Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
21-й сборник рецептов. В нем мы научимся отправлять сообщения в Telegram прямо из A-Parser, изучим работу с модулями Node.js в JS парсерах на примере решения задачи фильтрации по множеству признаков, а также спарсим весь IMDb. Поехали!
Уведомления в Telegram из A-Parser
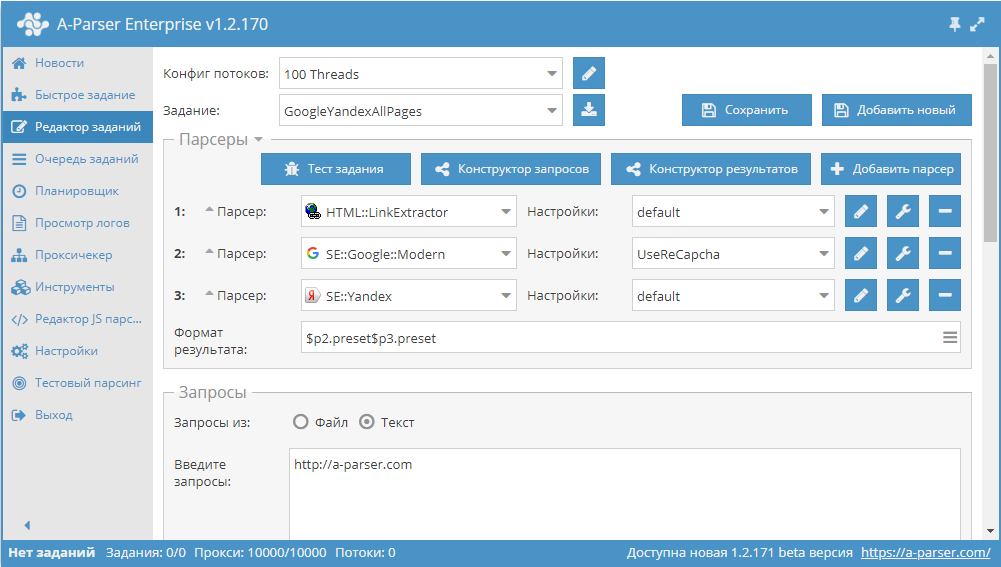
Telegram является одним из самых популярных мессенджеров благодаря своей простоте, и в то же время большому функционалу. Среди прочего, в Телеграме можно создавать ботов, с помощью которых можно делать чаты более интерактивными. Взаимодействие с ботом на на стороне сервера происходит через Telegram Bot API. Используя эти возможности, можно легко и буквально за несколько минут настроить уведомления себе в Telegram прямо из парсера. О том, как это сделать, а также несколько реальных примеров - по ссылке выше.
Фильтрация по множеству признаков
Как известно, для фильтрации в А-Парсере используется встроенный функционал фильтров. Но бывают ситуации, когда список признаков, наличие которых нужно проверять, очень большой и его сложно вписать в строку стандартного фильтра.
