Новая документация и текущий статус Бета-версии
В скором времени увидит свет A-Parser версии 1.1.0 - результат двух-месячной разработки Бета-версии. На текущий момент Бета-версия абсолютно стабильна и рекомендуется к использованию как новым пользователям, так и всем кто уже имеет лицензию
Ключевой особенностью новой версии парсера является наличие новой документации, в которой мы постарались осветить все возможности и особенности работы A-Parser'а. В документации подробно описаны такие возможности как:Обсудить новую документацию можно на форуме
- Задания и очередь
- Форматирование и подстановки запросов
- Форматирование результатов
- Уникализация результатов
- Фильтрация результатов
- Конструктор запросов
- Конструктор результатов
- Parse cutom result и использование регулярных выражений
- Описание шаблонизатор Template Toolkit
- и многое другое
Помимо этого текущая бета версия содержит множество исправлений и улучшений, следите за новостями о релизе!
A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 342, Просмотров: 53332)
- 26.05.2014 13:43Опытный



- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
- 0
- 15.07.2014 10:50Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Новая версия Lite, автоматическая оплата прокси
- Добавлена новая лицензия Lite, включающая только парсеры Google и Яндекса
- Добавлена автоматическая оплата через WebMoney, Yandex.Money, Visa, MasterCard, Paxum, LiqPay, PerfectMoney, W1, Банки, СМС, Терминалы оплаты
- Оплачивать можно лицензии на A-Parser, A-Poster, прокси, обновления A-Parser и дополнительные лицензии A-Parser
- Новая сетка цен
- Последние изменения в бета версии
- Переработано описание парсера
- 0
- 23.07.2014 10:39Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Релиз A-Parser 1.1.0, автоматический прием PayPal, Wire, QIWI
Релиз A-Parser 1.1.0 - результат активной разработки в течении двух месяцев в рамках бета-версии

Улучшения- Новый парсер
 HTML::TextExtractor::LangDetect - улучшенное определение языка страницы, без использования сторонних сервисов
HTML::TextExtractor::LangDetect - улучшенное определение языка страницы, без использования сторонних сервисов - Для парсера
 SE::Google добавлена возможность указывать локацию поиска - город или регион
SE::Google добавлена возможность указывать локацию поиска - город или регион - Новый инструмент - обновление A-Parser, теперь обновления можно устанавливать автоматически через интерфейс, поддерживается два канала обновлений - Stable и Beta
- Для уникализации результатов теперь используется LevelDB - лучшая скорость и низкое потребление памяти
- Улучшена работа с битыми кодировками и детектирование кодировки страницы
- В инструменте тестирования шаблонов теперь доступны предустановленные результаты для всех парсеров
- Шаблонизатор теперь можно использовать в самих запросах, в формате запроса, а также в Конструкторе результатов
- Для парсера
 Net::HTTP при формировании POST запроса добавлена возможность использовать шаблонизатор в теле запроса
Net::HTTP при формировании POST запроса добавлена возможность использовать шаблонизатор в теле запроса - Добавлена возможность выводить результаты в формате JSON
- Новая опция Not found is error для парсера
 Net:: DNS - позволяет перепроверять ложные ответы от DNS серверов
Net:: DNS - позволяет перепроверять ложные ответы от DNS серверов - Добавлена возможность удалять неиспользуемые базы данных Keep unique
- Новые подсказки в интерфейсе, соответствуют новому формату шаблонов
- Добавлена возможность сбросить пароль доступа к интерфейсу A-Parser
- Сервер парсера теперь можно выключить или перезапустить через веб-интерфейс
