Видео урок: Именование файлов результатов
Мы начинаем публикацию серии коротких видеоуроков, каждый из которых будет посвящен какому-то одному функционалу.
И в этом уроке будут рассмотрены варианты формирования имени файла результата.
В видео рассмотрено:
- Нумерация файла результата в соответствии с запросами
- Нумерация файла результата + часть имени запроса
- Именование файла результата по запросу, если запрос линк
Полезные ссылки:
- Формат результата - https://a-parser.com/wiki/tips-v1-1-0/#Формат-результата
- Шаблонизатор Template Toolkit - https://a-parser.com/wiki/template-toolkit/
- Метод replace - http://template-toolkit.ru/Manual/VMethods.html
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!

A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 338, Просмотров: 47410)
- 07.04.2020 16:20Опытный



- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
- 0
- 22.04.2020 19:54Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
1.2.852 - новый парсер для Google Keyword Planner, Native NodeJS, множество исправлений и улучшений

Улучшения- Добавлен парсер
 SE::Google::KeywordPlanner
SE::Google::KeywordPlanner- собираются списки подсказок и варианты ключевых слов
- для каждого варианта парсится среднее кол-во запросов в месяц, конкуренция, объемы поиска, а также минимальная и максимальная ставки
- присутствует возможность указывать несколько ключевых слов в запросе
- В
 SE::Yandex::ByImage добавлена функция Get full links to page, которая позволяет получать реальные ссылки на страницы
SE::Yandex::ByImage добавлена функция Get full links to page, которая позволяет получать реальные ссылки на страницы - В
 SE::Yandex::SQI добавлены переменные для сбора количества отзывов и оценок, а также рейтинга
SE::Yandex::SQI добавлены переменные для сбора количества отзывов и оценок, а также рейтинга - Улучшена проверка правильности разгадывания каптчи в парсерах Яндекса
- Автоматическое увеличение лимитов на ОС Linux
- Улучшена работа с регулярными выражениями
- При бане прокси в лог задания теперь выводится более детальная информация
- Native NodeJS переведена из стадии альфы в бету, проведено множество оптимизаций, за счет чего в большинстве сценариев это дает повышение максимальной скорости в 1.5-2 раза, а также уменьшение потребление памяти в 2-4 раза
- Начиная с 1.2.822 все бета версии имеют включенный Native NodeJS, стабильные версии выходят с включенным oldnode
- Native NodeJS: добавлена экспериментальная поддержка HTTP/2
- Native NodeJS: обновление Node.js до актуальной версии
- JS парсеры: добавлена опция allow_dangerous_node_modules, подробнее тут
- Исправлено скачивание каптчи в
 SE::Yandex
SE::Yandex - Исправлен
 Rank::Ahrefs: в $anchors переменная $bl заменена на $domains
