УлучшенияИсправления в связи с изменениями в выдачи
- Для Windows начат выпуск 64-битных сборок
- Переработан интерфейс выбора сохраненных заданий, теперь пресеты можно сортировать по папкам любой вложенности
- Реализована "ленивая" загрузка сохраненных пресетов
- В 64-битных windows/linux версиях обновлен JavaScript движок V8 до версии 6.3
SE::Bing::Translator полностью переписан, исправлена проблема, когда не переводился текст с html тегами и двойными кавычками, а также теперь переводятся большие тексты
- Добавлено автодополнение Provider url для CapMonster в
Util::ReCaptcha2
- Добавлена возможность парсинга Cloudflare protected e-mails в
HTML::EmailExtractor
- Добавлена сортировка JS парсеров внутри папок
- Уведомление о новой версии перенесено в статусбар
- Улучшена плавность при просмотре логов в Тестовом парсинге
Исправления
- Исправлена ошибка, когда выдавалась одинаковая выдача для всех страниц в
SE::Bing
SE:: DuckDuckGo ,
SE::AOL,
SE::Yandex::Images,
SE::Google::Modern,
- Исправлен баг, при котором список пресетов антигейта не обновлялся после создания нового
- Исправлены падения парсера при использовании удаленного пресета антигейта
- Исправлена работа через API при вызове сохраненного задания
- Исправлена ошибка с $followlinks в
HTML::LinkExtractor
- Исправлено определение кодировки на некоторых сайтах
- Исправлен подсчет неудачных запросов в некоторых случаях
- Исправлена ошибка с Custom template в фильтрах
- Исправлена работа кнопки Обновить в логах
- Исправлена ошибка Can't call method "Parser::HTML::Util::urlFromHTML", возникшая в одной из предыдущих версий
- Исправлены зависания при использовании уникализации в некоторых случаях
- Исправлена проверка обновлений после смены канала
A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 341, Просмотров: 51906)
- 04.12.2017 15:06Опытный



- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
- 0
- 26.12.2017 15:53Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.50 - улучшение стабильности, поддержка Xevil и множество исправлений в стандартных парсерах

