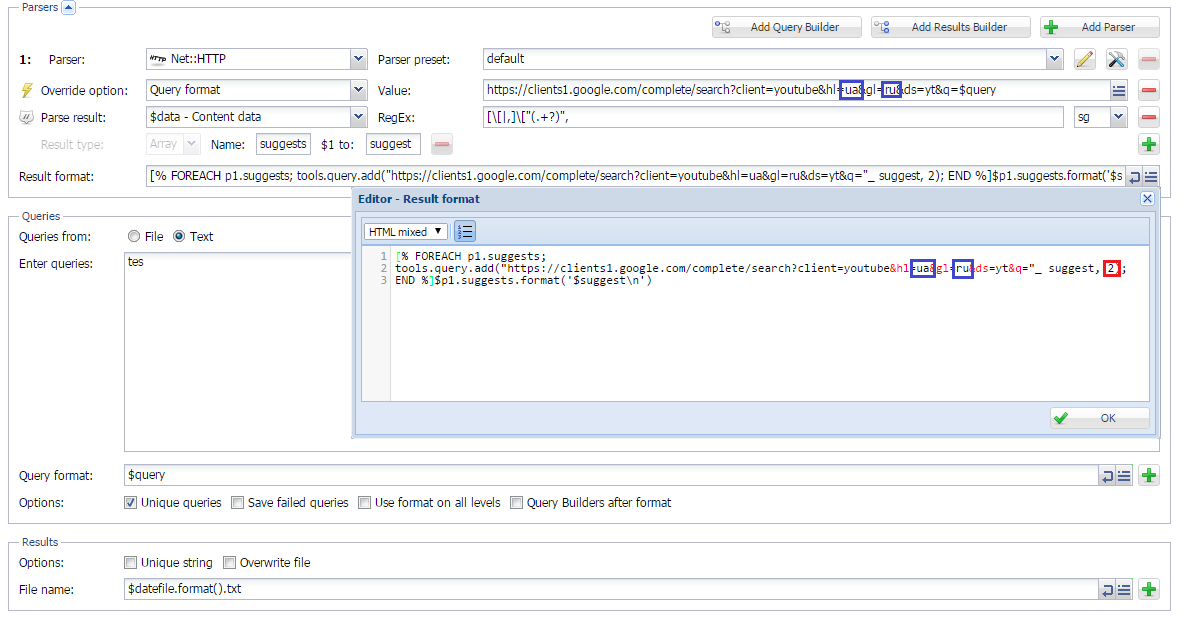
Парсинг подсказок Youtube
Парсинг подсказок поисковых систем - довольно популярный способ поиска ключевых слов. В данной статье также используется Net::HTTP, с помощью которого создается кастомный парсер подсказок Youtube. Реализована возможность задавать язык и страну, а также использовать уже спаршенные подсказки в качестве новых запросов на нужную глубину.
Еще больше различных рецептов в нашем Каталоге примеров!
Предыдущие сборники:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
Последний раз редактировалось Forbidden; 18.08.2015 в 11:51.
- 1
Спасибо сказали:
artinet(18.08.2015), - 16.09.2015 09:07Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
9-й выпуск Сборника рецептов. В нем мы будем работать с ключевыми словами: проверять их сезонность и искать свободные ниши в рунете, проверяя "полезность" ключевиков.
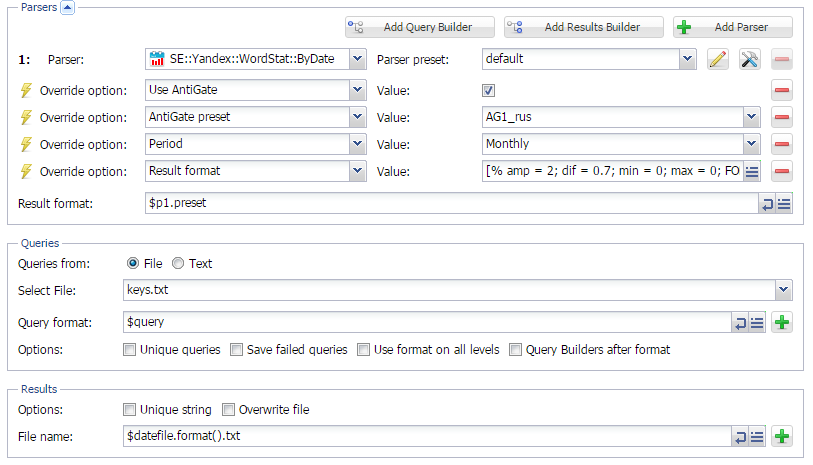
Определение сезонности ключевых слов через Wordstat
Использование нужных ключевых слов в нужное время - один из способов привлечения дополнительного трафика на сайт. Для определения сезонности ключевых слов существует немало различных способов и сервисов. О том, как это делать с помощью А-Парсера - читайте по ссылке выше.
