1.1.712 - новогодняя юбилейная 100-ая версия, JavaScript парсеры
Всех с наступающим новым годом! Участвуйте в конкурсе и получайте бесплатные лицензии, но об этом ниже
Сегодня я хочу вам представить юбилейную 100-ую версию A-Parser'a! Да, мы выпустили ровно 100 версий за почти 5 лет существования нашего парсера. Разработка парсера никогда не останавливается, сейчас он буквально пухнет от возможностей! Это хорошо подчеркивает все принципы и подходы заложенные в A-Parser еще в далеком 2012 году.
Одно из главных новшеств новой версии - JavaScript парсеры, теперь каждый кто обладает хотя бы минимальными знаниями программирования сможет создавать высокопроизводительные парсеры на языке JavaScript используя все возможности A-Parser'а(многопоточность, работу с прокси, шаблонизатор, обработка запросов и результатов, и многое другое)
A-Parser давно перестал быть просто парсером, на сегодняшний день это полнофункциональная платформа для сбора информации в промышленных масштабах, которая позволит вам собирать информацию из самых разных источников и множеством разных способов. В следующем году вас ждет еще больше новых возможностей, следите за новостями!
УлучшенияИсправления в связи с изменениями в выдачи
- JavaScript парсеры - возможность создавать свои парсеры используя все преимущества A-Parser
- JS парсеры: возможность получить и установить Cookies
- JS парсеры: мютекс для синхронизации между потоками
- JS парсеры: возможность использования инструментов tools
- JS парсеры: поддержка запросов к другим парсерам
- Множественные оптимизации всех парсеров, обработке подвергаются только те элементы страницы которые необходимы в результатах парсинга
- В парсере
HTML::TextExtractor будут игнорироваться блоки меню без текста
- В парсере
SE::Google::Compromised добавлена возможность проверки подозрительных сайтов по всем страницам
- API: добавлена возможность получить количество активных аккаунтов(для Яндекса)
- API: при выставленном флаге rawResults будут передаваться все доступные результаты
- Убрана настройка Raw data results, теперь необходимость этих результатов определяется автоматически
- Добавлена возможность работы с одним прокси сервером(параметр Reuse proxy beetwen retries)
- Если ошибка в шаблонизаторе произошла во время парсинга она будет записана в лог
- В парсере
SE::YouTube не собиралась выдача
- В парсере
SE::Bing не парсилось количество результатов для новостей
- В парсере
SE::Google не собирались рекламные блоки
- В парсере
SE::Yandex некоторые позиции в выдаче могли пропускаться
- В парсере
SE::Yandex::Register исправлена обработка ошибок регистрации
Исправления
- Исправлена ошибка с обработкой запросов вне рабочего каталога A-Parser, что в некоторых случаях могло привести к проблемам с безопасностью
- В парсере
SE::Yandex::WordStat в редких ситуациях могла зациклиться работа с одним прокси
- В парсере
Net::HTTP не корректно работала опция Check next page при редиректе на другой URL
- Исправлена проблема с работой
Net::DNS на ОС Linux x64
- Исправлен вывод ошибок в логе при уникализации "не доменов"
- Исправлена работа парсера
HTML::TextExtractor::LangDetect
- Исправлен парсер
Check::BackLink, ошибка появилась в предыдущей версии
- Не выводились внешние переменные в методе .format, ошибка появилась в предыдущей версии
Напоминаем, что мы разыгрываем 3 лицензии на A-Parser общей стоимостью $437, участвуйте в конкурсе, победитель будет выбран 5ого января 2017!
A-Parser - продвинутый парсер поисковых систем, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(Ответов: 341, Просмотров: 52125)
- 26.12.2016 16:33Новичок

- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
- 0
- 05.01.2017 14:11Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
Доброго времени суток друзья! Команда A-Parser поздравляет вас с наступившим 2017 годом и наступающим Рождеством.