Улучшения
- Уменьшение потребления памяти и улучшение стабильности работы x64 версий
- Добавлена поддержка 2captcha и Xevil в Util::ReCaptcha2
- Добавлен Parse all results и Parse related to level для SE::Bing
- В SE::Bing добавлена возможность задавать Safe Search, а также добавлен повтор запроса при получении кешированной "короткой" выдачи
- В
 SE::Yandex::Translate, добавлен обход ограничения на кол-во символов в запросе, что позволяет переводить очень большие запросы (>10k символов)
SE::Yandex::Translate, добавлен обход ограничения на кол-во символов в запросе, что позволяет переводить очень большие запросы (>10k символов) - В SE::Google::Modern добавлена возможность задать автоматическое определение языка интерфейса в зависимости от IP
- Движок V8 обновлен до версии 6.4
Исправления в связи с изменениями в выдаче- Исправлен парсинг сниппетов в SE::Google::Modern в некоторых случаях
 Check::RosKomNadzor, SE::AOL,
Check::RosKomNadzor, SE::AOL,  SE::Bing::LangDetect
SE::Bing::LangDetect
Исправления- Исправлена работа SE::Bing:
- устранена ситуация, когда выдавалась одинаковая выдача для всех страниц
- исправлена работа параметра Links per page
- исправлен парсинг количества результатов в некоторых ситуациях
- исправлена ошибка, при которой не было результатов, если в выдаче одна ссылка
- Исправлена работа с каптчей в
 SE::Yandex::Wordstat
SE::Yandex::Wordstat - Исправлена ошибка, когда при запросе с опечаткой SE::Google::Modern не забирал результаты с первой страницы
- Исправлена ошибка в
 Rank::MajesticSeo, при которой неправильно определялся бан IP
Rank::MajesticSeo, при которой неправильно определялся бан IP - В
 SE::Google::Trends исправлена работа при изменении формата результата по-умолчанию
SE::Google::Trends исправлена работа при изменении формата результата по-умолчанию - В SE::Google::Modern для Search from country изменен параметр: вместо cr теперь используется gl - это на данный момент позволяет более точно задавать регион
- Исправлена проблема с чрезмерным потреблением памяти в JavaScript парсерах
- Исправлена ошибка влияющая на стабильность работы на Linux и Windows
- Исправлена ошибка в
 SE::Yandex, при которой не было результатов, если в выдаче одна ссылка
SE::Yandex, при которой не было результатов, если в выдаче одна ссылка
Команда A-Parser поздравляет всех с Новым годом и Рождеством! Спасибо что вы с нами!- 0
- 09.01.2018 16:17Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Сборник статей #2: цикл статей-уроков по созданию JS парсеров
Как известно, в A-Parser есть возможность создавать свои собственные парсеры, которые могут иметь практически любую логику и в то же время позволяют пользоваться всеми преимуществами А-Парсера. Для написания таких парсеров используется язык JavaScript. В нашей документации подробно описаны все функции и методы, которые можно использовать при написании парсеров. А в сегодняшнем сборнике мы на практических примерах покажем наиболее часто применяемые функции. Поехали!
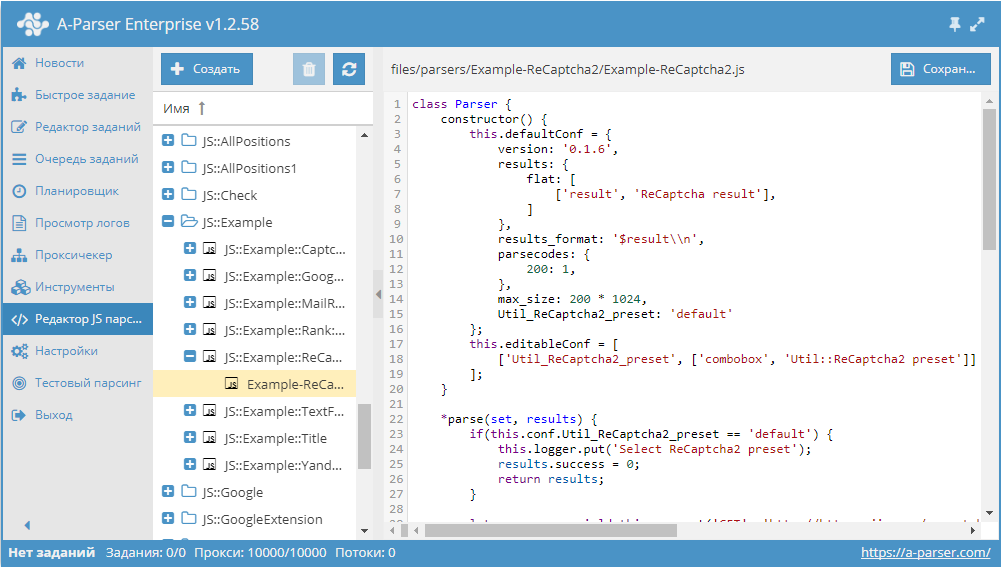
- Получение результатов от стандартного парсера.
В этой статье описано использование функции yield this.parser.request, которая позволяет работать с уже существующими парсерами, получать от них данные и дополнительно обрабатывать их. - Парсинг сайта с проходом по страницах.
Здесь показан общий подход к созданию парсера, который будет "ходить" по страницам на сайте и забирать с них некоторую информацию. - Парсинг title и description для топ10 сайтов по запросу.
В данном примере показано как написать собственный парсер, который объединит в себе две разных задачи: парсинг топ10 сайтов и парсинг данных из каждого полученного сайта. При этом также будет показана возможность реализации выбора между несколькими поисковиками, что делает такой парсер еще более универсальным. - Реализация подстановки запросов и их многопоточной обработки.
Этот пример продемонстрирует, как "на лету" добавлять запросы с помощью tools.query.add, а также, как обрабатывать их в многопоточном режиме. - Работа с CAPTCHA.
В этой статье на простом примере будет показан общий подход к работе с сайтами, на которых появляется каптча. Будет пошагово разобран алгоритм и продемонстрирован результат работы. - Работа с ReCaptcha2.
А в этом примере по аналогии с обычной каптчей демонстрируется алгоритм работы с рекаптчей, а также вкратце поясняется принцип ее действия.
Для каждой статьи в конце будет продемонстрирован результат работы и дана ссылка на готовый парсер.
Если вы хотите, чтобы мы более подробно раскрыли какой-то функционал парсера, у вас есть идеи для новых статей или вы желаете поделиться собственным опытом использования A-Parser (за небольшие плюшки :) ) - отписывайтесь здесь.
Подписывайтесь на наш канал на Youtube - там регулярно выкладываются видео с примерами использования A-Parser, а также следите за новостями в Twitter.
Предыдущие сборники статей- 0
- 24.01.2018 12:26Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.78 - поддержка сессий в JS парсерах, улучшение SE::Google::Modern, правки в интерфейсе