- Исправлен парсер
 SE::Yandex в связи с переходом на новую выдачу
SE::Yandex в связи с переходом на новую выдачу - Исправлен парсер
 SE::AOL в связи с изменением в выдачи
SE::AOL в связи с изменением в выдачи - Исправлен ошибка, при которой проверка прокси начиналась заново при перезагрузке интерфейса
- Исправлена медленная работа очереди заданий при большом количестве заданий(более 1000)
- Исправлен вывод исходного запроса $query.first при многоуровневом парсинге в
 SE::Yandex::WordStat
SE::Yandex::WordStat - Net:: DNS - исправлена работа на ОС Windows
 SE::Yandex::Webmaster::Index удален в связи с прекращением работы сервиса
SE::Yandex::Webmaster::Index удален в связи с прекращением работы сервиса- Исправлено некорректное определение некоторых полей в парсере
 Net::Whois
Net::Whois - Исправлена работа переменной $pagenum в парсере Net::HTTP
- Исправлена ошибка, при которой парсер мог вылететь при использовании уникализации по простым результам
- Задания с пустым файлом запросов не завершались автоматически
- Исправлен парсер
 Rank::Ahrefs в связи с изменением в выдачи
Rank::Ahrefs в связи с изменением в выдачи - Исправлен парсер
 Rank::Alexa в связи с изменением в выдачи
Rank::Alexa в связи с изменением в выдачи - Исправлен парсер
 Rank::MajesticSEO в связи с изменением в выдачи
Rank::MajesticSEO в связи с изменением в выдачи - Исправлена работа с кодировкой windows-1251
- Исправлен подсчет числа простых результатов
- Исправлена работа метода CONNECT при использовании прокси с авторизацией по логин\паролю
- Исправлен парсер
 Rank::Category в связи с изменением в выдачи
Rank::Category в связи с изменением в выдачи
Также мы рады сообщить что добавили прием PayPal, QIWI и Wire Transfer в автоматическом режиме- 0
- 12.08.2014 13:46Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - версия 1.1.20 - обновление парсера Rank::CMS, разные форматы результатов для нескольких файлов
Улучшения- Полностью переработан парсер
 Rank::CMS, теперь он определяет движок сайта на основе большой и качественной базы признаков Wappalyzer, также появилась возможность выбрать категорию или конкретные движки для распознавания
Rank::CMS, теперь он определяет движок сайта на основе большой и качественной базы признаков Wappalyzer, также появилась возможность выбрать категорию или конкретные движки для распознавания - Появилась возможность сохранять результаты одного задания в разные файлы, с выбором формата результата для каждого файла, к примеру при парсинге Гугла можно сохранять ссылки в один файл и сниппеты в другой
- Добавлена возможность использовать шаблоны в параметрах Extra query string и User Agent
- В шаблонах теперь можно использовать инструменты, которые доступны через переменную $tools, первый инструмент - выбор произвольного User Agent: $tools.ua.random(), список агентов хранится в файле files/tools/user-agents.txt
- Улучшен парсер Net::DNS при работе через прокси
- В API появилась возможность запрашивать статус сразу нескольких заданий
- В API появилась возможность скачивать файл результата
- Парсер SE::AOL теперь позволяет выбрать US, UK, FR или DE выдачу
- В парсере Rank::Ahrefs теперь дополнительно парсятся параметры URL Rank и Ahrefs Domain Rank
- Исправлен парсер
 SE::YouTube в связи с изменением в выдачи
SE::YouTube в связи с изменением в выдачи - Исправлен парсинг с блогов в парсере SE::Google в связи с изменением в выдачи
- Исправлена ошибка при которой парсер мог вылететь если в качестве запроса передать очень длинный URL
- 0
- 28.08.2014 11:40Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - версия 1.1.41 - новые парсеры MailRu и Dogpile, поддержка многоядерности для чекера CMS