Не забывайте о нашем розыгрыше https://vk.cc/5YBNVX. Мы разыграем сегодня 3 лицензии на A-Parser общей стоимостью $437. Результаты розыгрыша после 17:00 по Москве. Более подробную информацию смотрите по ссылке которая указана выше.

- 0
- 16.01.2017 14:01Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
1.1.726 - новые возможности планировщика, множество исправлений

Улучшения
- В планировщик добавлена возможность ежемесячного запуска заданий, с возможностью выбрать определенный день месяца
- В планировщике теперь можно указать уникальность задания, если задание активно в очереди то при попытке его запуска через планировщик оно будет отложено до следующего запуска
- Файл логов задания теперь удаляется одновременно с удалением задания
- В тестовом парсинге улучшен дебагер и предпросмотр HTML кода
Исправления в связи с изменениями в выдачи- SE::YouTube,
 Rank::DMOZ,
Rank::DMOZ,  Rank::Mustat,
Rank::Mustat,  SE::Dogpile,
SE::Dogpile,  SE::Ask,
SE::Ask,  SE::AOL
SE::AOL
Исправления
- В парсере
 Net::Whois исправлен парсинг дат для множества доменных зон
Net::Whois исправлен парсинг дат для множества доменных зон - Функция добавления ! перед каждым словом(для снятия частотности по WordStat) в некоторых случаях работала некорректно
- Исправлена ошибка при работе прокси с использованием только одной попытки(Request retries)
- Исправлена ошибка при которой парсер падал при неверно составленном Конструкторе результатов
- В некоторых случаях использование XPath могло приводить к зависанию парсера
- В парсере
 SEO::Ping исправлена обработка ответов для некоторых сервисов
SEO::Ping исправлена обработка ответов для некоторых сервисов - В некоторых случаях ошибка задания могла отображаться некорректно
Так же, мы хотели бы ещё раз поздравить наших победителей которые получили лицензии A-Parser'a: Сергея Чернова, Романа Лисина и Илью Нечаева. Поздравляем вас ещё раз!
- 0
- 01.02.2017 14:50Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
В этом видео вы узнаете как собрать тысячи и миллионы профилей в социальной сети ВКонтакте:
В уроке рассмотрены:- Создание парсера профилей соцсети ВКонтакте: имя, город, телефон, семейной положение, время последнего захода и ссылку на аватар(фотографию)
- Использование регулярных выражений для фильтрации данных результата
- Использование конструктора результатов для модификации результатов
- Использование Cookies в запросах
Подписывайтесь на наш канал, ставьте лайки и оставляйте в комментариях пожелания для следующих уроков!- 0
- 08.02.2017 12:50Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
1.1.743 - исправлен парсер Яндекса, множество исправлений в JavaScript парсерах

В версии 1.1.743 выпущено множество исправлений для JavaScript парсеров, а также добавлены новые примеры: определение языка страницы через Яндекс переводчик и сбор текстовки по ключевому слову одним заданием(на выбор через Google или Яндекс)