Улучшения
- Добавлена поддержка сессий в JavaScript парсерах
- В SE::Google::Modern добавлена поддержка сессий и улучшена производительность за счет уменьшения частоты появления каптч/рекаптч
- Добавлена переменная $query.prev - показывает запрос, который использовался на предыдущем уровне
- Для JS парсеров добавлен метод this.logger.putHTML, который позволяет вывести в лог HTML код
- В Lite версию добавленSE::Google::Modern и Util::ReCaptcha2
- В x86 версиях добавлено предложение перейти на x64
- Добавлена возможность переименовывания пресетов
- В окне выбора пресета для папок реализована "память на сворачивание"
- Изменены иконки для JS парсеров
- Исправлены ошибки с переводом в интерфейсе
- Исправлено отображение HTML тегов в логах
- Исправлен баг при импорте с вложенным парсером
- Исправлен баг с прокруткой при сохранении JS парсеров и пресетов
- Доработан Конструктор регулярных выражений
- Другие мелкие правки в интерфейсе, направленные на улучшение общей работы
Исправления в связи с изменениями в выдаче
- В SE::Google::Modern исправлен парсинг сниппетов и рекламы, а также мобильной выдачи
- В
 SE::Google::Suggest исправлен парсинг подсказок, а также добавлена опция Remove HTML tags, позволяющая получать подсказки с или без html тегов
SE::Google::Suggest исправлен парсинг подсказок, а также добавлена опция Remove HTML tags, позволяющая получать подсказки с или без html тегов - Исправлен парсинг анкоров и сниппетов в SE :: DuckDuckGo
 SE::Ask,
SE::Ask,  SE :: Dogpile,
SE :: Dogpile,  Rank::Mustat
Rank::Mustat
Исправления
- Исправлен баг с перемещением заданий в очереди
- В SE::Google::Modern исправлен баг с кодировкой
- Исправлена работа параметров Request delay и Extra query string во всех JS парсерах
- Исправлен выбор файлов запросов
- Исправлено отображение иконок для JS парсеров
- 0
- 01.02.2018 17:43Опытный

- Регистрация: 15.02.2012
- Сообщений: 413
- Репутация: 96
Пользуюсь софтом более 2х лет. Уже кучу сервисов наваял под капотом которых пыхтит A-parser. Не представляю себе работу без атоматизации и такой масштабируемости как с данным парсером.
Отдельно хочу отметить качественную работу саппорта и активную помощь в решении нестандартных задач.
- 0
- 03.02.2018 19:49Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Видео урок: Создание JS парсеров. Получение результатов от стандартного парсера
Это видео начинает цикл уроков по созданию JavaScript парсеров. Здесь рассказано о том, как начать писать собственные парсеры, используя функционал JS парсеров в А-Парсере.

В уроке рассмотрено:- Создание кастомного JS парсера
- Использование встроенного парсера внутри JS парсера
- Парсинг выдачи поисковой системы с фильтрацией результатов по заданному условию
- https://learn.javascript.ru/generator
- https://developer.mozilla.org/ru/doc...and_Generators
- https://developer.mozilla.org/ru/doc...perators/yield
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!- 0
- 14.02.2018 12:10Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Видео урок: Создание JS парсеров. Парсинг сайта с проходом по страницах
Второе видео в цикле уроков по созданию JavaScript парсеров. Здесь рассказано о том, как написать несложный парсер сайта, который будет "листать" страницы, используя функционал JS парсеров в А-Парсере.

В уроке рассмотрено:- Создание кастомного JavaScript парсера без использования встроенных парсеров
- Парсинг контента сайта постранично с использованием регулярных выражений
- Реализация прохода по страницам ("пагинации") в JS парсере
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!- 0
- 23.02.2018 15:16Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
1.2.138 - поддержка Node.js модулей, обработка ReCaptcha2 во всех парсерах Google, парсер AliExpress