Rank::Ahrefs: в $anchors переменная $bl заменена на $domains - В
 SE::Google исправлены:
SE::Google исправлены:- парсинг mobile news
- баг с дублированием ссылок в выдаче
- парсинг анкоров в рекламе, связанных ключевых слов, а также первый результат в выдаче не всегда попадал в serp
- В
 SE::Google::Images исправлен парсинг gif
SE::Google::Images исправлен парсинг gif - Исправлен SE::Yandex::ByImage, убраны flat переменные $height и $width
- SE::Yandex,
 SE::Google::ByImage,
SE::Google::ByImage,  SE::DuckDuckGo,
SE::DuckDuckGo,  Social::Instagram::Post, Rank::Ahrefs,
Social::Instagram::Post, Rank::Ahrefs,  Rank::Bukvarix::Domain,
Rank::Bukvarix::Domain,  SE::MailRu,
SE::MailRu,  SE::Yandex::Suggest
SE::Yandex::Suggest
- Исправлена работа
 Net::Whois с доменами 3го уровня, а также улучшена проверка получаемого ответа
Net::Whois с доменами 3го уровня, а также улучшена проверка получаемого ответа - Исправлена работа Extra query string в
 SE::Bing
SE::Bing - Исправлена работа
 Rank::SEMrush и
Rank::SEMrush и  Rank::SerpStat::Keyword при получении ответа без данных
Rank::SerpStat::Keyword при получении ответа без данных - Исправлен баг с типами переменных
- Исправлена ошибка, при которой запросы ошибочно считались неудачными при постановке задания на паузу
- Исправлена работа Bypass Cloudflare
- Исправлен динамический лимит потоков
- Исправлена ошибка при использовании Request delay
- Исправлено предупреждение о превышении лимита в Поле запросов
- Исправлена работа $tools.task.id в имени файла результата
- JS парсеры: исправлены получение сессий и работа http2 (баг появился в одной из предыдущих версий)
- JS парсеры: исправлено определение кодировки страницы
- Native NodeJS: исправлено поведение при некоторых ошибках
- Native NodeJS: исправлена проблема при обновлении A-Parser на OS Windows
- Native NodeJS: исправлена работа save_to_file, а также еще ряд ошибок
- Native NodeJS: исправлена работа SOCKS5 с авторизацией
- Native NodeJS: исправлена подстановка данных после Конструктора запросов

- 0
- 28.04.2020 15:19Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Сборник рецептов #40: посещаемость организаций, SSL сертификаты, ikea и анализ доменов
Представляем вашему вниманию 40-й сборник рецептов, в который вошли:- парсер данных о посещаемости организаций
- парсер данных о SSL сертификатах
- парсер товаров на ikea.com
- комплексный пресет для анализа доменов по ряду характеристик
- способ извлечения доменов из ссылок без фактического захода на страницу
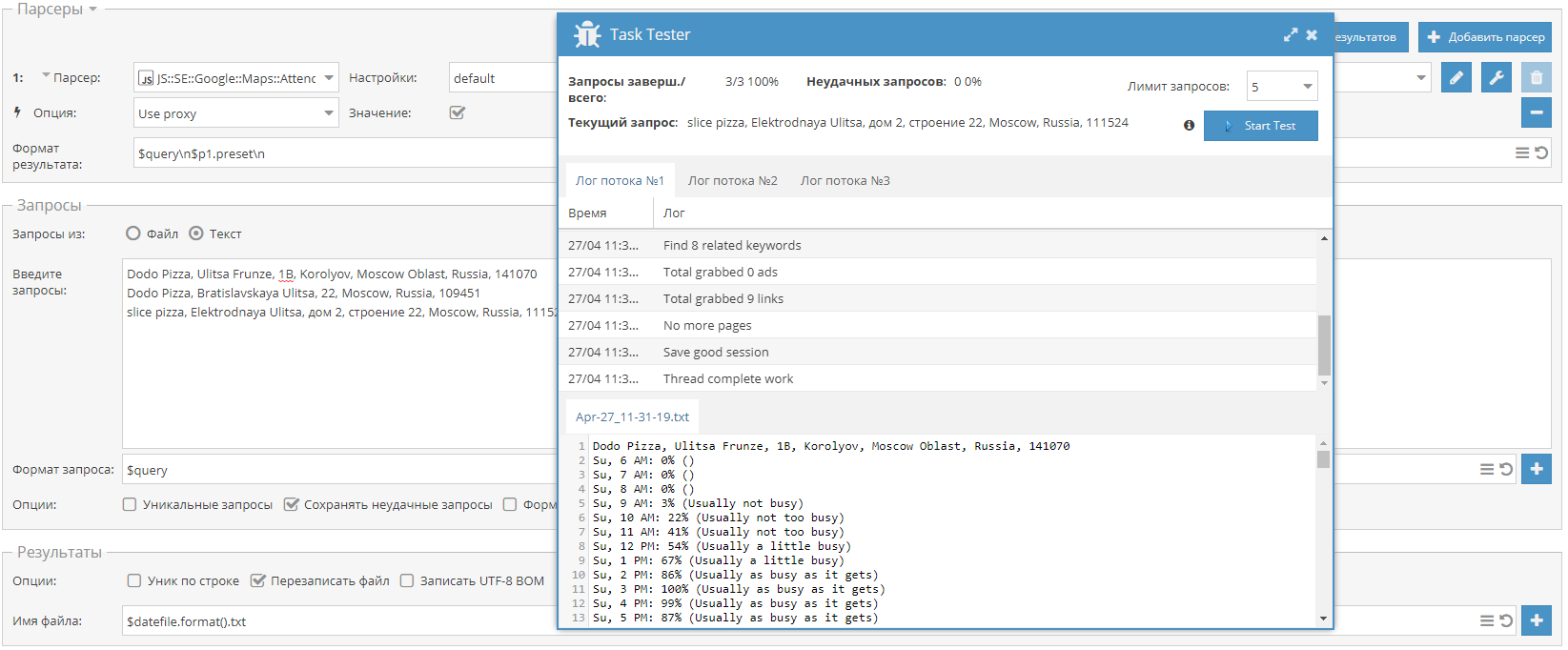
В поисковой выдаче Google для определенных запросов отображается расширенный сниппет с информацией об организации из Google карт. В частности, обычно отображается информация о посещаемости в разрезе дней недели.