Улучшения- В JavaScript парсерах добавлена возможность создавать новые запросы(this.query.add)
- В парсере
 SE::Yahoo теперь определяется бан прокси по IP
SE::Yahoo теперь определяется бан прокси по IP - Добавлен параметр, позволяющий A-Parser'у работать с файлами запросов и результатов вне рабочего каталога
- SE::Yandex - парсил только первую страницу выдачи
 SE::Google::Trends - использовал все попытки если по ключевому слову не было данных
SE::Google::Trends - использовал все попытки если по ключевому слову не было данных
- Исправлена работа опции Max threads per proxy(максимальное число потоков на одну прокси)
- В парсере
 HTML::LinkExtractor исправлен парсинг ссылок с фрагментом(#)
HTML::LinkExtractor исправлен парсинг ссылок с фрагментом(#)
- Настройки checkbox воспринимались некорректно
- Исправлена ошибка в работе this.cookies.setAll
- В интерфейсе не отображались измененные параметры конфига
- Исправлены утечки памяти
- Исправлено игнорирование параметра success
- Исправлено поведение при использовании Override настроек
- Исправлена ошибка при получении результатов из другого парсера
- 0
- 27.02.2017 13:16Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
1.1.764 - шаблонизатор в полях конфига, выбор языка в SE::Bing
Улучшения
- В парсер SE::Bing добавлена возможность выбора языка результатов поиска
- Во всех полях конфигурации каждого парсера теперь есть возможность использовать шаблонизатор, тем самым позволяя использовать запрос или его часть как значение конфига, а также добавлять произвольную логику(пример - использование переменного DNS сервера)
- В JavaScript парсерах добавлена возможность установки одиночного cookie(this.cookies.set)
- В парсере SE::Yandex::WordStat SE::Yandex::WordStat уменьшено потребление каптчи
Исправления в связи с изменениями в выдачи- SE::Google - исправлена работа с антигейтом
- В парсере SE::Google исправлен парсинг объявлений, а также пропуск первого результата поиска в редких случаях
- В парсере SE::Yandex исправлен сбор сниппетов
- SE::AOL,
 SE::Bing::Images
SE::Bing::Images
Исправления
- Исправлена утечка памяти при использовании логов в задании
- В парсере SE::Ask не определялся бан прокси
- Исправлена работа опции allow_outside_files
- Исправлена работа с utf8 в исходниках tools.js и JavaScript парсерах
- В редких случаях при неудачном парсинге 2ой или последующих страниц запрос мог считаться успешным
- 0
- 24.03.2017 17:44Опытный

- Регистрация: 15.02.2012
- Сообщений: 413
- Репутация: 96
Являюсь пользователем aparser-а уже 3й год и полностью доволен как полнотой функционала, так и частотой обновлений. Рекомендую всем!
Из того, что мне необходимо и парсер мне в этом помогает:
- парсинг битых ссылок и мета-тегов на страницах клиентских сайтов;
- сбор тематических баз для расстановки ссылок;