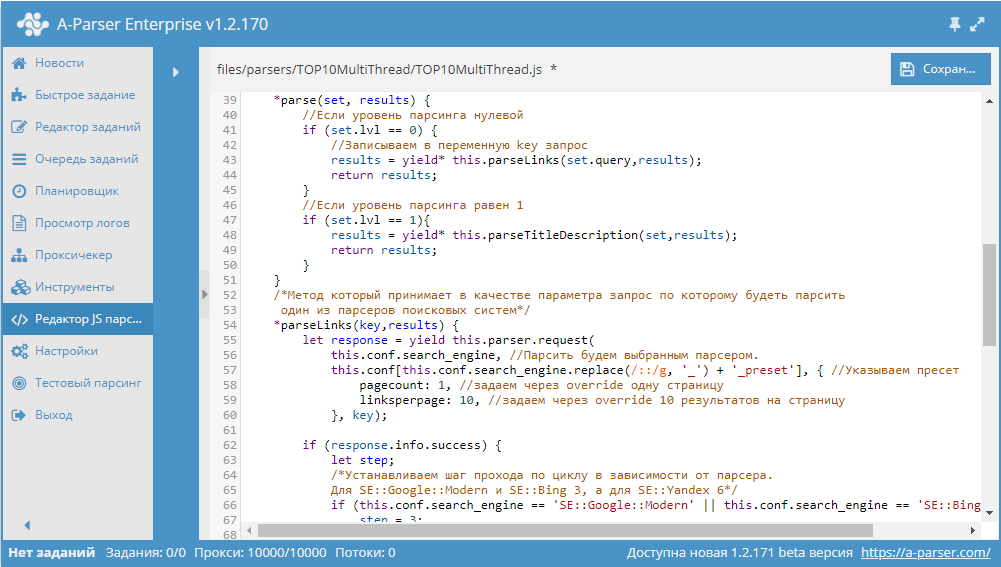
Начиная с версии 1.2.127 в A-Parser добавлена поддержка модулей Node.js. Благодаря этому появилась возможность читать список признаков из файла и использовать его для проверки страниц. О том, как это сделать, а также готовый парсер с мультифильтром - по ссылке выше.
Парсинг рекомендаций фильмов из IMDb
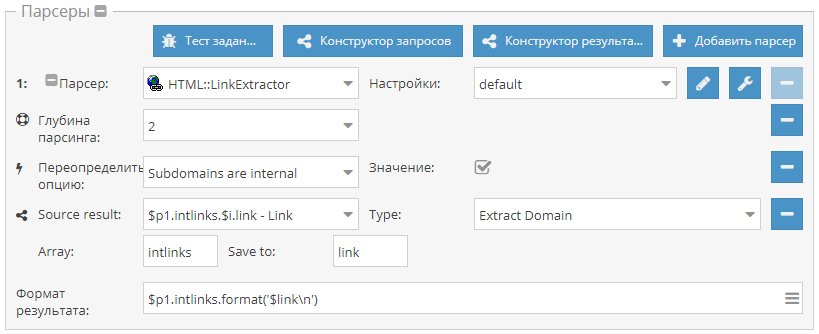
Пример решения задачи по сбору данных о фильмах и их рекомендаций на IMDb. Данная статья показывает, как можно решать задачи, которые на первый взгляд требуют много времени и ресурсов, буквально за несколько часов. Узнать о том, как спарсить весь IMDb за 1,5 часа, а также посмотреть пресет и забрать готовую базу можно по ссылке выше.
Еще больше различных рецептов в нашем обновленном Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
Сборники статей:
A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 341, Просмотров: 52692)
- 16.03.2018 12:16Опытный



- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 27.03.2018 12:24Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.160 - поддержка SQLite, проверка доменов на клей, Parse all results в SE::Yahoo

Улучшения- Добавлена поддержка SQLite в JavaScript парсерах и шаблонизаторе, пример использования здесь
- Добавлена защита от случайного закрытия окна парсера
- В
 SE::Yahoo добавлены Parse all results и Parse related to level
SE::Yahoo добавлены Parse all results и Parse related to level  SE::Yandex::TIC полностью переписан, добавлена возможность проверять домены на клей
SE::Yandex::TIC полностью переписан, добавлена возможность проверять домены на клей- В
 Rank::MegaIndex добавлена поддержка ReCaptcha2
Rank::MegaIndex добавлена поддержка ReCaptcha2 - Улучшен парсинг сниппетов в
 SE:: DuckDuckGo
SE:: DuckDuckGo - Улучшен сбор почт в
 HTML::EmailExtractor
HTML::EmailExtractor
- Обновлен алгоритм Bypass Cloudflare
 SE::Bing::Translator почти полностью переписан в связи с изменением логики работы переводчика Bing
SE::Bing::Translator почти полностью переписан в связи с изменением логики работы переводчика Bing- Исправлена работа
 SE::Seznam с некоторыми видами запросов
SE::Seznam с некоторыми видами запросов - Исправлен парсинг related keywords, а также мобильной выдачи в
 SE::Google::Modern
SE::Google::Modern - Исправлен парсинг related keywords в
 SE::Bing
SE::Bing - Исправлена работа
 SE::IxQuick при работе с русскоязычными запросами