Представляем парсер, который собирает данные о посещаемости.
Данные по SSL сертификату
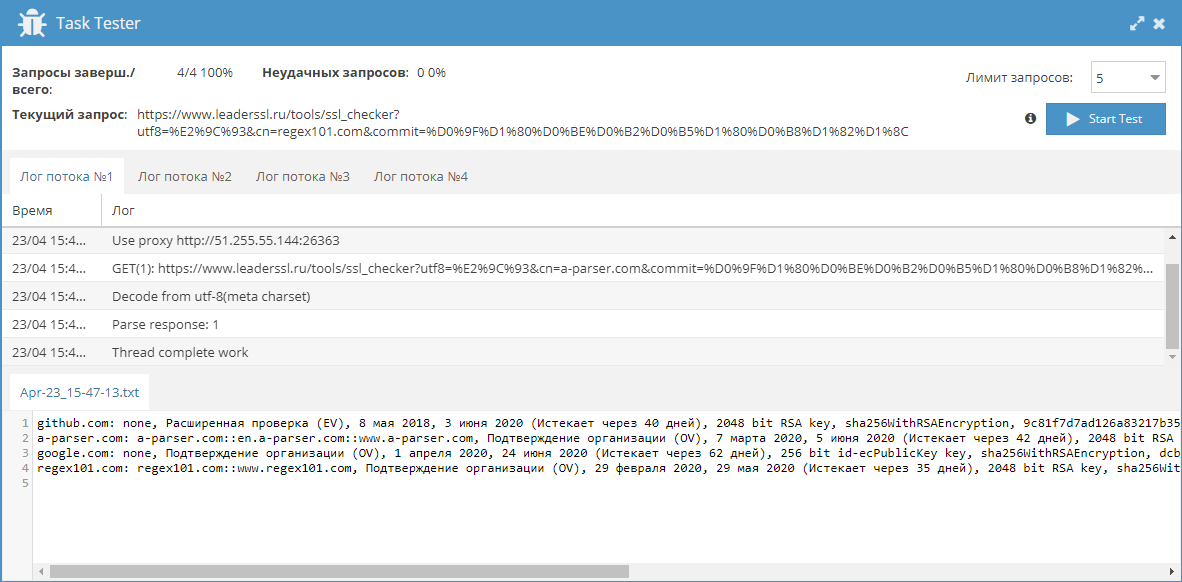
Данный парсер собирает информацию о SSL сертификате сайта. В качестве источника данных используется сторонний ресурс.
Парсер ikea.com
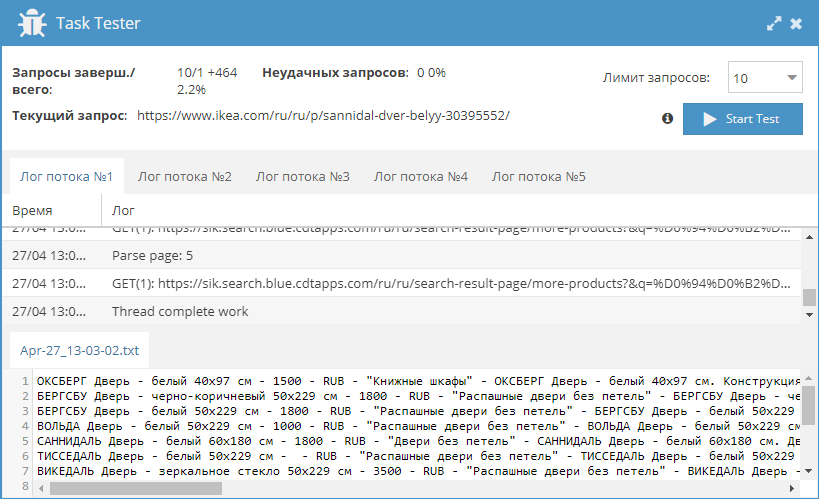
Парсер данных из ikea.com, который позволяет собирать различную информацию о товарах. Согласно данным из Википедии, ikea - это одна из крупнейших в мире торговых сетей по продаже мебели и товаров для дома.
Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники рецептов

- 0
- 08.05.2020 18:09Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Видео урок: Сохранение результатов в несколько файлов используя переменные, массивы и условия
В этом видео уроке рассмотрены способы сохранения результатов в несколько файлов, используя переменные и массив, при определенных условиях.
В видео рассмотрено:- Вывод результатов в разные файлы с разными именами используя переменные
- Вывод результатов для каждого файла отдельно по определенному условию
- Вывод результатов для двух файлов с условием, используя массив
- https://a-parser.com/wiki/template-toolkit/ - Шаблонизатор Template Toolkit
- http://template-toolkit.ru/Manual/Di...naya_obrabotka - условная обработка (IF, UNLESS, ELSIF, ELSE)
- http://template-toolkit.ru/Manual/Di...kaya_obrabotka - циклическая обработка FOREACH
- https://a-parser.com/wiki/task-tester/ - тестировщик заданий
- 0
- 18.05.2020 13:51Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Сборник рецептов #41: Google таблицы, отправка писем и авторизация с помощью puppeteer
Представляем 41-й сборник рецептов, который полностью посвящен использованию различных Node.js модулей в A-Parser.- Работа с Google таблицами
- Отправка писем из А-Парсера
- Авторизация с помощью puppeteer
Один из часто задаваемых вопросов в поддержке, это вопрос о возможности писать результаты прямо в Google Таблицы. Поэтому мы подготовили небольшой пример парсера, который демонстрирует такую возможность.

Отправка почтовых писем
Еще одна возможность, о которой часто спрашивают наши пользователи - отправка писем. Такой функционал может быть использован для уведомлений о различных событиях в заданиях, в том числе о завершении их работы. Поэтому мы также подготовили пример, демонстрирующий отправку писем прямиком из А-Парсера.
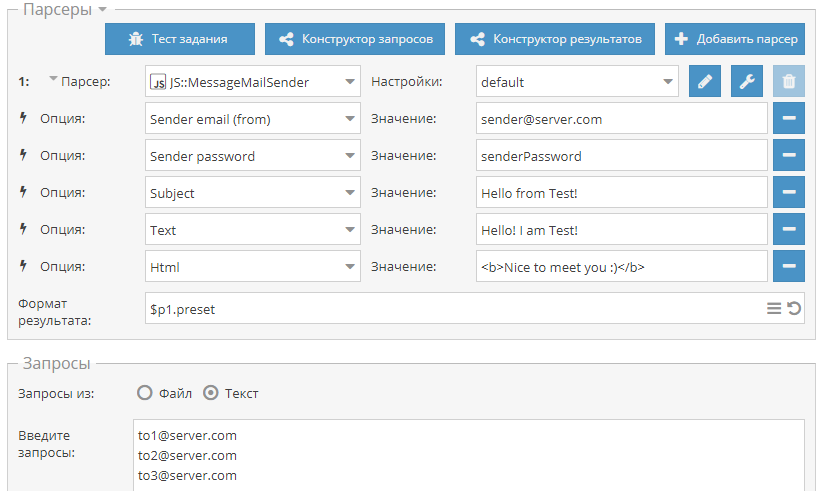
Авторизация на GitHub с использованием puppeteer
Еще один пример по заявкам наших пользователей, демонстрирующий загрузку страницы, авторизацию на ресурсе и простую навигацию.

Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники рецептов
- 0
- 11.06.2020 20:03Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
1.2.912 - обновление NodeJS, повышение производительности, адаптация к изменениям в рекаптчах

Мы завершили переход на NodeJS в качестве основного движка для парсеров и представляем новую стабильную версию 1.2.912 с поддержкой NodeJS 14.2.0. Данное обновление сочетает в себе множество улучшений, включая повышение производительности, уменьшение потребления памяти, полностью новый сетевой стек, а также поддержку нативных NodeJS модулей, позволяющую использовать всю мощь каталога npmjs в A-Parser'е
Также в данное обновление включены изменения по работе с ReCaptcha2 в парсере Google, наша команда одна из первых нашла решение по обходу новой версии рекаптчи и протестировала его совместно с сервисом RuCaptcha, за что им отдельный респект. На данный момент корректный обход каптчи протестирован с RuCaptcha, Anti-Captcha, XEvil и CapMonster.
Помимо этого было произведено множество оптимизаций в ядре A-Parser'а, значительно увеличилась производительность при использовании большого числа заданий или больших списков прокси. Парсер Rank::CMS был полностью переписан и стабилизирован, добавлена поддержка нового формата apps.json и поддержка пользовательских правил.