- парсинг почт, телефонов и т.п. с популярных социалок, каталогов и порталов;
- парсинг и наполнение ИМ описаниями товаров;
- парсинг несуществующих аккаунтов (профилей) с беками на трастовых ресурсах для дальнейшей регистрации и создания своих сеток; (в наличии база на 700+ качественных и активнонаполняющихся твиттер аккаунтов. Во времена отображения тулбарного PR находил аккаунты с PR5-7 и успешно их использовал...);
- парсинг текстовок/сниппетов;
И это только малая часть того, в чем апарсер мне помогает в повседневной рутине На самом деле можно реализовать довольно сложные парсеры/чекеры - но, это уже другая история...
На самом деле можно реализовать довольно сложные парсеры/чекеры - но, это уже другая история... - 1
Спасибо сказали:
Forbidden(24.03.2017), - 27.03.2017 13:16Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
1.1.790 - экспорт множества заданий и JavaScript парсеров

A-Parser 1.1.790 появился новый экспорт, который позволяет экспортировать сразу несколько заданий, настройки парсеров, JavaScript парсеры, а также tools.js:
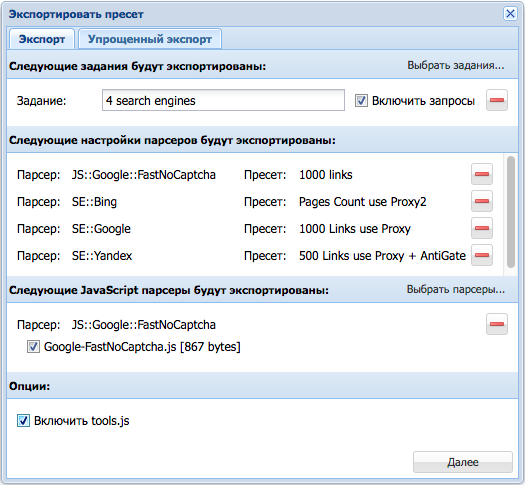
Улучшения
- Новый экспорт заданий
- В JavaScript парсерах добавлена возможность указать иконку парсера
- В JavaScript парсерах добавлен функционал для работы с CAPTCHA
- Добавлено автоматическое версионирование JavaScript парсеров
- В хедерах ответа теперь указан заголовок Proxy с которым был сделан запрос
- В JavaScript парсерах добавлен параметр attempt для this.request, позволяющий вручную управлять механизмом попыток
- В JavaScript парсерах добавлен функционал управления прокси
- В парсере Check::BackLink улучшена обработка nofollow
Исправления в связи с изменениями в выдачи
-
 SE::DuckDuckGo, SE::Ask, SE::AOL,
SE::DuckDuckGo, SE::Ask, SE::AOL,  Rank::MajesticSEO
Rank::MajesticSEO - SE::Bing не парсил при указании региона
- Парсер SE::Yandex::WordStat мог пропускать запросы при использовании антикаптчи
Исправления
- В парсере
 SE::QIP для некоторых запросов не корректно определялась кодировка сниппетов
SE::QIP для некоторых запросов не корректно определялась кодировка сниппетов - A-Parser зависал при использовании JavaScript парсеров совместно с конструктором результатов
- В парсере SE::Bing в серп могли попадать рекламные блоки
- В парсере Net::Whois собиралась дата для некоторых доменов
- В JavaScript парсерах исправлен вывод ошибок в коде
- В JavaScript парсерах исправлен подсчет HTTP запросов для статистики
- 0
- 06.04.2017 15:00Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
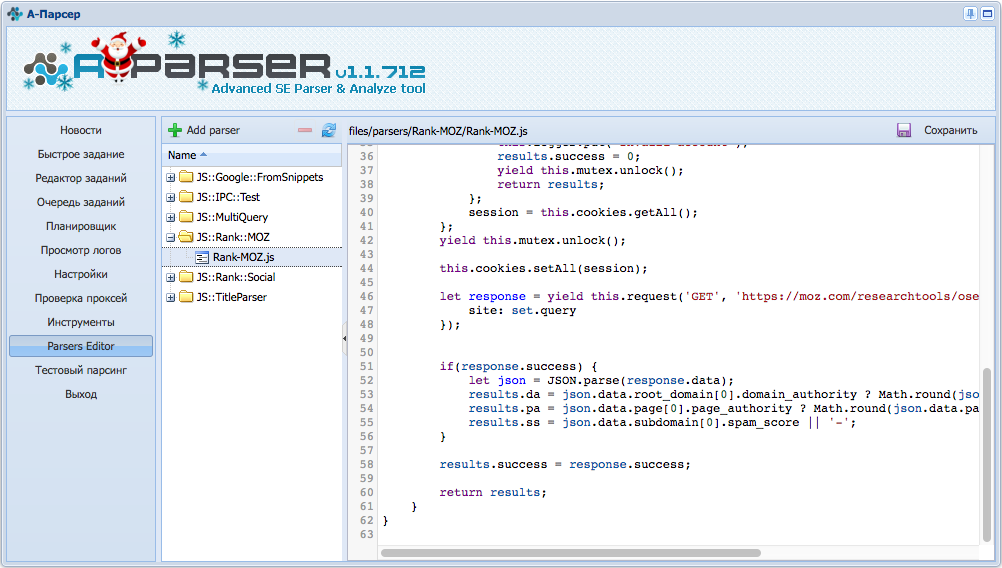
1.1.811 - 6 новых парсеров, улучшения в JavaScript парсерах

В A-Parser 1.1.811 добавлено 6 новых встроенных парсеров - Амазон, Яндекс.Маркет, Рамблер, IxQuick, добавление ссылки в индекс Bing, расширенный парсер Moz(OpenSiteExplorer). Добавляйте идеи для новых парсеров на нашем форуме и мы их обязательно реализуем.