SE::IxQuick при работе с русскоязычными запросами  SE::Yandex:: Direct,
SE::Yandex:: Direct,  SE::Google::ByImage,
SE::Google::ByImage,  SE::Yandex::WordStat
SE::Yandex::WordStat
- Исправлена работа SE::Google::Modern на IPv6 прокси
- Исправлена ошибка, из-за которой SE::Google::Modern собирал ссылки с пометкой опасных сайтов в общий массив ссылок
- Исправлена работа с оператором поиска + в SE::Bing
- Исправлен парсинг запросов со спецсимволами в SE:: DuckDuckGo
- Исправлена работа
 Rank::MajesticSEO
Rank::MajesticSEO - Исправлен баг с overrideOpts в JS парсерах
- Исправлена работа с переменными при их создании в Parse custom results, а также при использовании нижнего подчеркивания в именах в Конструкторе результатов
- Исправлена работа tools.js, баг появился в одной из предыдущих версий
- Исправлен баг, из-за которого А-Парсер падал на некоторых ОС, появился в одной из предыдущих версий
- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 06.04.2018 12:15Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Видео урок: Создание JS парсеров. Работа с CAPTCHA
Третье видео в цикле уроков по созданию JavaScript парсеров. Здесь рассказано о том, как написать JS парсер, в котором будет поддержка антигейта для разгадывания каптч на страницах.

В уроке рассмотрено:- Создание JS-парсера для разгадывания капчи
- Работа с объектом this.captcha внутри JavaScript кода
- Описание процесса разгадывания каптчи, реализованного в A-Parser
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 27.04.2018 12:21Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Сборник статей #3: пагинация, переменные и БД SQLite
В этом сборнике статей мы рассмотрим все возможные варианты решения задачи прохода по пагинации на сайтах, очень детально изучим работу с переменными в JavaScript парсерах, а также попробуем работать с базами данных SQLite на примере парсера курсов валют. Поехали!
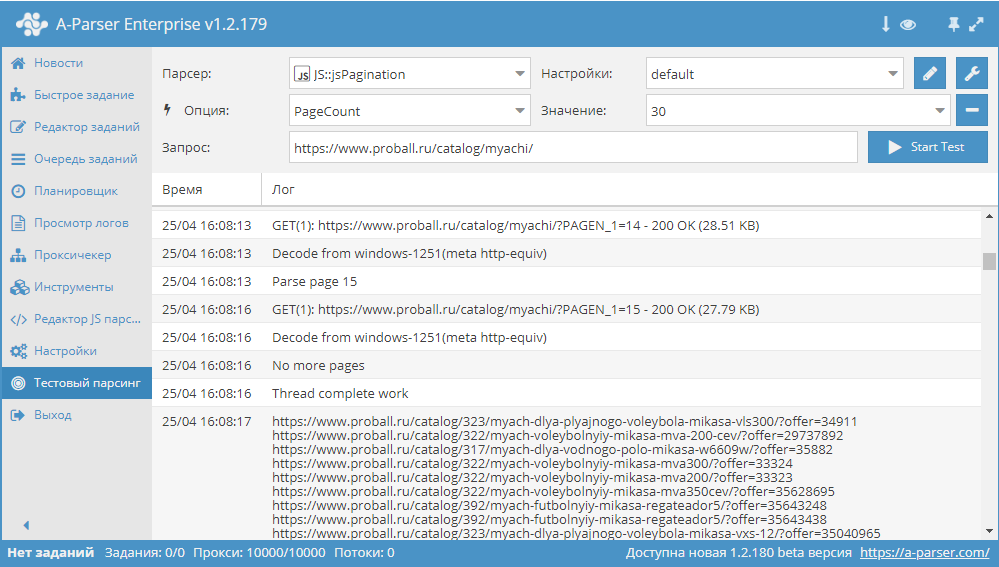
Обзор вариантов прохода по пагинации
В A-Parser существует несколько способов, с помощью которых можно реализовать проход по пагинации. В связи с их разнообразием, становится актуальным вопрос выбора нужного алгоритма, который позволит максимально эффективно переходить по страницам в процессе парсинга. В этой статье мы постараемся разобраться с каждым из способов максимально подробно. Также будут показаны реальные примеры и даны рекомендации по оптимизации многостраничного парсинга. Статья - по ссылке выше.
