–•–æ—á—É –ø–æ–¥–µ–ª–∏—Ç—å—Å—è —Å–≤–æ–∏–º–∏ –≤–ø–µ—á–∞—Ç–ª–µ–Ω–∏—è–º–∏ –æ–± a-parser –ù–∞—á–Ω–µ–º —Å —Ç–æ–≥–æ, –¥–ª—è —á–µ–≥–æ —è –∏–º –ø–æ–ª—å–∑—É—é—Å—å:–ü–æ–ª—å–∑—É—é –∞–ø–∞—Ä—Å–µ—Ä–æ–º —É–∂–µ –æ–∫–æ–ª–æ –≥–æ–¥–∞ –î–ª—è –º–µ—Å—è "–∞ –ø–∞—Ä—Å–µ—Ä" —Å—Ç–∞–ª –Ω–µ –∑–∞–º–µ–Ω–∏–º —Ç–∞–∫ –∫–∞–∫ –≤—ã–ø–æ–ª–Ω—è–µ—Ç –æ—á–µ–Ω—å –º–Ω–æ–≥–æ —Ñ—É–Ω–∫—Ü–∏–π, –∏ —á—Ç–æ —Å–∞–º–æ–µ –≥–ª–∞–≤–Ω–æ–µ, –æ–Ω –¥–µ–ª–∞–µ—Ç —ç—Ç–æ –æ—á–µ–Ω—å –±—ã—Å—Ç—Ä–æ! –í—Å–µ –≤–æ–ø—Ä–æ—Å—ã –∫–æ—Ç–æ—Ä—ã–µ —É –º–µ–Ω—è –≤–æ–∑–Ω–∏–∫–∞–ª–∏, —Ç–µ—Ö –ø–æ–¥–¥–µ—Ä–∂–∫–∞ —Ä–µ—à–∞–ª–∞ –æ—á–µ–Ω—å –æ–ø–µ—Ä–∞—Ç–∏–≤–Ω–æ –Ý–∞–∑–æ–±—Ä–∞—Ç—å—Å—è —Å —Ç–µ–º –∫–∞–∫ —Ä–∞–±–æ—Ç–∞–µ—Ç –ø–∞—Ä—Å–µ—Ä –ø—Ä–æ–±–ª–µ–º –Ω–µ —Å–æ—Å—Ç–∞–≤–∏—Ç –¥–∞–∂–µ —É –Ω–æ–≤–∏—á–∫–∞, —Ç–∞–∫ –∫–∞–∫ –≤–∏–∫–∏ –ø–æ —Å–æ—Ñ—Ç—É –Ω–∞ –≤—ã—Å—à–µ–º —É—Ä–æ–≤–∫–µ –ï—â–µ –æ–¥–∏–Ω –ø–ª—é—Å - –¢–ü –º–æ–∂–µ—Ç –∑–∞ –º–∏–Ω–∏–º–∞–ª—å–Ω—É—é —Å—É–º–º—É –Ω–∞–ø–∏—Å–∞—Ç—å –ø–∞—Ä—Å–µ—Ä –ø–æ–¥ —Ç–≤–æ–∏ –Ω–∞–¥–æ–±–Ω–æ—Å—Ç–∏, —á—Ç–æ —Å—É—â–µ—Å—Ç–≤–µ–Ω–Ω–æ —ç–∫–æ–Ω–æ–º–∏—Ç –≤—Ä–µ–º—è –ò–∑ –º–∏–Ω—É—Å–æ–≤ - –∫–∞–∫ —è –ø–æ–Ω—è–ª —Ç–µ—Ö –ø–æ–¥–¥–µ—Ä–∂–∫–∞ –ø–æ –≤—ã—Ö–æ–¥–Ω—ã–º –Ω–µ —Ä–∞–±–æ—Ç–∞–µ—Ç :)))))
- —Å–±–æ—Ä–∞ –∏–Ω—Ñ—ã –æ–± –æ—Å–≤–æ–±–æ–∂–¥–∞—é—â–∏—Ö—Å—è –∏–ª–∏ –æ—Å–≤–æ–±–æ–¥–∏–≤—à–∏—Ö—Å—è –¥–æ–º–µ–Ω–∞—Ö
- –ø–∞—Ä—Å–∏–Ω–≥–∞ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–Ω—ã—Ö —Å–∞–π—Ç–æ–≤ –∏ –∞–≤—Ç–æ–º–∞—Ç–∏—á–µ—Å–∫–æ–µ —Ñ–æ—Ä–º–∏—Ä–æ–≤–∞–Ω–∏—è —Ñ–∞–π–ª–∞ —Å —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞–º–∏ –ø–∞—Ä—Å–∏–Ω–≥–∞
- —Å–±–æ—Ä —Ä–∞–∑–ª–∏—á–Ω—ã—Ö –±–∞–∑ –∏ –∏—Ö —Ñ–∏–ª—å—Ç—Ä–∞—Ü–∏—è
A-Parser - –ø—Ä–æ–¥–≤–∏–Ω—É—Ç—ã–π –ø–∞—Ä—Å–µ—Ä –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º, Suggest, WordStat, PR, DMOZ, Whois, DNS, etc
(–û—Ç–≤–µ—Ç–æ–≤: 340, –ü—Ä–æ—Å–º–æ—Ç—Ä–æ–≤: 48257)
- 07.09.2020 14:18–í—Å–µ –µ—â–µ —É—á—É—Å—å...


- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 30.08.2011
- –°–æ–æ–±—â–µ–Ω–∏–π: 180
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 59
- Webmoney BL:
 ?
?
- 0
- 09.09.2020 17:19–û–ø—ã—Ç–Ω—ã–π


- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–í–∏–¥–µ–æ —É—Ä–æ–∫: –ø—Ä–æ—Å–º–æ—Ç—Ä —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –ø–∞—Ä—Å–∏–Ω–≥–∞, –Ω–∞—Å—Ç—Ä–æ–π–∫–∞ –ø—Ä–æ–∫—Å–∏ —Å –∞–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏–µ–π, –æ–ø—Ü–∏—è Extra query string
–í —ç—Ç–æ–º –≤–∏–¥–µ–æ —É—Ä–æ–∫–µ —Ä–∞—Å—Å–º–æ—Ç—Ä–µ–Ω—ã –æ—Ç–≤–µ—Ç—ã –Ω–∞ 3 —á–∞—Å—Ç–æ –∑–∞–¥–∞–≤–∞–µ–º—ã—Ö –≤–æ–ø—Ä–æ—Å–∞ –æ—Ç –Ω–æ–≤—ã—Ö –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –ê-–ü–∞—Ä—Å–µ—Ä–∞
- –ì–¥–µ –∏ –∫–∞–∫ –º–æ–∂–Ω–æ –ø–æ—Å–º–æ—Ç—Ä–µ—Ç—å —Ä–µ–∑—É–ª—å—Ç–∞—Ç—ã –ø–∞—Ä—Å–∏–Ω–≥–∞?