В A-Parser 1.2.138 добавлена эмуляция node версии 8.9.x с поддержкой загрузки модулей и частичной реализацией fs и net модулей. Это дает возможность обращаться из JavaScript парсеров напрямую к файловой системе, а также использовать подключение по TCP из модулей к другим сервисам(например mysql, redis, chrome...).
Все это позволило загружать и использовать node модули из каталога npm, в котором собраны множество полезных библиотек для обработки данных, коннекторы к базам данных и множество других интересных вещей. На данный момент протестированы следующие модули: md5, async-redis, jsdom, puppeter.
Улучшения- Добавлена поддержка Node.js модулей в JavaScript парсерах
 SE::Google::Position,
SE::Google::Position,  SE::Google::Compromised и
SE::Google::Compromised и  SE::Google::TrustCheck полностью переписаны, добавлена поддержка ReCaptcha2
SE::Google::TrustCheck полностью переписаны, добавлена поддержка ReCaptcha2- Улучшена работы SE::Google::Modern в целом
- В
 SE::Youtube добавлен выбор языка, а также реализована возможность включать/отключать Безопасный режим
SE::Youtube добавлен выбор языка, а также реализована возможность включать/отключать Безопасный режим - Добавлен
 Shop::AliExpress
Shop::AliExpress - Улучшена проверка создаваемых переменных в пресетах
- Улучшена работа сессий
- Исправлено отображение имени файла запроса на карточке задания
- Улучшена работа скрола в Тестовом парсинге
- Добавлено удаление переносов из сниппетов в SE::Google::Modern
- Картинка каптчи в парсере
 SE::Yandex::Register теперь скачивается через прокси
SE::Yandex::Register теперь скачивается через прокси - Множество мелких улучшений в интерфейсе
- Исправлена работа SE::Youtube при переопределении опции Result type
- Исправлен многостраничный парсинг в SE::Bing
- Полностью переписан SE::Yandex::Register, добавлена возможность выводить ответ на секретный вопрос
- Исправлена проверка следующей страницы в
 SE::Seznam
SE::Seznam - Устранена ситуация, когда в
 SE::Yandex::Position парсилась неполная ссылка
SE::Yandex::Position парсилась неполная ссылка - Исправлен подсчет неудачных запросов в SE::Google::TrustCheck и SE::Google::Compromised
 SE::Yandex:: Direct,
SE::Yandex:: Direct,  Shop::Yandex::Market
Shop::Yandex::Market
- Исправлена работа Конструктора регулярных выражений
- Исправлена работа с кодировками в парсерах переводчиков и JS парсерах
- Исправлена работа SE::Google::Position
- Исправлен выбор региона в SE::Yandex:: Direct
- Исправлена работа опции Location в SE::Google::Modern
- Исправлена работа сессий в SE::Google::Modern при переопределенном домене
- Исправлена ошибка при совместном использовании опций Перезаписи файла, Начального и Конечного текстов
- Исправлено отображение вкладок в Тесте задания
- Исправлено отображение списка пресетов в поле Запустить по завершению
- Исправлена работа this.proxy.set в JS парсерах
- Исправлена передача дополнительных параметров в JS парсерах
- Исправлена ошибка, из-за которой через API нельзя было указать Начальный и Конечный тексты
- Исправлен экспорт пресетов
- 0
- 06.03.2018 12:17Опытный
- Регистрация: 17.08.2010
- Сообщений: 310
- Репутация: 23
Использование Xevil совместно A-Parser для разгадывания ReCaptcha2

Как известно, сейчас Google при парсинге очень часто выдает рекаптчу, что значительно усложняет и замедляет сбор данных.
В A-Parser есть возможность обходить данную проблему, разгадывая рекаптчу с помощью сторонних сервисов. Поддерживаются различные онлайн сервисы, а также программные решения.
Одним из таких решений есть XEvil. Его использование дает хороший прирост в скорости, а также значительно удешевляет парсинг, ведь здесь нету оплаты за количество разгаданных каптч/рекаптч, как в онлайн сервисах. Кроме этого, XEvil умеет разгадывать практически любые обычные каптчи (в виде картинки) и данная возможность также поддерживается в A-Parser.
На данный момент использовать разгадывание рекаптчи с помощью XEvil можно в таких парсерах:- SE::Google::Modern
- SE::Google::Position
- SE::Google::TrustCheck
- SE::Google::Compromised
 Rank::MegaIndex
Rank::MegaIndex- а также любые кастомные JavaScript парсеры
В видео показано:- подключение Xevil к A-Parser для работы с ReCaptcha2
- проверка работы и демонстрация работы в SE::Google::Modern
Ознакомиться более детально с возможностями XEvil можно по ссылкам:
Оставляйте комментарии и подписывайтесь на наш канал на YouTube!- 0


Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 16:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
---------- adult camera forum google html proxy woocommerce zennoposter акция база блог было быть вечный вконтакт вывод гугл добавить домен запрос заработок импорт использовать кейс купить куча модератор общий одноклассник очень платить покупка пользоваться помощь попасть править программа продвижение работать ребёнок регистрация решить сайт сбор сервис создание сообщение средство стать тематика товар трафик участвовать форум форумчаны халява хороший цвета яндекс
Тем:
77,607Сообщений:
763,435Пользователей:
30,081Сейчас на сайте:
0 пользователей и 493 гостей