Rank::CMS был полностью переписан и стабилизирован, добавлена поддержка нового формата apps.json и поддержка пользовательских правил.
Улучшения- NodeJS обновлен до v14.2.0, v8 до 8.1
- Добавлена поддержка параметра data-s в рекаптчах для SE::Google, также добавлена опция ReCaptcha2 pass proxy
- Увеличен лимит потоков до 10000 для OS Windows
- Значительно улучшена производительность при большом числе активных прокси и/или заданий, полностью переписан стек по работе с прокси, оптимизирована работа с большими списками
- Добавлен новый парсер Rank::KeysSo
- Полностью переписаны на JS
 SE::Yahoo::Suggest,
SE::Yahoo::Suggest,  Rank::Alexa::API и
Rank::Alexa::API и  Rank::Archive
Rank::Archive - Улучшена производительность при использовании регулярных выражений, а также улучшена совместимость
- В SE::Google::KeywordPlanner добавлено автоматическое получение токена
- В SE::Bing добавлена возможность парсить ссылки на кэшированные страницы, а также добавлена возможность парсить мобильную выдачу
- В парсере
 Util::ReCaptcha2 при выборе провайдера Capmonster или Xevil теперь необязательно указывать Provider url
Util::ReCaptcha2 при выборе провайдера Capmonster или Xevil теперь необязательно указывать Provider url - В
 SE::Google::Trends добавлена возможность указывать произвольный диапазон дат
SE::Google::Trends добавлена возможность указывать произвольный диапазон дат - В Rank::CMS добавлен выбор движка регулярок и поддержка собственного файла с признаками
- В SE::Yandex::ByImage добавлена опция Don't sc**** if no other sizes, которая позволяет отключить сбор результатов, если искомой картинки нет в других размерах
- [NodeJS] Добавлена защита от бесконечных циклов и долгих регулярок
- [NodeJS] Исправлена работа this.cookies.getAll()
- [JS парсеры] Добавлена опция follow_meta_refresh для this.request
- [JS парсеры] Добавлена опция bypass_cloudflare для this.request
- [JS парсеры] Underscore заменен на Lodash
- [JS парсеры] В логе добавлена пометка при вызове других парсеров
- [JS парсеры] Использование предыдущего прокси после запроса к другому парсеру
- [JS парсеры] Добавлен метод destroy()
- Множество исправлений в SE::Google
- Исправлен
 SE::Youtube, в т.ч. парсинг по тегам
SE::Youtube, в т.ч. парсинг по тегам - Исправлен сбор ссылок в
 Shop::eBay
Shop::eBay - Исправлен парсинг телефонов в
 Maps::Google
Maps::Google - Исправлена работа с каптчами в SE::Yandex::ByImage
- В
 Rank::Social::Signal удалена переменная $facebook_comment в связи с неактуальностью
Rank::Social::Signal удалена переменная $facebook_comment в связи с неактуальностью  SE::Startpage,
SE::Startpage,  Rank::Linkpad, Social::Instagram:
Rank::Linkpad, Social::Instagram: ost,
ost,  SE::Yandex::Translate
SE::Yandex::Translate
- Исправлен баг, из-за которого игнорировался выбранный проксичекер
- Исправлена работа функций Decode HTML entities и Extract domain в Конструкторе результатов
- Исправлена проблема с определением кодировки
- Исправлена ошибка использования $tools.query
- Исправлен баг в
 Rank::MajesticSEO при котором использовались все попытки при отсутствии результатов
Rank::MajesticSEO при котором использовались все попытки при отсутствии результатов - Исправлена работа http2
- Исправлена ошибка, когда парсер падает из-за невозможности писать в alive.txt
- Исправлено разгадывание каптч в
 SE::Yandex::Register и
SE::Yandex::Register и  Check::RosKomNadzor
Check::RosKomNadzor - Исправлена разница в запросах, отправляемых через
 Net::HTTP и JS
Net::HTTP и JS - Исправлен баг в
 SE::Yahoo
SE::Yahoo - Исправлены ошибки в Rank::CMS при выборе приложения без категории
- [NodeJS] Исправлен подсчет времени исполнения кода парсера
- [JS парсеры] При пустом body не передавался заголовок content-length при post запросе
- [JS парсеры] Исправлена работа CloudFlare bypass
- [JS парсеры] Исправлена работа с сессиями
- [JS парсеры] Исправлена работа с overrides для this.parser.request
- [JS парсеры] Исправлена ошибка определения кодировки в JS парсерах
- 0
- 22.06.2020 15:34Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Сборник рецептов #42: поиск битых ссылок, сервисы статистики и коммерциализация запросов
Представляем 42-й сборник рецептов, в котором собраны парсеры для определения наличия на сайте битых ссылок, сбора данных об используемых сервисах статистики и определения коммерциализации ключевых слов.