- –ö–∞–∫ –ø–æ–¥–∫–ª—é—á–∏—Ç—å –ø—Ä–æ–∫—Å–∏ —Å –∞–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏–µ–π?
- Extra query string, —á—Ç–æ —ç—Ç–æ —Ç–∞–∫–æ–µ –∏ –∫–∞–∫ –ø—Ä–∏–º–µ–Ω—è—Ç—å —ç—Ç—É –æ–ø—Ü–∏—é?
- –ü—Ä–æ—Å–º–æ—Ç—Ä —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –ø–∞—Ä—Å–∏–Ω–≥–∞ 3-–º—è —Å–ø–æ—Å–æ–±–∞–º–∏:
- –°–ø–æ—Å–æ–± –ø–µ—Ä–≤—ã–π. "–ò–∑ –æ—á–µ—Ä–µ–¥–∏ –∑–∞–¥–∞–Ω–∏–π, –µ—Å–ª–∏ –∑–∞–¥–∞–Ω–∏–µ –Ω–∞ –ø–∞—É–∑–µ".
- –°–ø–æ—Å–æ–± –≤—Ç–æ—Ä–æ–π. "–ò–∑ –æ—á–µ—Ä–µ–¥–∏ –∑–∞–¥–∞–Ω–∏–π, –µ—Å–ª–∏ –∑–∞–¥–∞–Ω–∏–µ –∑–∞–≤–µ—Ä—à–µ–Ω–æ".
- –°–ø–æ—Å–æ–± —Ç—Ä–µ—Ç–∏–π. "–ó–∞–±–∏—Ä–∞–µ–º —Ä–µ–∑—É–ª—å—Ç–∞—Ç –∏–∑ –ø–∞–ø–∫–∏ results".
- –ü–æ–¥–∫–ª—é—á–µ–Ω–∏–µ –ø—Ä–æ–∫—Å–∏ —Å –∞–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏–µ–π.
- –ü—Ä–∏–º–µ—Ä—ã –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è –æ–ø—Ü–∏–∏ Extra query string.
- https://a-parser.com/resources/categories/14/ - —Å–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ (–∫–∞—Ç–∞–ª–æ–≥)
- https://a-parser.com/resources/77/ - –°–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –Ω–µ—Å–∫–æ–ª—å–∫–∏—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –≤ —Ä–∞–∑–Ω—ã–µ –ø–∞–ø–∫–∏
- https://a-parser.com/resources/394/ - –°–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –≤ –Ω–µ—Å–∫–æ–ª—å–∫–æ —Ñ–∞–π–ª–æ–≤ –∏—Å–ø–æ–ª—å–∑—É—è –ø–µ—Ä–µ–º–µ–Ω–Ω—ã–µ, –º–∞—Å—Å–∏–≤—ã –∏ —É—Å–ª–æ–≤–∏—è (–≤–∏–¥–µ–æ)
- https://a-parser.com/resources/397/ - –°–æ—Ö—Ä–∞–Ω–µ–Ω–∏–µ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –≤ Google SpreadSheets
- https://a-parser.com/wiki/proxy/ - –ù–∞—Å—Ç—Ä–æ–π–∫–∞ –ø—Ä–æ–∫—Å–∏
- https://a-parser.com/wiki/settings-and-presets/ - –û–±—â–∏–µ –Ω–∞—Å—Ç—Ä–æ–π–∫–∏ –¥–ª—è –ø–∞—Ä—Å–µ—Ä–æ–≤

- 0
- 22.09.2020 18:23–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–°–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤ #43: –æ—Å–≤–æ–±–æ–∂–¥–∞—é—â–∏–µ—Å—è –¥–æ–º–µ–Ω—ã, –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ —Å–∞–π—Ç–æ–≤ –∏ –ø–∞—Ä—Å–∏–Ω–≥ PDF
43-–π —Å–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤, –≤ –∫–æ—Ç–æ—Ä—ã–π –≤–æ—à–ª–∏ –ø—Ä–µ—Å–µ—Ç –¥–ª—è –ø–∞—Ä—Å–∏–Ω–≥–∞ –æ—Å–≤–æ–±–æ–∂–¥–∞—é—â–∏—Ö—Å—è –¥–æ–º–µ–Ω–æ–≤, –ø–∞—Ä—Å–µ—Ä –∫–∞—Ç–µ–≥–æ—Ä–∏–π —Å–∞–π—Ç–æ–≤ –∏ –ø—Ä–∏–º–µ—Ä —Å–±–æ—Ä–∞ –¥–∞–Ω–Ω—ã—Ö –∏–∑ PDF –¥–æ–∫—É–º–µ–Ω—Ç–æ–≤.
–ê—É–∫—Ü–∏–æ–Ω –¥–æ–º–µ–Ω–æ–≤ REG.RU
–ü—Ä–µ—Å–µ—Ç, –ø–æ–∑–≤–æ–ª—è—é—â–∏–π –ø–∞—Ä—Å–∏—Ç—å –¥–æ–º–µ–Ω—ã —Å –∞—É–∫—Ü–∏–æ–Ω–∞ Reg.ru. –í –ø—Ä–µ—Å–µ—Ç–µ —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —É–∫–∞–∑—ã–≤–∞—Ç—å –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —Å—Ç—Ä–∞–Ω–∏—Ü –ø–∞–≥–∏–Ω–∞—Ü–∏–∏ –∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Ñ–∏–ª—å—Ç—Ä –ø–æ –∫–ª—é—á–µ–≤–æ–º—É —Å–ª–æ–≤—É.
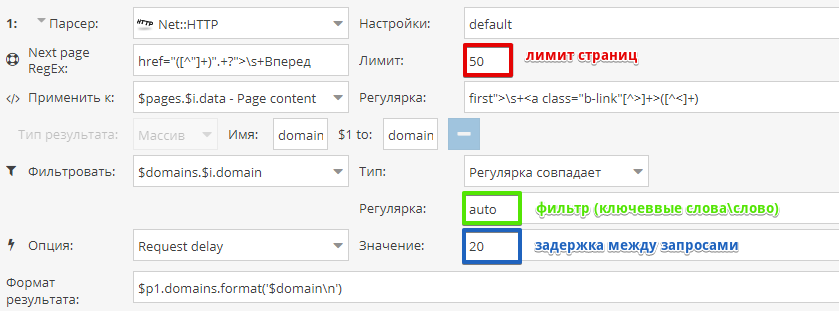
–û–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ –∫–∞—Ç–µ–≥–æ—Ä–∏–π —Å–∞–π—Ç–∞
–ü–∞—Ä—Å–µ—Ä, —Å–æ–±–∏—Ä–∞—é—â–∏–π –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ —Å–∞–π—Ç–æ–≤ –∏–∑ MegaIndex.