Улучшения- Новый парсер
 SE::MailRu - собирает ссылки, анкоры и сниппеты, количество результатов в выдаче
SE::MailRu - собирает ссылки, анкоры и сниппеты, количество результатов в выдаче - Новый парсер
 SE::MailRu::position - проверяет позиции сайтов в выдаче go.mail.ru
SE::MailRu::position - проверяет позиции сайтов в выдаче go.mail.ru - Новый парсер
 SE::Dogpile - парсер поисковика dogpile.com, собирает ссылки, анкоры и сниппеты, количество результатов в выдаче и связанные ключевые слова
SE::Dogpile - парсер поисковика dogpile.com, собирает ссылки, анкоры и сниппеты, количество результатов в выдаче и связанные ключевые слова - Добавлена экспериментальная поддержка многоядерных процессоров для наиболее требовательного к ресурсам процессора парсера Rank::CMS
- Для парсера Rank::Ahrefs добавлен парсинг социальных факторов(google+, twitter, facebook), а также возможность выбора режима отчета(ссылка, папка, домен, домен с сабдоменами)
- Для парсера Rank::MajesticSEO добавлена возможность получать данные по полной ссылке
- Новая опция Emulate browser headers для парсера Net::HTTP - автоматически эмулирует хедеры современных браузеров
- Для парсера
 SE::Yandex::position теперь доступна статистика по использованию каптчи
SE::Yandex::position теперь доступна статистика по использованию каптчи
- Исправлен парсинг рекламных блоков в парсере SE::Google в связи с изменением в выдачи
- Исправлен парсер
 SE::Baidu в связи с изменением в выдачи
SE::Baidu в связи с изменением в выдачи - Исправлен парсер проверки языка сайта
 SE::Bing::LangDetect
SE::Bing::LangDetect
- 0
- 16.09.2014 12:54Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - версия 1.1.61 - улучшение очереди заданий, поддержка аккаунтов в парсере Яндекса
Улучшения- Появилась возможность ограничивать общее потребление потоков, что позволяет пропускать задания превышающие текущее потребление, давая возможность выполнится заданиям с меньшим числом потоков. Также данный функционал полезен при использовании прокси-сервисов с лимитированным числом подключений, тем самым можно гарантированно не выходить за пределы тарифа
- В очереди заданий теперь можно удалить все задания разом, отдельно для активной очереди и очереди завершенных заданий
- Парсер SE::Yandex теперь поддерживает работу с аккаунтами(опция Use Accounts)
- При парсинге рекламы в SE::Google теперь дополнительно можно вывести позицию рекламного блока(сверху или справа), а также номер страницы выдачи, на котором показано рекламное объявление
- Исправлено отображение русских имен файлов запросов и результатов на ОС Linux
- Исправлено определение ТИц в парсере
 SE::Yandex::TIC
SE::Yandex::TIC - Исправлено распознавание каптчи в регистраторе аккаунтов Яндекса
 SE::Yandex::Register в связи с изменением в выдачи
SE::Yandex::Register в связи с изменением в выдачи - Исправлена работа с заблокированными аккаунтами в парсере SE::Yandex::WordStat
- 0
- 29.09.2014 11:38Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
Этот пост начинает серию статей с рецептами применения A-Parser: комплексные примеры с одновременным использованием различного функционала парсера. Помимо детального разбора заданий можно также оценить скорость обработки запросов и скачать результаты парсинга
Определяем CMS для 1000000 доменов за 15 часов
В примере рассказано как определить используемый движок у сайтов из базы Алексы топ-миллион, результат автоматически сортируется по файлам с названием CMS. Также дан пример как увеличить скорость обработки и проверить 1 миллион доменов всего за 2 часа