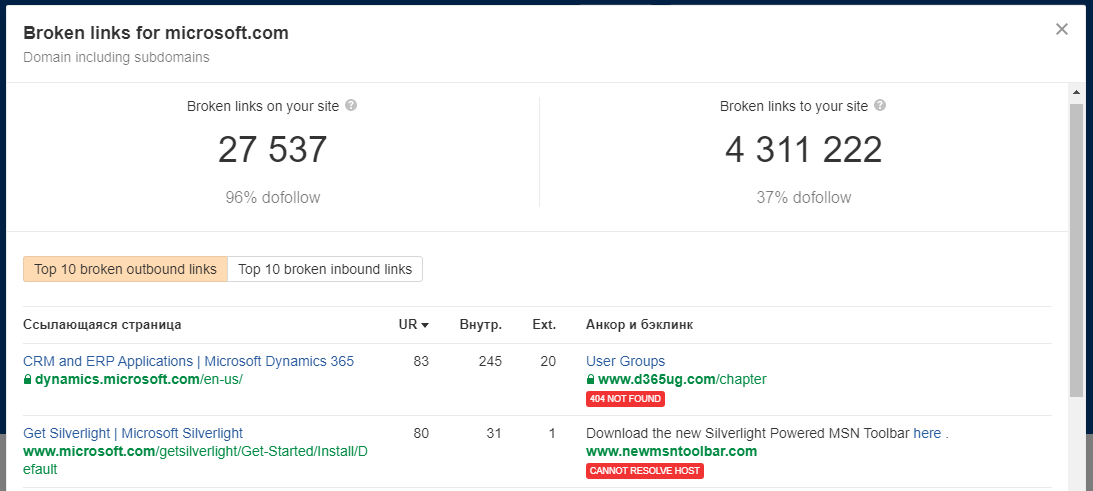
Парсер Ahrefs::BrokenLink
Ahrefs Broken Link Checker - это сервис, позволяющий определить наличие битых ссылок на сайте, а также некоторую другую полезную информацию.
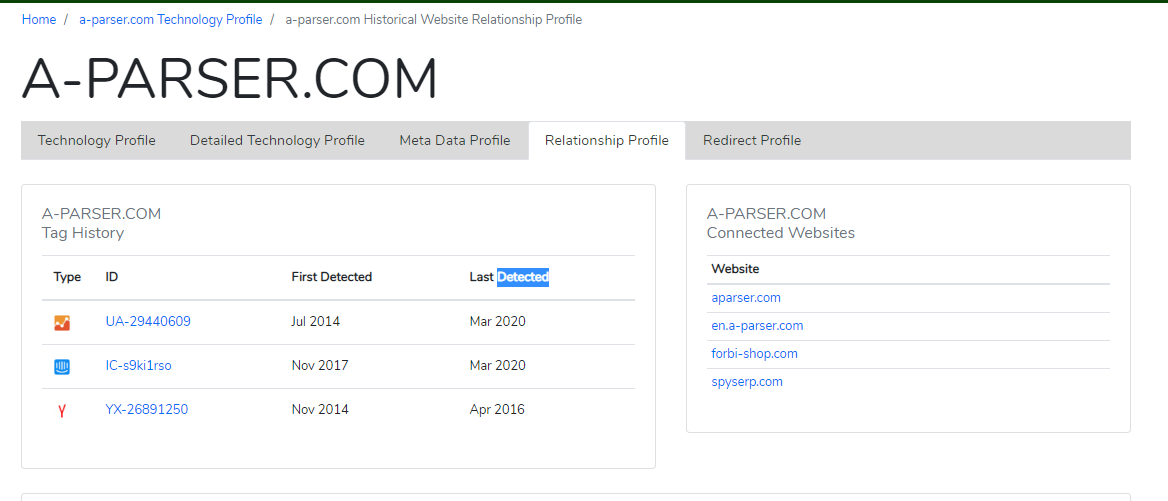
Парсер builtwith.com
Этот парсер собирает данные об используемых на сайтах сервисах статистики с ресурса BuiltWith. С его помощью можно получить список id используемых сервисов статистики, а также список других сайтов, на которых используются эти же id.