Помимо встроенных парсеров вы можете создавать свои собственные парсеры на языке JavaScript - используя всю мощь многопоточности A-Parser'а, а также производительность движка V8 и преимущества ES6.
Для владельцев CapMonster и XEvil - напоминаем что A-Parser можно подключить к этим программам из коробки, тем самым колоссально повысив скорость парсинга во многих парсерах
Улучшения- Новый парсер
 Shop::Amazon - парсит выдачу https://www.amazon.com по ключевому слову, собирает название, ссылку, картинку, прайс, прайс до скидки, рейтинг, число комментариев, продавца и дополнительную информацию
Shop::Amazon - парсит выдачу https://www.amazon.com по ключевому слову, собирает название, ссылку, картинку, прайс, прайс до скидки, рейтинг, число комментариев, продавца и дополнительную информацию - Новый парсер
 Shop::Yandex::Market - парсер Яндекс.Маркета, по указанному ключевому слову(или по прямой ссылке на категорию) собирает следующие данные: название товара, ссылку, ссылку на картинку, рейтинг, число комментариев, цену от и до, число предложений от магазинов и список дополнительных характеристик
Shop::Yandex::Market - парсер Яндекс.Маркета, по указанному ключевому слову(или по прямой ссылке на категорию) собирает следующие данные: название товара, ссылку, ссылку на картинку, рейтинг, число комментариев, цену от и до, число предложений от магазинов и список дополнительных характеристик - Новый парсер
 SE::Rambler - сегодня рамблер использует одновременно выдачу Google и Яндекса, в зависимости от геолокации пользователя(прокси), есть поддержка антигейта
SE::Rambler - сегодня рамблер использует одновременно выдачу Google и Яндекса, в зависимости от геолокации пользователя(прокси), есть поддержка антигейта - Новый парсер
 SE::IxQuick - https://www.ixquick.com - еще один поисковик, основанный на выдаче Google
SE::IxQuick - https://www.ixquick.com - еще один поисковик, основанный на выдаче Google - Добавление ссылок в индекс Бинга -
 SE::Bing::AddURL - добавляет ваши ссылки в промышленных масштабах, требуется антигейт
SE::Bing::AddURL - добавляет ваши ссылки в промышленных масштабах, требуется антигейт - Новый парсер
 Rank::OpenSiteExplorer::Extended - расширенная версия парсера
Rank::OpenSiteExplorer::Extended - расширенная версия парсера  Rank::OpenSiteExplorer, собирает с https://moz.com 39 параметров по домену, сабдомену и странице
Rank::OpenSiteExplorer, собирает с https://moz.com 39 параметров по домену, сабдомену и странице - JavaScript парсеры: новые методы this.util.urlFromHTML(url, [base]) и this.util.updateResultsData(results, data)
- В парсере SE::Yandex добавлен сбор времени последнего кэширования страницы
Исправления в связи с изменениями в выдаче- SE::Yandex - исправлен парсинг выдачи, сбор ссылки на кэш страницы, а также парсинг рекламных объявлений
- SE::Google - исправлен парсинг рекламных объявлений, а также проблема с парсингом в редких случаях при использовании антигейта
- В парсере Net::Whois исправлен парсинг дат, а также улучшен парсинг whois сервера GoDaddy
- SE::Google::Trends - полностью обновлен парсер и список собираемых значений
-
 Rank::LinkPad, Rank::MajesticSEO,
Rank::LinkPad, Rank::MajesticSEO,  SE::Seznam
SE::Seznam
Исправления- Проблема с прокруткой в Планировщике
- Проблема с кодировкой в tools.parseJSON
- Ошибка импорта JavaScript парсеров
- 0
- 20.04.2017 17:01Новичок
- Регистрация: 03.06.2013
- Сообщений: 17
- Репутация: 2
1.1.832 - новые парсеры, выбор языка интерфейса в Google

Улучшения- Новый парсер