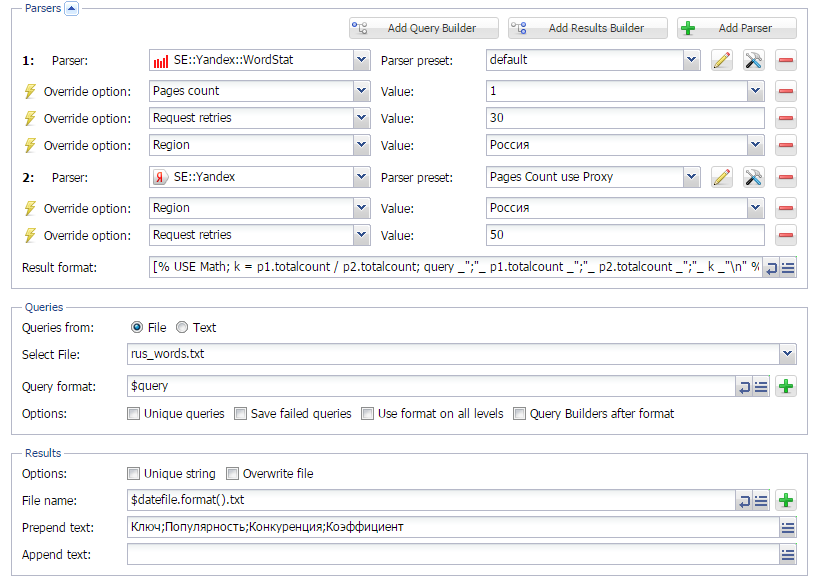
Поиск свободных ниш в RU сегменте интернета
Используя на сайте не только сезонные, а и "полезные" ключевые слова, можно значительно повысить шансы попасть в ТОП10 поисковиков. И если о сезонности мы писали ранее, то о "полезности", а точнее о "незанятости" ключевых слов мы поговорим в данной статье. Полезные или незанятые - это такие КС, которые пользователи часто ищут, но конкуренция по которым не очень высокая. Как их искать - читайте по ссылке выше.
Еще больше различных рецептов в нашем Каталоге примеров!
Предыдущие сборники:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- 0
- 07.10.2015 08:00Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - 1.1.292 - парсинг JSON, улучшения использования памяти, множество исправлений
Улучшения- Поддержка разбора JSON структур в шаблонизаторе
- Добавлена опция "Конструктор запросов на всех уровнях", позволяющая использовать конструктор запросов на всех уровнях вложенного парсинга
- При просмотре статистики работы задания теперь отображается общее число HTTP запросов
- Новый инструмент отладки Gladiator, позволяющий быстро локализовать возможные утечки памяти
- Исправлено определение наличия каптчи на этапе логина в парсере SE::Yandex::WordStat
- Полностью переработан Rank::Ahrefs
- Исправлен парсинг времени кэширования в SE::Yandex
- Исправлен
 SE::Google::Images
SE::Google::Images - Исправлен
 SE::Bing
SE::Bing - Исправлен
 SE::Yahoo::Suggest
SE::Yahoo::Suggest - Исправлен
 SE::AOL
SE::AOL
- Исправлен парсер
 SE::Yandex::TIC - ресурсы у которых тИЦ был неопределен отображались как тИЦ = 0, исправлено на тИЦ = -1
SE::Yandex::TIC - ресурсы у которых тИЦ был неопределен отображались как тИЦ = 0, исправлено на тИЦ = -1 - Исправлено множество утечек памяти
- При замене в регулярных выражениях не работал символ переноса \n
- При использовании большого числа переменных в конструкторе запросов или результатов они могли не влезать в видимую область
- 0


Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 16:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
---------- blog camera canon forum html powershot woocommerce акция база блог быть вывод группа гугл дальнейший добавить домен думать завтра запрос заработок каталоги статей кейс купить куча лайковый магазин месяц ненавидеть необходимый общий очень передаваться поинт покупка пользователь пользоваться помощь попасть править программа продвижение процент ребёнок решить сайт сервис совет создание сообщение сообщество товар участвовать форум цвета цель цена часть яндекс
Тем:
77,609Сообщений:
763,486Пользователей:
30,082Сейчас на сайте:
0 пользователей и 194 гостей