Переменные в парсерах JavaScript
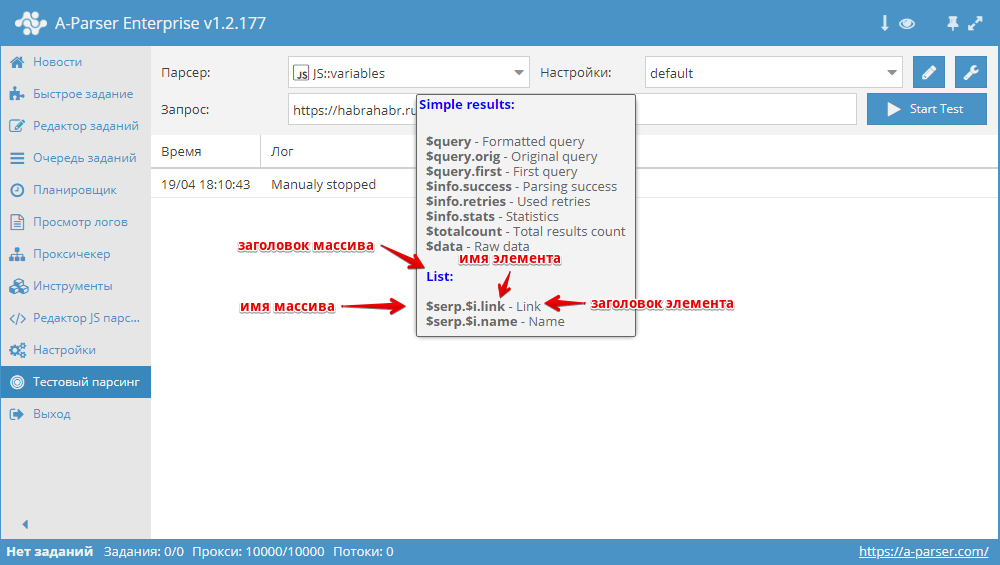
JS парсеры в А-Парсере появились уже около года назад. Благодаря им стало возможным решать очень сложные задачи по парсингу, реализовывая практически любую логику. В этой статье мы максимально подробно изучим работу с разными типами переменных, а также узнаем, как можно оптимизировать работу сложных парсеров. Все это - в статье по ссылке выше.
Разработка JS парсера с сохранением результата в SQLite
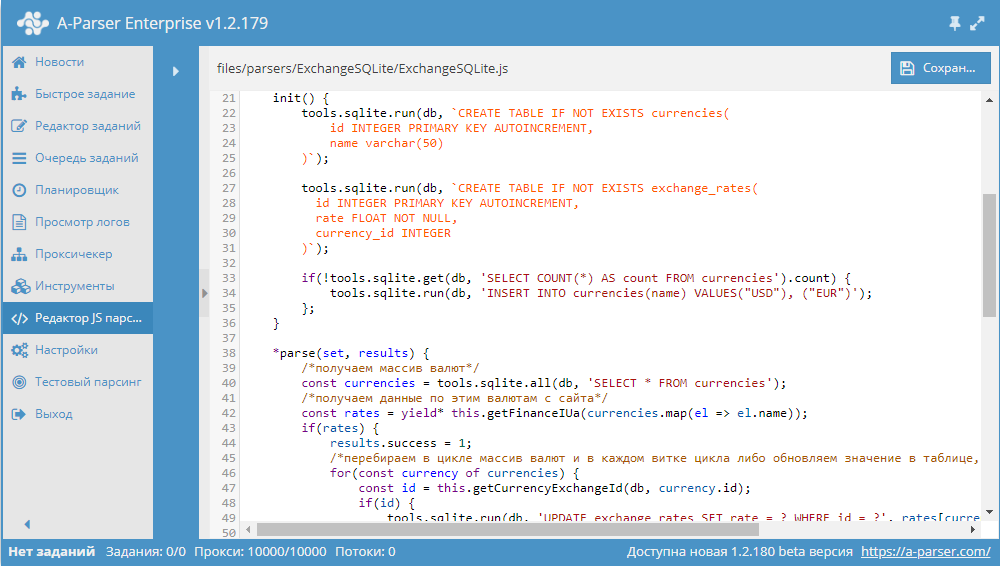
Начиная с версии 1.2.152 в A-Parser появилась возможность работать с БД SQLite.