Определение коммерциализации запроса
Способ определения степени коммерциализации ключевых слов, основанный на анализе поисковой выдачи Яндекса. Оценивается количество вхождений определенного списка слов в анкорах и сниппетах ТОП10 выдачи.

Кроме этого:
Еще больше различных рецептов в нашем Каталоге!
Предлагайте ваши идеи для новых парсеров здесь, лучшие будут реализованы и опубликованы.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники рецептов
- 0
- 06.07.2020 19:11Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Видео урок: где смотреть переменные, скрытые переменные и какой результат они выводят (примеры)
В этом видео рассмотрели где смотреть переменные, какие бывают скрытые переменные и какой результат они выводят на примерах.
Содержание видео:
00:20 - 1. Где смотреть какие у парсера есть переменные?
1:16 - 2. Какие бывают скрытые переменные ($query.*, $root и т.п.)?
1:22 - переменная root
2:08 - переменная root объект
3:14 - переменная query.orig
4:04 - переменная query.first
5:24 - переменная query.lvl
5:50 - переменная query.prev
6:20 - переменная query.num
Все возможные методы TT для работы с обьектами
Форматирование запросов (шаблоны)
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!
- 0
- 16.07.2020 19:15Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
1.2.948 - новые парсеры SecurityTrails IP и Domain, поддержка доменных прокси, множество исправлений

Улучшения- Добавлен парсер
 Rank::MOZ.
Rank::MOZ.
Собираемые данные: вся информация, содержащаяся на странице. - Добавлены парсеры
 SecurityTrails:: Domain и
SecurityTrails:: Domain и  SecurityTrails::IP.
SecurityTrails::IP.
Для работы парсеров необходимо указать пресет Util::ReCaptcha2.- SecurityTrails::IP
В качестве запроса следует указывать ipv4 адрес.
Собирает домены по IP и информацию о них. - SecurityTrails:: Domain
В качестве запроса следует указывать домен, например a-parser.com.
Собираемые данные:- Данные по DNS
- Список технологий, используемых на сайте (движки и проч.)
- Список открытых портов
- Alexa rank
- Страна
- Хостер
- Даты начала и окончания регистрации
- Whois статус
- Регистратор
- Список исторических данных по DNS
- Список субдоменов
- Добавлена возможность отключать валидацию TLS сертификатов.
- Добавлена поддержка доменных прокси.
- Исправлен парсинг новостей в SE::Google.
- Исправлен
 Social::Instagram::Profile.
Social::Instagram::Profile. - Исправления в SE::Yandex:
- исправлен парсинг турбо ссылок;
- исправлен парсинг новостных сниппетов.
- Исправления в SE::Google,
 SE::Baidu,
SE::Baidu,  SE::Yandex:: Direct,
SE::Yandex:: Direct,  Shop::Yandex::Market.
Shop::Yandex::Market. - Исправления в SE::Yahoo - ошибка в выборе стран, у которых одинаковый домен, восстановлен парсинг сниппетов.
- Исправлена ошибка в алгоритме автовыбора домена в SE::Yandex.
- Исправлена работа Rank::MajesticSEO,
 SE::Bing::Translator.
SE::Bing::Translator. - Исправлена ошибка, если файл config.txt был сохранен в кодировке utf-8 с BOM (парсер некорректно читал файл).
- Решена проблема с переопределениями опций в парсере
 HTML::LinkExtractor.
HTML::LinkExtractor. - NodeJS: новые установленные модули теперь доступны до перезагрузки A-Parser'a.
- Исправлено падение парсера при вызове метода getProxies.
- 0
- 25.08.2020 17:53Опытный
- Регистрация: 17.08.2010
- Сообщений: 307
- Репутация: 23
Сборник статей #12: скорость работы парсеров, debug режим и работа с куками
В 12-м сборнике статей рассказывается о принципах работы парсеров и факторах, влияющих на их скорость, показаны возможности debug режима в Тестовом парсинге по отладке запросов, а также на реальном примере разбирается работа с куками.