–ü–∞—Ä—Å–∏–Ω–≥ PDF
–ü—Ä–∏–º–µ—Ä –ø–∞—Ä—Å–∏–Ω–≥–∞ –¥–∞–Ω–Ω—ã—Ö –∏–∑ –¥–æ–∫—É–º–µ–Ω—Ç–æ–≤ –≤ —Ñ–æ—Ä–º–∞—Ç–µ PDF. –î–ª—è —Ä–∞–±–æ—Ç—ã –∏—Å–ø–æ–ª—å–∑—É–µ—Ç—Å—è Node.js –º–æ–¥—É–ª—å pdf-parse.
–ö—Ä–æ–º–µ —ç—Ç–æ–≥–æ:- –ü–∞—Ä—Å–µ—Ä —Å—Å—ã–ª–æ–∫ –ª–æ–∫–∞—Ü–∏–π –¥–ª—è Social::Instagram::Geo - —Å–±–æ—Ä —Å—Å—ã–ª–æ–∫ –Ω–∞ –ª–æ–∫–∞—Ü–∏–∏ –≤ Instagram
–ü—Ä–µ–¥–ª–∞–≥–∞–π—Ç–µ –≤–∞—à–∏ –∏–¥–µ–∏ –¥–ª—è –Ω–æ–≤—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –∑–¥–µ—Å—å, –ª—É—á—à–∏–µ –±—É–¥—É—Ç —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω—ã –∏ –æ–ø—É–±–ª–∏–∫–æ–≤–∞–Ω—ã.
–ü–æ–¥–ø–∏—Å—ã–≤–∞–π—Ç–µ—Å—å –Ω–∞ –Ω–∞—à –∫–∞–Ω–∞–ª –Ω–∞ Youtube - —Ç–∞–º —Ä–µ–≥—É–ª—è—Ä–Ω–æ –≤—ã–∫–ª–∞–¥—ã–≤–∞—é—Ç—Å—è –≤–∏–¥–µ–æ —Å –ø—Ä–∏–º–µ—Ä–∞–º–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è A-Parser, –∞ —Ç–∞–∫–∂–µ —Å–ª–µ–¥–∏—Ç–µ –∑–∞ –Ω–æ–≤–æ—Å—Ç—è–º–∏ –≤ Twitter.
–í—Å–µ —Å–±–æ—Ä–Ω–∏–∫–∏ —Ä–µ—Ü–µ–ø—Ç–æ–≤
- 0
- 23.10.2020 17:24–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
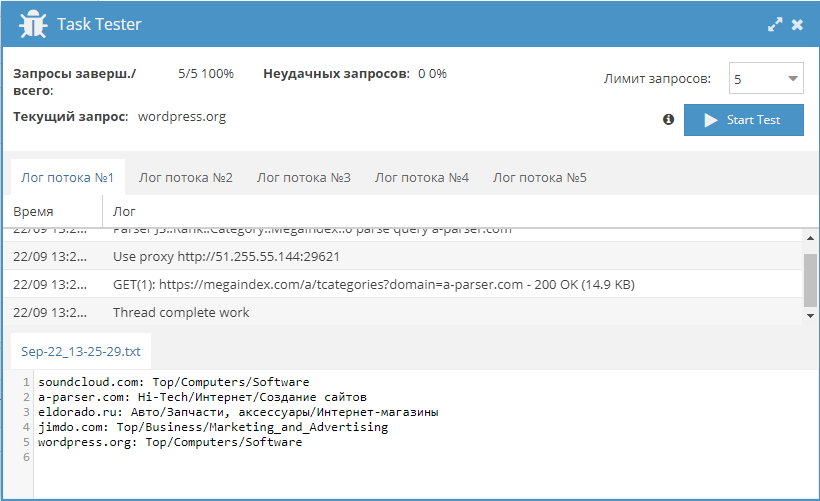
–°–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤ #44: –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ —Å–∞–π—Ç–æ–≤ –æ—Ç Cloudflare Radar, –ø–∞—Ä—Å–µ—Ä Rozetka –∏ kufar.by
44-–π —Å–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤, –≤ –∫–æ—Ç–æ—Ä—ã–π –≤–æ—à–ª–∏ –ø–∞—Ä—Å–µ—Ä, –æ–ø—Ä–µ–¥–µ–ª—è—é—â–∏–π –∫–∞—Ç–µ–≥–æ—Ä–∏–∏ —Å–∞–π—Ç–æ–≤ (–∏—Å–ø–æ–ª—å–∑—É—è —Å–µ—Ä–≤–∏—Å Cloudflare Radar), –ø–∞—Ä—Å–µ—Ä Rozetka —á–µ—Ä–µ–∑ API –∏ –ø–∞—Ä—Å–µ—Ä –∏–Ω—Ç–µ—Ä–Ω–µ—Ç-–º–∞–≥–∞–∑–∏–Ω–∞ kufar.by —Å –ø—Ä–æ—Ö–æ–¥–æ–º –ø–æ —Å–ø–∏—Å–∫—É —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤.
–ü–∞—Ä—Å–µ—Ä Cloudflare Radar
–ü–∞—Ä—Å–µ—Ä –¥–ª—è —Å–±–æ—Ä–∞ –∫–∞—Ç–µ–≥–æ—Ä–∏–π —Å–∞–π—Ç–æ–≤ –∏–∑ Cloudflare Radar

Rozetka - –ø–æ–ª—É—á–µ–Ω–∏–µ –¥–∞–Ω–Ω—ã—Ö –ø–æ API
–ü–∞—Ä—Å–µ—Ä, —Å–æ–±–∏—Ä–∞—é—â–∏–π –¥–∞–Ω–Ω—ã–µ –æ —Ç–æ–≤–∞—Ä–∞—Ö –Ω–∞ —Ç–æ—Ä–≥–æ–≤–æ–π –ø–ª–æ—â–∞–¥–∫–µ Rozetka —á–µ—Ä–µ–∑ API.

–ü–∞—Ä—Å–∏–Ω–≥ –æ–±—ä—è–≤–ª–µ–Ω–∏–π kufar.by
–ü–∞—Ä—Å–µ—Ä –æ–±—ä—è–≤–ª–µ–Ω–∏–π –Ω–∞ —Å–∞–π—Ç–µ kufar.by —Å –ø—Ä–æ—Ö–æ–¥–æ–º –ø–æ —Å–ø–∏—Å–∫—É —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤. –°–æ–±–∏—Ä–∞—é—Ç—Å—è –∑–∞–≥–æ–ª–æ–≤–∫–∏ –æ–±—ä—è–≤–ª–µ–Ω–∏–π, —Ü–µ–Ω—ã, –∏–º–µ–Ω–∞ –∏ —Ç–µ–ª–µ—Ñ–æ–Ω—ã –∞–≤—Ç–æ—Ä–æ–≤.