В данной статье мы рассмотрим разработку JavaScript парсера, который будет парсить курсы валют из сайта finance.i.ua и сохранять их в БД. В результате получится парсер, в котором продемонстрированы основные операции с базами данных. Подробности, а также готовый парсер - по ссылке выше.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки :) ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 08.05.2018 12:08Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.185 - увеличение скорости в SE::Google::Modern, новые возможности Net:: DNS, множество улучшений

Улучшения- SE::Google::Modern - многократно увеличена скорость парсинга
- Множество улучшений в
 Net:: DNS:
Net:: DNS:- Возможность указать несколько DNS и задать метод выбора
- Бан нерабочих/плохих DNS по специальному эвристическому алгоритму
- Возможность вывести в результат использованный DNS сервер при удачном запросе
- В SE::Google::Modern добавлена опция Use sessions
- В SE::Yandex::WordStat добавлена настройка пресета антигейта для логина
- Также в SE::Yandex::WordStat удалены настройки Use logins/Use sessions, теперь они включены всегда
- Добавлена возможность автоматического удаления задания из Завершенных
- В макросе подстановок {num} добавлена поддержка обратного отсчета
- В JavaScript парсерах добавлена возможность сохранения произвольных данных в сессии
- В JavaScript парсерах добавлена возможность прямого сохранения в файл
- В API методе oneRequest/bulkRequest добавлена возможность указать configPreset
- В связи с неактуальностью удалены парсеры SE::Google::Mobile и SE::Yandex::Catalog
- Исправлен парсинг сниппетов в
 SE::Yandex
SE::Yandex - В SE::Google::Modern исправлена пагинация в мобильной версии, а также парсинг сниппетов и рекламы в некоторых случаях
- Исправлен парсинг цен в
 GooglePlay::Apps
GooglePlay::Apps - Исправлена работа функции Remove bad accounts в парсерах Wordstat
- Rank::MegaIndex,
 Rank::OpenSiteExplorer,
Rank::OpenSiteExplorer,  Rank::OpenSiteExplorer::Extended, SE:: DuckDuckGo, SE::IxQuick
Rank::OpenSiteExplorer::Extended, SE:: DuckDuckGo, SE::IxQuick
- Количество неудачных больше не обнуляется при постановке на паузу
- Исправлена проблема с подключением Node.js модулей на Linux
- Исправлено падение парсера в редких ситуациях при использовании JS парсеров
- Решена проблема с подключением Node.js модулей lodash, sequelize
- Исправлена ошибка итератора при равных границах в макросе {num}
- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 18.05.2018 12:28Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Разгадывание рекаптч в JS парсере
Очередное видео в цикле уроков по созданию JavaScript парсеров. Здесь показано, как реализовать разгадывание рекаптч в JS парсере.