 Rank::SimilarWeb - парсит сервис http://similarweb.com, собирает множество параметров, включая ранк домена, трафик, распределение трафика по источникам и странам
Rank::SimilarWeb - парсит сервис http://similarweb.com, собирает множество параметров, включая ранк домена, трафик, распределение трафика по источникам и странам - Новый парсер
 Rank::MegaIndex - парсит сервис https://megaindex.com, собирает число трафика по органике и рекламным запросам, а также различную информацию о беклинках и индексации сайта
Rank::MegaIndex - парсит сервис https://megaindex.com, собирает число трафика по органике и рекламным запросам, а также различную информацию о беклинках и индексации сайта - Новый парсер
 Rank::SEMrush::Keyword - собирает трафик, конкуренцию и другие параметры по ключевому слову в сервисе http://semrush.com
Rank::SEMrush::Keyword - собирает трафик, конкуренцию и другие параметры по ключевому слову в сервисе http://semrush.com - В парсере SE::Google добавлена возможность выбора языка интерфейса гугла, актуально для точного снятия позиций
- В настройках антигейта добавлена опция Report bad captchas - отключив которую можно сэкономить время на запрос о неправильной каптче, актуально для CapMonster и XEvil
- Удалены 5 устаревших парсеров:
 SE::Google::pR - сервис больше не существует,
SE::Google::pR - сервис больше не существует,  SE::Google::Maps - выдача зависит от гео прокси,
SE::Google::Maps - выдача зависит от гео прокси,  Rank::Ahrefs - парсинг сервиса возможен только с аккаунтами с подтвержденной кредитной картой,
Rank::Ahrefs - парсинг сервиса возможен только с аккаунтами с подтвержденной кредитной картой,  Rank::Category - нет подходящего сервиса, Rank::DMOZ - dmoz прекратил свое существование в марте
Rank::Category - нет подходящего сервиса, Rank::DMOZ - dmoz прекратил свое существование в марте - Теперь парсер SE::Yandex по умолчанию использует https, избегая ненужного редиректа
- SE::Bing,
 Rank::Archive, SE::AOL, SE::IxQuick, SE::Yahoo, Rank::Linkpad
Rank::Archive, SE::AOL, SE::IxQuick, SE::Yahoo, Rank::Linkpad
- JavaScript парсеры: исправлена обработка checkbox в настройках
- JavaScript парсеры: исправлено падение при одновременном запуске нескольких заданий
- SE::Bing::AddURL - исправлена работа при неверно разгаданной каптче
- SE::Google::Trends - исправлена работа с неанглийскими запросами
- В парсере Net::HTTP исправлена работа опции Check next page в редких случаях
- Исправлена работа со сжатым контентом для редких сайтов
- 0



Тэги топика:
Похожие темы
| Темы | Раздел | Ответов | Последний пост |
|---|---|---|---|
LTK Parser - парсер поисковых подсказок на разных языках | Софт, скрипты, лицензии | 12 | 06.05.2012 21:10 |
Парсер контента под дорвеи и сателлиты X-Parser | Софт, скрипты, сервисы | 0 | 15.08.2010 23:51 |
KD Parser - парсер ключевых слов | Софт, скрипты, лицензии | 2 | 10.04.2010 21:47 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Поисковые системы | 10 | 24.11.2009 15:52 |
Хороший Парсер Я.Директ и Wordstat - Магадан | Софт, скрипты, сервисы | 4 | 15.09.2009 19:38 |
adult blog camera powershot woocommerce zennoposter акция база блог было быть вечный вконтакт вывод гугл добавить домен завтра запрос заработок импорт инстагор использовать кейс купить куча месяц модератор необходимый несколько общий очень покупка пользоваться помощь попасть править программа продвижение процент работать ребёнок решить сайт сбор сделка сервис совет создание сообщение сообщество средство товар участвовать форум форумчаны хватать цвета цена яндекс
Тем:
77,607Сообщений:
763,441Пользователей:
30,081Сейчас на сайте:
0 пользователей и 415 гостей