–ê —Ç–∞–∫–∂–µ, –æ–±–Ω–æ–≤–ª–µ–Ω—ã —Å–ª–µ–¥—É—é—â–∏–µ —Ä–µ—Å—É—Ä—Å—ã:- –ü–∞—Ä—Å–∏–Ω–≥ –∫–æ–º–º–µ–Ω—Ç–∞—Ä–∏–µ–≤ –∏–∑ Youtube
- –ü–∞—Ä—Å–µ—Ä —Å–æ–±–∏—Ä–∞—é—â–∏–π –≤–æ–ø—Ä–æ—Å—ã –∏ –æ—Ç–≤–µ—Ç—ã –∏–∑ –≤—ã–¥–∞—á–∏ Google
–ü—Ä–µ–¥–ª–∞–≥–∞–π—Ç–µ –≤–∞—à–∏ –∏–¥–µ–∏ –¥–ª—è –Ω–æ–≤—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –∑–¥–µ—Å—å, –ª—É—á—à–∏–µ –±—É–¥—É—Ç —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω—ã –∏ –æ–ø—É–±–ª–∏–∫–æ–≤–∞–Ω—ã.
–ü–æ–¥–ø–∏—Å—ã–≤–∞–π—Ç–µ—Å—å –Ω–∞ –Ω–∞—à –∫–∞–Ω–∞–ª –Ω–∞ Youtube - —Ç–∞–º —Ä–µ–≥—É–ª—è—Ä–Ω–æ –≤—ã–∫–ª–∞–¥—ã–≤–∞—é—Ç—Å—è –≤–∏–¥–µ–æ —Å –ø—Ä–∏–º–µ—Ä–∞–º–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è A-Parser, –∞ —Ç–∞–∫–∂–µ —Å–ª–µ–¥–∏—Ç–µ –∑–∞ –Ω–æ–≤–æ—Å—Ç—è–º–∏ –≤ Twitter.
–í—Å–µ —Å–±–æ—Ä–Ω–∏–∫–∏ —Ä–µ—Ü–µ–ø—Ç–æ–≤
- 0
- 21.12.2020 18:24–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
1.2.1076 - 3 –Ω–æ–≤—ã—Ö –ø–∞—Ä—Å–µ—Ä–∞, –∑–∞–≤–µ—Ä—à–µ–Ω–∏–µ –ø–µ—Ä–µ—Ö–æ–¥–∞ –Ω–∞ Node.js, –∏–Ω—Ç–µ–≥—Ä–∞—Ü–∏—è puppeteer –≤ —Å–±–æ—Ä–∫—É

–£–ª—É—á—à–µ–Ω–∏—è- –í —Å–≤—è–∑–∏ —Å –ø–µ—Ä–µ–≤–æ–¥–æ–º –æ—Å–Ω–æ–≤–Ω—ã—Ö –≤—Å—Ç—Ä–æ–µ–Ω–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –Ω–∞ –Ω–æ–≤—É—é –ø–ª–∞—Ç—Ñ–æ—Ä–º—É Node.js, –ø–æ–ª–Ω–æ—Å—Ç—å—é –ø–µ—Ä–µ–ø–∏—Å–∞–Ω—ã –∏ –æ–±–Ω–æ–≤–ª–µ–Ω—ã –ø–∞—Ä—Å–µ—Ä—ã:
- –û—Å–Ω–æ–≤–Ω—ã–µ —É–ª—É—á—à–µ–Ω–∏—è –æ—Ç –ø–µ—Ä–µ–≤–æ–¥–∞ –¥–∞–Ω–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –Ω–∞ Node.js:
- —É–≤–µ–ª–∏—á–µ–Ω–∏–µ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç–∏ –≤ ~1.5 —Ä–∞–∑–∞
- —É–Ω–∏—Ñ–∏–∫–∞—Ü–∏—è HTTP –¥–≤–∏–∂–∫–∞ —Å JavaScript –ø–∞—Ä—Å–µ—Ä–∞–º–∏, –µ–¥–∏–Ω—ã–π –æ–±—Ö–æ–¥ CloudFlare
- –î–æ–±–∞–≤–ª–µ–Ω—ã –Ω–æ–≤—ã–µ –ø–∞—Ä—Å–µ—Ä—ã:
- –í
 HTML::EmailExtractor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è Skip non-HTML blocks, –ø–æ–∑–≤–æ–ª—è—é—â–∞—è –æ—Ç–∫–ª—é—á–∏—Ç—å —Å–±–æ—Ä –ø–æ—á—Ç –≤–Ω—É—Ç—Ä–∏ —Ç–µ–≥–æ–≤ script, style –∏ —Ç.–ø.
HTML::EmailExtractor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è Skip non-HTML blocks, –ø–æ–∑–≤–æ–ª—è—é—â–∞—è –æ—Ç–∫–ª—é—á–∏—Ç—å —Å–±–æ—Ä –ø–æ—á—Ç –≤–Ω—É—Ç—Ä–∏ —Ç–µ–≥–æ–≤ script, style –∏ —Ç.–ø. - –í
 SE::Google::Translate –¥–æ–±–∞–≤–ª–µ–Ω—ã –Ω–æ–≤—ã–µ –ø–µ—Ä–µ–º–µ–Ω–Ω—ã–µ:
SE::Google::Translate –¥–æ–±–∞–≤–ª–µ–Ω—ã –Ω–æ–≤—ã–µ –ø–µ—Ä–µ–º–µ–Ω–Ω—ã–µ:- $translit_orig - –æ—Ä–∏–≥–∏–Ω–∞–ª—å–Ω—ã–π —Ç–µ–∫—Å—Ç —Ç—Ä–∞–Ω—Å–ª–∏—Ç–æ–º
- $translit_translated - –ø–µ—Ä–µ–≤–µ–¥–µ–Ω–Ω—ã–π —Ç–µ–∫—Å—Ç —Ç—Ä–∞–Ω—Å–ª–∏—Ç–æ–º
- $variants.$i.text - —Å–ø–∏—Å–æ–∫ –≤–∞—Ä–∏–∞–Ω—Ç–æ–≤ –ø–µ—Ä–µ–≤–æ–¥–∞ –æ—Ä–∏–≥–∏–Ω–∞–ª—å–Ω–æ–≥–æ —Ç–µ–∫—Å—Ç–∞
- –í
 SE::Bing –æ–±–Ω–æ–≤–ª–µ–Ω —Å–ø–∏—Å–æ–∫ —Ä–µ–≥–∏–æ–Ω–æ–≤ –∏ —è–∑—ã–∫–æ–≤
SE::Bing –æ–±–Ω–æ–≤–ª–µ–Ω —Å–ø–∏—Å–æ–∫ —Ä–µ–≥–∏–æ–Ω–æ–≤ –∏ —è–∑—ã–∫–æ–≤ - –í
 Social::Instagram::Profile –∏
Social::Instagram::Profile –∏  Social::Instagram::Post –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Å–æ–±–∏—Ä–∞—Ç—å –∫–æ–ª-–≤–æ –≤–∏–¥–µ–æ–ø—Ä–æ—Å–º–æ—Ç—Ä–æ–≤
Social::Instagram::Post –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Å–æ–±–∏—Ä–∞—Ç—å –∫–æ–ª-–≤–æ –≤–∏–¥–µ–æ–ø—Ä–æ—Å–º–æ—Ç—Ä–æ–≤ - –í
 SE::Yandex::Translate –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –æ—Ç–∫–ª—é—á–∞—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–µ—Å—Å–∏–π
SE::Yandex::Translate –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –æ—Ç–∫–ª—é—á–∞—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ —Å–µ—Å—Å–∏–π - –í
 Net::HTTP –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —É–∫–∞–∑—ã–≤–∞—Ç—å user-agent –¥–ª—è Chrome
Net::HTTP –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —É–∫–∞–∑—ã–≤–∞—Ç—å user-agent –¥–ª—è Chrome - –í –ø–∞—Ä—Å–µ—Ä–µ
 Rank::MOZ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞, –≤–æ–∑–Ω–∏–∫–∞—é—â–∞—è –ø—Ä–∏ –≤—ã–∑–æ–≤–µ –ø–∞—Ä—Å–µ—Ä–∞ –∏–∑ JS –º–µ—Ç–æ–¥–æ–º this.parser.request().