В уроке рассмотрено:- Описание и настройка парсера
 Util::ReCaptcha2
Util::ReCaptcha2 - Описание принципа работы ReCaptcha2
- Создание кастомного JavaScript парсера с поддержкой разгадывания рекаптч
Ссылки:- Тестирование работы ReCaptcha2: http://http.myjino.ru/recaptcha/test-get.php
- Статья и готовый парсер: https://a-parser.com/resources/259/
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!- 0
- 29.05.2018 12:16Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Сборник рецептов #23: категории сайтов, парсинг в YML и преобразование дат
23-й сборник рецептов. В нем мы будем парсить категории сайтов из Google, научимся формировать файлы YML, а также разберемся, как парсить даты и преобразовывать их в единый формат. Поехали!
Получение категорий сайтов из Google
Категоризация сайтов - довольно актуальная задача, но существует немного сервисов, которые могут ее решить. Поэтому, по ссылке выше можно взять небольшой парсер, который позволяет получать категории сайтов из Google.
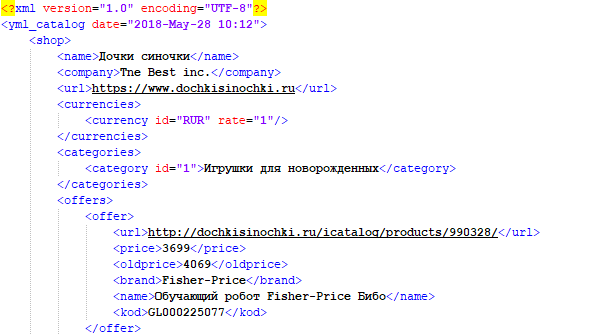
Выгрузка товаров в формате YML
YML - это стандарт, разработанный Яндексом для работы с Маркетом. По своей сути, это файлы, схожие с XML, в которых содержится информация о товарах в интернет-магазине. Данный формат обеспечивает регулярное автоматическое обновление каталога на Яндекс.Маркет и позволяет отражать все актуальные изменения (наличие, цена, появление новых товаров). Пример парсинга интернет-магазина и сохранения собранных данных в YML можно посмотреть по ссылке выше.
Парсим Google новости с датой и преобразуем ее
В поисковой выдаче Google возле новостей публикуется дата. Как правило, это могут быть метки "10 ч. назад" или "26 мая 2018 г.". Иногда может возникнуть задача спарсить все даты и привести их к единому виду. Как именно это сделать, можно узнать по ссылке выше.
Кроме этого:- Сохранение произвольных данных в сессиях - новый функционал по работе с сессиями
- Сохранение больших файлов напрямую на диск - возможность сохранять файлы в JS парсерах напрямую, минуя шаблонизатор
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники рецептов:- Сборник рецептов #1: Определяем CMS, оцениваем частотность ключевых слов и парсим Вконтакте
- Сборник рецептов #2: собираем форумы для XRumer, парсим email со страниц контактов
- Сборник рецептов #3: мобильные сайты, несколько парсеров, позиции ключевых слов
- Сборник рецептов #4: поиск в выдаче, парсинг интернет-магазина и скачиваем файлы
- Сборник рецептов #5: ссылки из JS, паблик прокси и карта сайта
- Сборник рецептов #6: парсим базу номеров телефонов и сохраняем результаты красиво
- Сборник рецептов #7: парсим RSS, качаем картинки и фильтруем результат по заголовкам
- Сборник рецептов #8: парсим 2GIS, Google translate и подсказки Youtube
- Сборник рецептов #9: проверяем сезонность ключевых слов и их полезность
- Сборник рецептов #10: пишем кастомный парсер поисковика и парсим дерево категорий
- Сборник рецептов #11: парсим Авито, работаем с JavaScript, анализируем тексты и участвуем в акции!