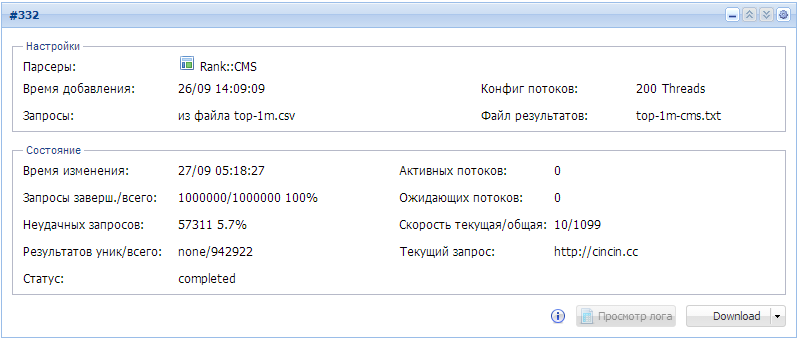
Немного статистики:- Скорость парсинга составила 1100 доменов в минуту
- Всего определились 301841 из 1000000 доменов как использующие на своей главной странице одну из популярных CMS, форумов или Wiki
- Определено 126 различных CMS
- Топ 10 самых популярных CMS, первое значение определяет количество доменов:
Код:Читать целиком »209855 WordPress 23732 Joomla 22945 Drupal 6488 TYPO3 CMS 4917 vBulletin 3726 1C-Bitrix 2515 phpBB 2415 ExpressionEngine 2022 DataLife Engine 1928 Microsoft SharePoint
Оценка частотности по Вордстату, словарь Даля, 115000 слов за 40 минут
Проверяем словарь Даля на частотность запросов в Яндексе используя парсер SE::Yandex::WordStat, скорость парсинга составила 3000 слов в минуту без использования каптчи! Результат сохраняется в 2 разных файла - в первом статистика по исходным запросам, во втором - все новые ключевые слова из левой и правой колонки Вордстата
Немного статистики:- Парсинг 115390 ключевых слов занял всего 40 минут
- 80208 слов из 115390 имеют ненулевую статистику в Вордстате
- Общее число показов всех слов составляет 20001443927, ~20 миллиардов в месяц
- Дополнительно спаршено 1143045 новых ключевых слов с общим числом показов ~36 миллиардов в месяц
Создаем парсер VKontakte обрабатывающий 14000 анкет в минуту
В примере показывается как с помощью парсера Net::HTTP и регулярных выражений можно создать парсеры почти любых сайтов и сервисов, например VKonktake
Пример разделен на 2 части:- Сбор ссылок на анкеты из результатов поиска
- Обработка анкет - парсинг полей "Родной город", "Семейное положение" и "Время захода на анкету"
Код:Читать целиком »http://vk.com/id1492 - none - none - none http://vk.com/id1485 - п. Сиверский - всё сложно - заходил 15 сентября в 1:34 http://vk.com/id1489 - Ленинград - none - Online http://vk.com/id1481 - Санкт-Петербург - none - заходила 48 минут назад http://vk.com/id1482 - град Поднебесный - не женат - Online http://vk.com/id1493 - none - none - none
- 0
- 14.10.2014 13:16Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - версия 1.1.86 - поддержка многоядерной обработки и фильтрации результатов
В данной версии добавлена поддержка обработки и фильтрации результатов(Parse custom result, Конструкторы результатов и фильтры) на многоядерных процессорах, что в несколько раз увеличивает скорость парсинга при использовании "тяжелых" регулярных выражений, например скорость сбора email адресов со страниц достигает 10000 ссылок в минуту при 2000 потоках(при этом A-Parser обрабатывает поток 130 мбит\с gzip-сжатых данных)
Другие улучшения- Добавлена возможность указать сразу несколько форматов для запроса, что позволяет комбинировать множество вариантов подстановок для одних и тех же запросов в одном задании
- Добавлена возможность использовать формат запроса на всех уровнях вложенного парсинга, например при парсинге ключевых слов с подсказок Google подстановки будут добавляться так же и для новых найденных ключевых слов(как и для исходных запросов)
- Для парсера SE::Yandex добавлена возможность парсить не персонализированную выдачу, что позволяет более точно снимать позиции сайтов
- В парсере Net::HTTP опция Check next page теперь поддерживает захват следующей ссылки для перехода, она будет использоваться если не указана опция Use pages
- В некоторых случаях могли неверно обрабатываться страницы большого размера с сжатием gzip
- Парсер Net::Whois не работал без использования прокси, ошибка появилась в предыдущей версии
- В конструкторе результатов, при использовании замены по регулярному выражению, некорректно обрабатывалась замена переменных $1 $2...