Rank::MOZ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞, –≤–æ–∑–Ω–∏–∫–∞—é—â–∞—è –ø—Ä–∏ –≤—ã–∑–æ–≤–µ –ø–∞—Ä—Å–µ—Ä–∞ –∏–∑ JS –º–µ—Ç–æ–¥–æ–º this.parser.request(). - –í
 Rank::CMS –¥–æ–±–∞–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ –Ω–æ–≤–æ–≥–æ apps.json –∏ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å Net::HTTP
Rank::CMS –¥–æ–±–∞–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ –Ω–æ–≤–æ–≥–æ apps.json –∏ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å Net::HTTP - –í
 Net::Whois –æ–±–Ω–æ–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ –≤—Å–µ—Ö –∑–æ–Ω
Net::Whois –æ–±–Ω–æ–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ –≤—Å–µ—Ö –∑–æ–Ω - –î–ª—è –ø—Ä–æ–∫—Å–∏—á–µ–∫–µ—Ä–æ–≤ –¥–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è Exclude from "All", –∞ —Ç–∞–∫–∂–µ —Å–¥–µ–ª–∞–Ω—ã –∏–∑–º–µ–Ω–µ–Ω–∏—è –≤ –ª–æ–≥–∏–∫–µ:
- "All" - –∏—Å–ø–æ–ª—å–∑—É–µ—Ç –≤—Å–µ –ø—Ä–æ–∫—Å–∏ –≤—ã–±—Ä–∞–Ω–Ω—ã–µ –¥–ª—è –∑–∞–¥–∞–Ω–∏–∏
- –∫–æ–Ω–∫—Ä–µ—Ç–Ω—ã–π –ø—Ä–æ–∫—Å–∏—á–µ–∫–µ—Ä - –∏—Å–ø–æ–ª—å–∑—É–µ—Ç –µ–≥–æ, –¥–∞–∂–µ –µ—Å–ª–∏ –æ–Ω –Ω–µ –≤—ã–±—Ä–∞–Ω –≤ –∑–∞–¥–∞–Ω–∏–∏
- –î–æ–±–∞–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ —É—Å—Ç–∞—Ä–µ–≤—à–∏—Ö –≤–µ—Ä—Å–∏–π SSL
- JS –ø–∞—Ä—Å–µ—Ä—ã: –î–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è tlsOpts –¥–ª—è this.request(), –ø–æ–∑–≤–æ–ª—è–µ—Ç –ø–µ—Ä–µ–¥–∞–≤–∞—Ç—å –Ω–∞—Å—Ç—Ä–æ–π–∫–∏ –¥–ª—è https —Å–æ–µ–¥–∏–Ω–µ–Ω–∏–π
- JS –ø–∞—Ä—Å–µ—Ä—ã: –æ–±–Ω–æ–≤–ª–µ–Ω–∏–µ Node.js —Å 14.2.0 –¥–æ 14.15.0
- JS –ø–∞—Ä—Å–µ—Ä—ã: –º–æ–¥—É–ª—å puppeteer –≤–∫–ª—é—á–µ–Ω –≤ —Å–±–æ—Ä–∫—É –ê-–ü–∞—Ä—Å–µ—Ä–∞ –∏ –Ω–µ —Ç—Ä–µ–±—É–µ—Ç –æ—Ç–¥–µ–ª—å–Ω–æ–π —É—Å—Ç–∞–Ω–æ–≤–∫–∏
- –ú–Ω–æ–∂–µ—Å—Ç–≤–æ —Ä–∞–∑–ª–∏—á–Ω—ã—Ö –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–π –≤
 SE::Google –∏
SE::Google –∏  SE::Yandex –≤ —Å–≤—è–∑–∏ —Å –∏–∑–º–µ–Ω–µ–Ω–∏—è–º–∏ –≤ –≤—ã–¥–∞—á–µ
SE::Yandex –≤ —Å–≤—è–∑–∏ —Å –∏–∑–º–µ–Ω–µ–Ω–∏—è–º–∏ –≤ –≤—ã–¥–∞—á–µ - –í SE::Yandex —É–¥–∞–ª–µ–Ω–∞ —Ñ—É–Ω–∫—Ü–∏—è –∞–≤—Ç–æ—Ä–∞—Å–ø–æ–∑–Ω–∞–≤–∞–Ω–∏—è –∫–∞–ø—Ç—á –≤ —Å–≤—è–∑–∏ —Å –∏–∑–º–µ–Ω–µ–Ω–∏–µ–º –≤–∏–¥–∞ –∫–∞–ø—Ç—á
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ SE::Google::Translate
- –í HTML::EmailExtractor –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞, –ø—Ä–∏ –∫–æ—Ç–æ—Ä–æ–π –ø—Ä–æ–ø—É—Å–∫–∞–ª–∏—Å—å –±–æ–ª—å—à–∏–µ –±–ª–æ–∫–∏ html
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ –≤ Social::Instagram::profile –∏–∑-–∑–∞ –∫–æ—Ç–æ—Ä–æ–π –Ω–µ –ø–∞—Ä—Å–∏–ª–æ—Å—å –±–æ–ª—å—à–µ –æ–¥–Ω–æ–π —Å—Ç—Ä–∞–Ω–∏—Ü—ã
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –∞–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏—è –≤ SE::Google::KeywordPlanner
- –í SE::Google::TrustCheck –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ –≥–æ—Ä–∏–∑–æ–Ω—Ç–∞–ª—å–Ω—ã—Ö –±–ª–æ–∫–æ–≤ —Å—Å—ã–ª–æ–∫
- –í SE::Baidu –∏—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–∞—Ä—Å–∏–Ω–≥ related keywords