- Сборник рецептов #12: парсим Instagram, собираем статистику и делаем свои парсеры подсказок
- Сборник рецептов #13: сохраняем результат в файл дампа SQL и знакомимся с $tools.query
- Сборник рецептов #14: используем XPath, анализируем сайты и создаем комбинированные пресеты
- Сборник рецептов #15: анализируем скорость и юзабилити сайтов, парсим Яндекс.Картинки и Baidu
- Сборник рецептов #16: парсинг OpenSiteExplorer с авторизацией, Яндекс.Каталога и Яндекс.Новостей
- Сборник рецептов #17: картинки из Flickr, язык ключевых слов, список лайков в ВК
- Сборник рецептов #18: скриншоты сайтов, lite выдача Яндекса и проверка сайтов
- Сборник рецептов #19: публикация сообщений в Wordpress, парсинг Chrome Webstore и AliExpress
- Сборник рецептов #20: автообновление цен в ИМ, анализ текстов и регистрация аккаунтов
- Сборник рецептов #21: уведомления в Telegram из A-Parser, мультифильтр и парсинг IMDb
- Сборник рецептов #22: проверка индексации в нескольких ПС, многоуровневый парсинг и поиск сабдоменов
- 0
- 12.06.2018 12:07Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.216 - улучшения в SE::Google::Modern и JS парсерах, а также множество других

Улучшения- Зависимая задача в Цепочке заданий теперь запускается только когда файл результатов не пустой
- Добавлен повтор без смены прокси при неудачной отправке рекаптчи в SE::Google::Modern
- Добавлен бан прокси при получении 403 кода ответа в SE::Google::Modern
- Процент неудачных запросов теперь отображается относительно числа выполненных запросов
- Добавлена возможность вызвать URL после выполнения задания
- Улучшен обзор каталогов при выборе файлов запросов
- Добавлена поддержка setInterval в JavaScript парсерах
- Уменьшено Wait between get status и улучшено логгирование в Util::ReCaptcha2
- Улучшена обработка редиректов
- Добавлена защита от бесконечного выполнения в JavaScript парсерах
- Значительно увеличены возможности check_content в JS парсерах
- В ответе API метода info добавлены параметры workingTasks, activeThreads, activeProxyCheckerThreads
- Исправлен парсинг рекламы в мобильной версии SE::Google::Modern
- Исправлен парсинг количества результатов в
 SE::Baidu
SE::Baidu - Rank::MajesticSEO, SE::Google::Modern,
 SE::Google::Trends
SE::Google::Trends
- Исправлено ведение лога при нескольких паузах задания
- Исправлена ошибка, из-за которой запрос считался неудачным при пустой выдаче в SE::Google::Modern
- Исправлена работа с url, содержащими фрагмент # в
 Net::HTTP
Net::HTTP - Исправлен парсинг ссылок в
 HTML::LinkExtractor
HTML::LinkExtractor - Исправлена работа опции Pages count в SE::Yandex
- Исправлен выбор файлов запросов на Windows 10
- Исправлена ошибка, из-за которой иногда нельзя было удалить файл с запросами
- Исправлено отображение проксичекера в конфиге потоков
- Исправлена кодировка некоторых результатов в
 SE::Google::Suggest
SE::Google::Suggest - Исправлена ситуация, когда не читались настройки из config.txt
- 1
Спасибо сказали:
SeotopInUa(14.06.2018), - 14.06.2018 12:51Опытный

- Регистрация: 15.02.2012
- Сообщений: 413
- Репутация: 96
Использую Апарсер уже более 3х лет. Построил свой мини-сервис съема позиций и анализа конкурентов с парсером под капотом. Aparser очень помогает с множеством рутинных задач каждый день. Саппорт радует профессионализмом и оперативностью
 Рекомендую!
Рекомендую! - 0




Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 15:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
---------- adult blog camera canon html index inloto powershot prices vkontakte woocommerce администрация акция база блог быть вывод группа гугл домен запрос заработок импорт инстагор интервью каталоги статей кейс купить куча лайковый месяц необходимый общий очень покупка пользоваться помощь попасть править привет программа продвижение простой процент решить сайт сервис сертификат совет создание сообщение сообщество средство товар участвовать форум цвета цена часть
Тем:
77,609Сообщений:
763,461Пользователей:
30,082Сейчас на сайте:
0 пользователей и 338 гостей