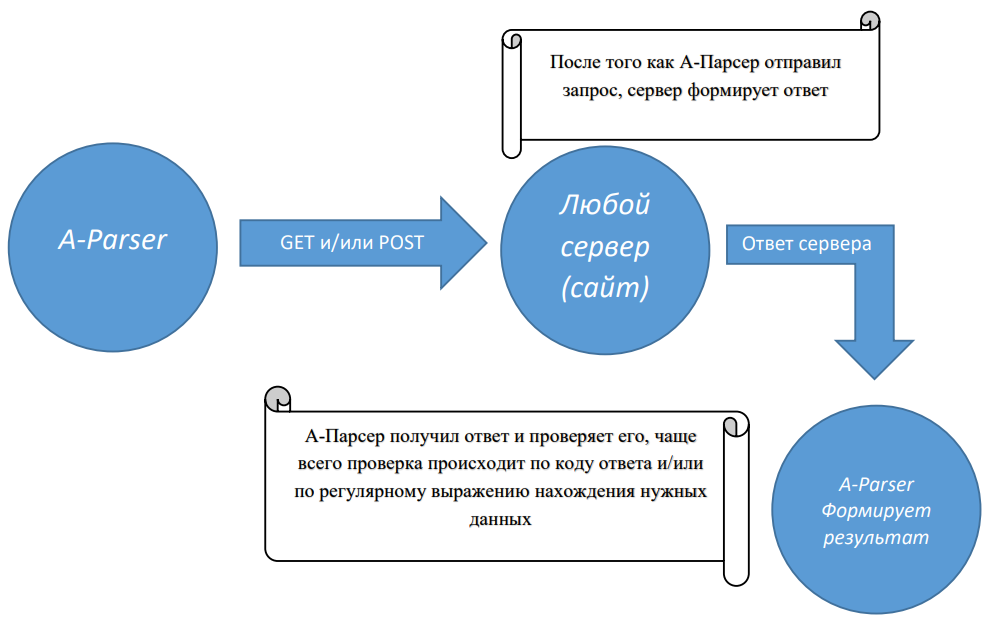
Скорость и принцип работы парсеров
В этой статье подробно рассказано об основном принципе работы парсеров и скорости их работы, а также рассмотрены основные факторы, влияющие на скорость парсинга.
Использование Debug режима
В этой статье рассказывается об одном из методов отладки парсеров, а также об анализе получаемых данных - debug режиме в Тестовом парсинге. С его помощью можно прямо в парсере анализировать и экспериментировать с заголовками и изучать приходящие в ответ данные.

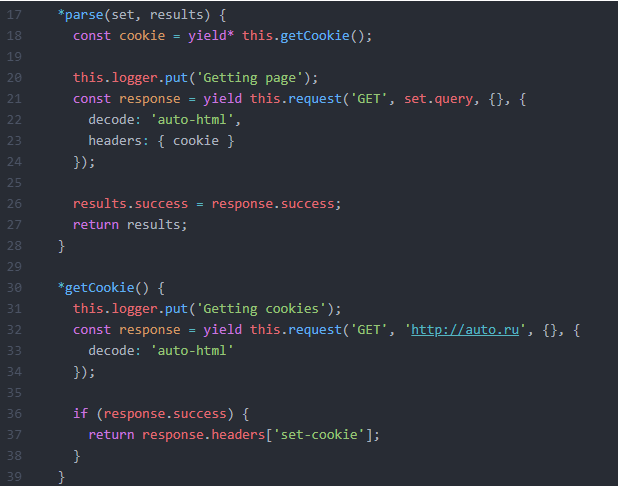
Работа с куками и заголовками на примере соглашения с правилами сайта auto.ru
А в этой статье на реальном примере показана работа с куками сайта: рассказано как определять необходимость передавать куки и как искать только необходимые для запроса куки. При этом показаны два варианта: простые запросы средствами А-Парсера и использование NodeJS модуля puppeteer.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки ) - отписывайтесь здесь.
) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Все сборники статей
- 0


Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 16:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
---------- admitad adsense adult avito cpa html parser proxy upnetwork woocommerce wordpress zennoposter аккаунт баннер бурж вконтакт вопрос гемблинг год группа гугл деть думать есть кейс ключ конечный контент магазин место может можно накрутка нужный отзыв очень партнёрка партнёрская программа пенсионный первый платир практик программа продажа продвижение прокси просто работать размещение рубль сайт сервис сеть стать страница тема цена шаблоны яндекс
Тем:
77,603Сообщений:
763,332Пользователей:
30,081Сейчас на сайте:
0 пользователей и 175 гостей