- –í Shop::Amazon –∏—Å–ø—Ä–∞–≤–ª–µ–Ω —Å–±–æ—Ä –ø—Ä–æ–¥–∞–≤—Ü–æ–≤, –∞ —Ç–∞–∫–∂–µ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞, —Å–≤—è–∑–∞–Ω–Ω–∞—è —Å –∫–æ–ª–∏—á–µ—Å—Ç–≤–æ —Å—Ç—Ä–∞–Ω–∏—Ü
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω Rank::Linkpad, –∞ —Ç–∞–∫–∂–µ –≤ –Ω–µ–º —É–¥–∞–ª–µ–Ω–∞ –ø–µ—Ä–µ–º–µ–Ω–Ω–∞—è $links_cost, —Ç.–∫. —ç—Ç–æ–≥–æ –ø–æ–∫–∞–∑–∞—Ç–µ–ª—è –±–æ–ª—å—à–µ –Ω–µ—Ç –Ω–∞ –∏—Å—Ç–æ—á–Ω–∏–∫–µ
- –í Rank::Social::Signal –≤ —Å–≤—è–∑–∏ —Å –Ω–µ–∞–∫—Ç—É–∞–ª—å–Ω–æ—Å—Ç—å—é —É–¥–∞–ª–µ–Ω–∞ –ø–µ—Ä–µ–º–µ–Ω–Ω–∞—è $googleplus_like
- –í Rank::CMS –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ –ø–æ –ø—Ä–∏–∑–Ω–∞–∫–∞–º —Å–∫—Ä–∏–ø—Ç–æ–≤ –¥–ª—è –Ω–æ–≤–æ–≥–æ apps.json
- –¢–∞–∫–∂–µ –∞–¥–∞–ø—Ç–∏—Ä–æ–≤–∞–Ω—ã –∫ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º –≤ –≤—ã–¥–∞—á–µ: SE::Yandex::Translate, SE::MailRu, Rank::MajesticSEO, SE::Yandex::Direct, SE::Google::ByImage, Rank::Ahrefs, Shop::eBay, SE::Yandex::Register, SE::Seznam, Shop::Yandex::Market, SE::Dogpile, SE::Dogpile::Images, SE::Startpage, SE::Baidu, Shop::AliExpress, SE::Youtube, Rank::Social::Signal, SE::Yandex::SQI, SecurityTrails::Domain
- –í SE::Yandex –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ Extra query string
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–æ —Ä–µ–≥—É–ª—è—Ä–Ω–æ–µ –≤—ã—Ä–∞–∂–µ–Ω–∏–µ –≤ HTML::EmailExtractor –¥–ª—è —É—Å—Ç—Ä–∞–Ω–µ–Ω–∏—è –æ—à–∏–±–æ–∫ –≤ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö —Å–ª—É—á–∞—è—Ö
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –ø–æ–≤–µ–¥–µ–Ω–∏–µ –ø–∞—Ä—Å–µ—Ä–∞ SE::Google::KeywordPlanner –ø—Ä–∏ –æ—Ç—Å—É—Ç—Å—Ç–≤–∏–∏ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –ø–æ –∑–∞–ø—Ä–æ—Å—É
- Maps::Yandex –∏—Å–ø—Ä–∞–≤–ª–µ–Ω –∏ –ø–µ—Ä–µ–≤–µ–¥–µ–Ω –Ω–∞ puppeteer
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ –≤ –ø—Ä–∏–æ—Ä–∏—Ç–µ—Ç–∞—Ö –≤—ã–±–æ—Ä–∞ –ø—Ä–æ–∫—Å–∏—á–µ–∫–µ—Ä–∞
- JS –ø–∞—Ä—Å–µ—Ä—ã: –∏—Å–ø—Ä–∞–≤–ª–µ–Ω follow_meta_refresh
- API: –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ –ø–∞—Ä–∞–º–µ—Ç—Ä–∞ rawResults
- 0
- 16.02.2021 13:57–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
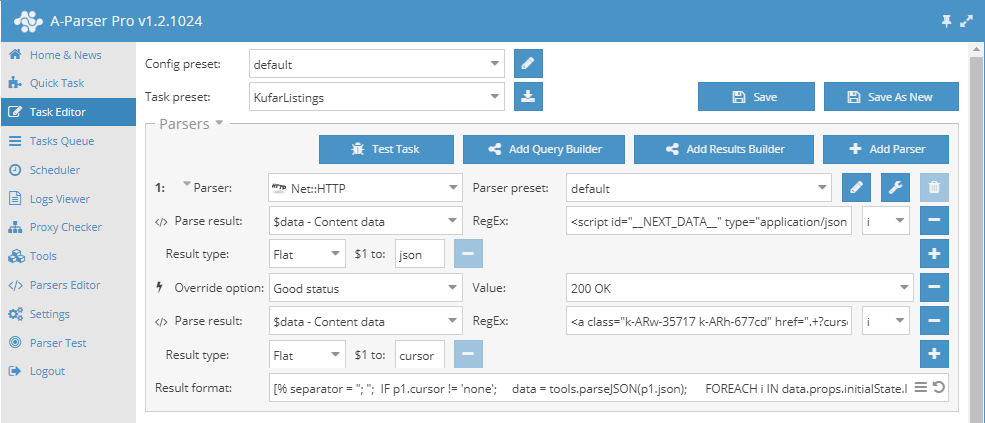
–°–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤ #45: –ø–∞—Ä—Å–µ—Ä—ã Google Places –∏ prom.ua, –ø–æ–ª—É—á–µ–Ω–∏–µ —Ö–∞—Ä–∞–∫—Ç–µ—Ä–∏—Å—Ç–∏–∫ –∫–∞—Ä—Ç–∏–Ω–æ–∫ "–Ω–∞ –ª–µ—Ç—É"
45-–π —Å–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤, –≤ –∫–æ—Ç–æ—Ä—ã–π –≤–æ—à–ª–∏ –ø–∞—Ä—Å–µ—Ä —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –ø–æ–∏—Å–∫–∞ –Ω–∞ Google Places, –ø–∞—Ä—Å–µ—Ä –¥–ª—è prom.ua –∏ –ø—Ä–∏–º–µ—Ä —Å–∫–∞—á–∏–≤–∞–Ω–∏—è –∫–∞—Ä—Ç–∏–Ω–æ–∫ —Å –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω—ã–º –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ–º –∏—Ö —Ö–∞—Ä–∞–∫—Ç–µ—Ä–∏—Å—Ç–∏–∫.