- Парсер мог упасть при использовании одинаковой базы Keep unique в двух одновременно работающих заданиях
- 0
- 29.10.2014 11:39Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
A-Parser - 1.1.108 - улучшения паука сбора ссылок, множество исправлений
Улучшения парсера HTML::LinkExtractor
HTML::LinkExtractor- Добавлена опция Follow links позволяющая выбрать порядок следования по ссылкам: только по внутренним, по внутренним и внешним, только по внешним
- Добавлен массив результатов $followlinks, который содержит ссылки для последующего перехода, над этим массивом можно применять фильтры и конструкторы результатов, что позволяет переходить только по определенным ссылкам(например только по топикам форумов)
- Добавлена корректная обработка тега <base href=
- Теперь парсер автоматически определяет кодировку по содержимому страницы, если другие методы не дали результатов. В случае если кодировку определить не удается и она не является корректной с точки зрения UTF-8 то содержимое страницы становится недоступным для обработки. Данное улучшение призвано исправить редкие проблемы когда файл результата A-Parser'а невозможно использовать в качестве запросов, т.к. файл мог содержать некорректную кодировку
- При парсинге рекламы в SE::Google теперь дополнительно парсится видимая ссылка на сайт
- Исправлен парсер SE::Yandex в связи с изменением в выдачи
- На платформе Windows при закрытии приложения парсера возникала ошибка
- В парсере Net::Whois не был доступен исходный результат $data для пользовательской обработки
- В парсере SE::Yandex была ошибка в получении каптчи если в запросе содержалась скобка
- Результат $query мог быть изменен некоторыми парсерами
- Парсер
 Rank::OpenSiteExplorer исправлен в связи с изменением в выдачи
Rank::OpenSiteExplorer исправлен в связи с изменением в выдачи - Добавлен запрет на изменение результатов с зарезервированными именами($query, $info)
- При использовании нескольких конструкторов результатов невозможно было выбрать новые результаты для обработки
- 0
- 06.11.2014 14:09Опытный
- Регистрация: 17.08.2010
- Сообщений: 311
- Репутация: 23
Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
Этот пост продолжает серию статей с рецептами применения A-Parser: комплексные примеры с одновременным использованием различного функционала парсера. Помимо детального разбора заданий можно также оценить скорость обработки запросов и скачать результаты парсинга
Парсим базу для XRumer: 420000 форумов за 9 часов
Учимся быстро собирать большие базы методом перебора
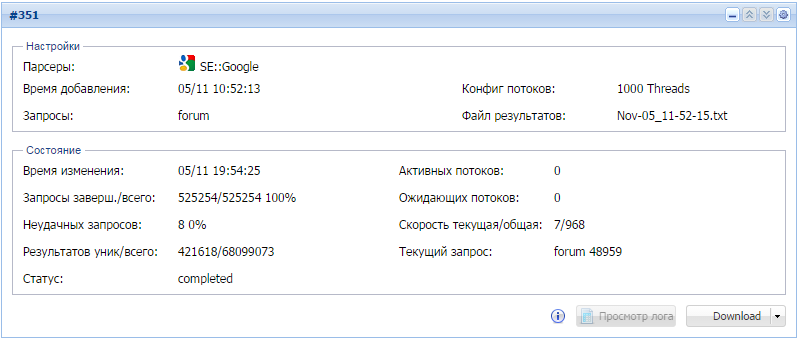
За 9 часов работы:- Было обработано 525254 запроса на максимальную глубину
- Спаршено 68 миллионов ссылок, 420к из которых подходят под фильтр и уникальны по домену
- Средняя скорость парсинга составила 1000 запросов в минуту
Парсим ссылки на страницы с контактными данными, затем собираем с них email-адреса

- Средняя скорость обработки составила 12000 ссылок в минуту
- ТОП-10 почтовых доменов:
Код:249772 mail.ru 129894 gmail.com 91901 yandex.ru 25625 rambler.ru 20821 bk.ru 19773 hotmail.com 14656 yahoo.com 14117 list.ru 13636 inbox.ru 11670 ukr.net
Сбор перелинкованных топиков
Метод описывает как используя возможности парсера HTML::LinkExtractor собирать ссылки на перелинкованные топики - еще один хороший метод сбора баз форумов для XRumer
Алгоритм работы:- Переходим только по внешним ссылкам
- Фильтруем ссылки для перехода по признакам форумов
- Добавляем уникализацию по домену
- Сохраняем ссылки по которым переходим, тем самым собираем все ссылки на новые форумы которые встретятся
Парсинг форумов по признакам и запросам
Классический вариант сбора форумов - используя признаки движков и подставляя дополнительные кейворды. Ссылки дополнительно фильтруются по регулярному выражению и проходят уникализацию по домену
Предыдущие рецепты:- 1
Спасибо сказали:
SeotopInUa(06.11.2014),


Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 15:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
---------- blog camera canon forum html powershot woocommerce акция база блог быть вывод группа гугл дальнейший добавить домен запрос зарабатывать заработок каталоги статей кейс купить куча лайковый магазин месяц ненавидеть необходимый общий очень передаваться поинт покупка пользователь пользоваться помощь попасть править программа продвижение процент ребёнок решить сайт сервис совет создание сообщение сообщество средство товар участвовать форум цвета цель цена часть яндекс
Тем:
77,609Сообщений:
763,486Пользователей:
30,082Сейчас на сайте:
0 пользователей и 245 гостей