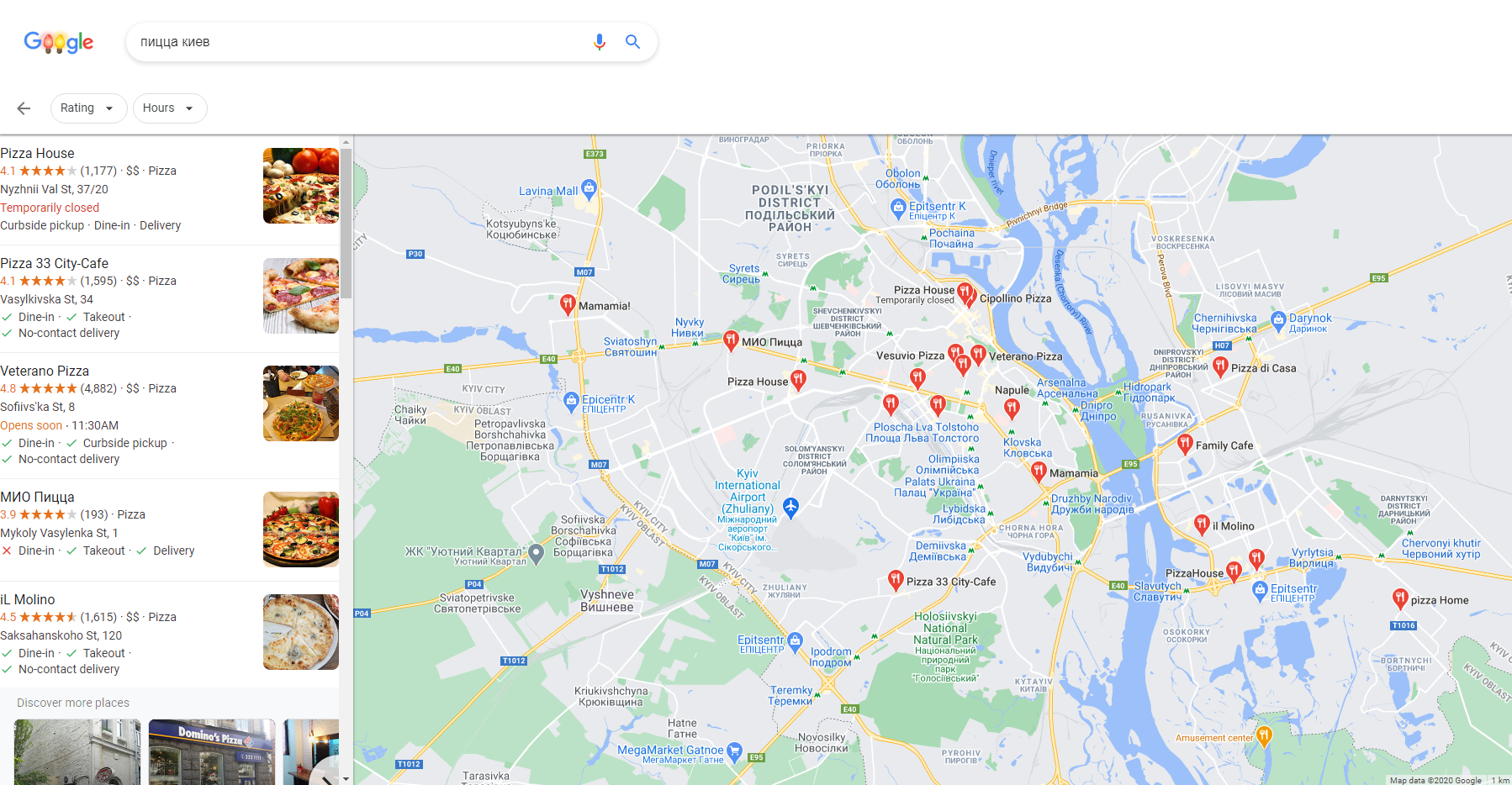
–ü–∞—Ä—Å–µ—Ä Google Places
–ü–∞—Ä—Å–µ—Ä –¥–ª—è –ø–æ–∏—Å–∫–∞ –∑–∞–≤–µ–¥–µ–Ω–∏–π –ø–æ –∫–ª—é—á–µ–≤—ã–º —Å–ª–æ–≤–∞–º –≤ Google Places. –í –æ—Ç–ª–∏—á–∏–µ –æ—Ç –ø–∞—Ä—Å–µ—Ä–∞ Google Maps –∑–¥–µ—Å—å –Ω–µ –Ω—É–∂–Ω–æ –∑–∞–¥–∞–≤–∞—Ç—å –∫–æ–æ—Ä–¥–∏–Ω–∞—Ç—ã –ø–æ–∏—Å–∫–∞, –∞ –¥–æ—Å—Ç–∞—Ç–æ—á–Ω–æ –≤–º–µ—Å—Ç–µ —Å –∫–ª—é—á–µ–≤—ã–º —Å–ª–æ–≤–æ–º –Ω–∞–ø–∏—Å–∞—Ç—å –Ω—É–∂–Ω—ã–π –≥–æ—Ä–æ–¥.
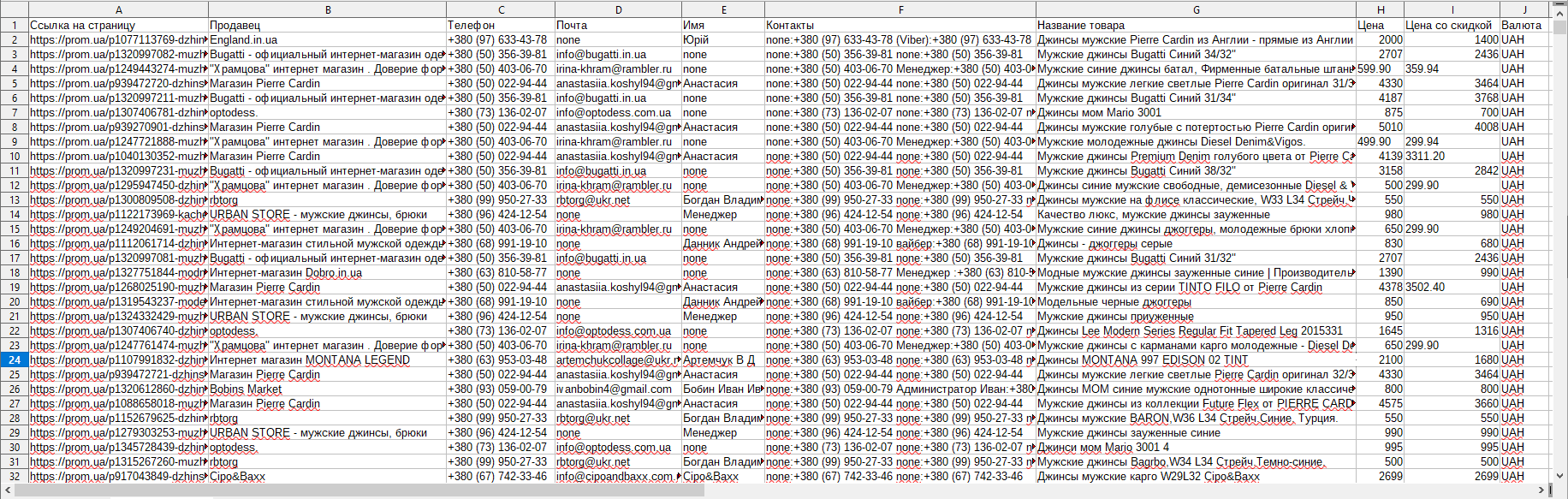
–ü–∞—Ä—Å–µ—Ä prom.ua
–ü–∞—Ä—Å–∏–Ω–≥ —Ç–æ–≤–∞—Ä–Ω—ã—Ö –ø–æ–∑–∏—Ü–∏–π –¥–ª—è –æ–¥–Ω–æ–π –∏–∑ –∫—Ä—É–ø–Ω–µ–π—à–∏—Ö –≤ –£–∫—Ä–∞–∏–Ω–µ —Ç–æ—Ä–≥–æ–≤—ã—Ö –ø–ª–æ—â–∞–¥–æ–∫ prom.ua. –ö—Ä–æ–º–µ —Å–æ–±—Å—Ç–≤–µ–Ω–Ω–æ –Ω–∞–∑–≤–∞–Ω–∏–π —Ç–æ–≤–∞—Ä–æ–≤ –∏ –∏—Ö —Ü–µ–Ω, –ø–æ–∑–≤–æ–ª—è–µ—Ç —Å–æ–±–∏—Ä–∞—Ç—å —Ç–∞–∫–∏–µ –¥–∞–Ω–Ω—ã–µ –ø—Ä–æ–¥–∞–≤—Ü–æ–≤, –∫–∞–∫ —Ç–µ–ª–µ—Ñ–æ–Ω—ã –∏ —ç–ª–µ–∫—Ç—Ä–æ–Ω–Ω—ã–µ –ø–æ—á—Ç—ã.
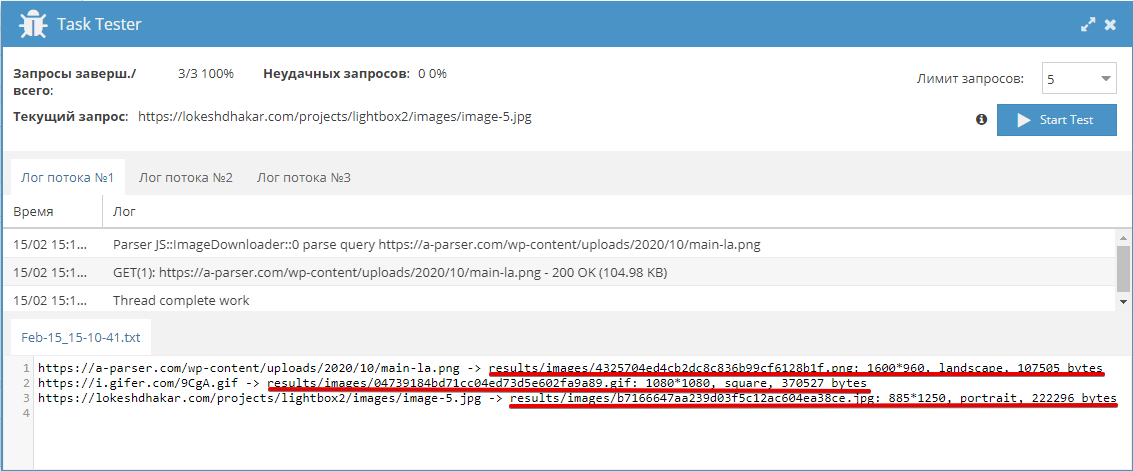
–°–∫–∞—á–∏–≤–∞–Ω–∏–µ –∫–∞—Ä—Ç–∏–Ω–æ–∫
–í —ç—Ç–æ–º –ø—Ä–∏–º–µ—Ä–µ –ø–æ–∫–∞–∑–∞–Ω —Å–ø–æ—Å–æ–± —Ä–µ—à–µ–Ω–∏—è –∑–∞–¥–∞—á–∏ –ø–æ —Å–∫–∞—á–∏–≤–∞–Ω–∏—é –∫–∞—Ä—Ç–∏–Ω–æ–∫ –∏ –æ–¥–Ω–æ–≤—Ä–µ–º–µ–Ω–Ω–æ–º—É –ø–æ–ª—É—á–µ–Ω–∏—é –∏—Ö —Ö–∞—Ä–∞–∫—Ç–µ—Ä–∏—Å—Ç–∏–∫, –∞ –∏–º–µ–Ω–Ω–æ —Ä–∞–∑–º–µ—Ä–∞ –∏ –æ—Ä–∏–µ–Ω—Ç–∞—Ü–∏–∏. –î–ª—è –ø–æ–ª—É—á–µ–Ω–∏—è —Ö–∞—Ä–∞–∫—Ç–µ—Ä–∏—Å—Ç–∏–∫ –∏—Å–ø–æ–ª—å–∑—É–µ—Ç—Å—è NodeJS –º–æ–¥—É–ª—å.
–ï—â–µ –±–æ–ª—å—à–µ —Ä–∞–∑–ª–∏—á–Ω—ã—Ö —Ä–µ—Ü–µ–ø—Ç–æ–≤ –≤ –Ω–∞—à–µ–º –ö–∞—Ç–∞–ª–æ–≥–µ!
–ü—Ä–µ–¥–ª–∞–≥–∞–π—Ç–µ –≤–∞—à–∏ –∏–¥–µ–∏ –¥–ª—è –Ω–æ–≤—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –∑–¥–µ—Å—å, –ª—É—á—à–∏–µ –±—É–¥—É—Ç —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω—ã –∏ –æ–ø—É–±–ª–∏–∫–æ–≤–∞–Ω—ã.
–ü–æ–¥–ø–∏—Å—ã–≤–∞–π—Ç–µ—Å—å –Ω–∞ –Ω–∞—à –∫–∞–Ω–∞–ª –Ω–∞ Youtube - —Ç–∞–º —Ä–µ–≥—É–ª—è—Ä–Ω–æ –≤—ã–∫–ª–∞–¥—ã–≤–∞—é—Ç—Å—è –≤–∏–¥–µ–æ —Å –ø—Ä–∏–º–µ—Ä–∞–º–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è A-Parser, –∞ —Ç–∞–∫–∂–µ —Å–ª–µ–¥–∏—Ç–µ –∑–∞ –Ω–æ–≤–æ—Å—Ç—è–º–∏ –≤ Twitter.
–í—Å–µ —Å–±–æ—Ä–Ω–∏–∫–∏ —Ä–µ—Ü–µ–ø—Ç–æ–≤
- 0
- 03.03.2021 12:33–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
1.2.1148 - –Ω–∞–∫–æ–ø–∏—Ç–µ–ª—å–Ω–æ–µ –æ–±–Ω–æ–≤–ª–µ–Ω–∏–µ –≤—Å—Ç—Ä–æ–µ–Ω–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –∏ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–µ Bypass Cloudflare

–£–ª—É—á—à–µ–Ω–∏—è- –í
 HTML::LinkExtractor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è Skip comment blocks, –∫–æ—Ç–æ—Ä–∞—è –ø–æ–∑–≤–æ–ª—è–µ—Ç –∏—Å–∫–ª—é—á–∏—Ç—å –∏–∑ –ø–∞—Ä—Å–∏–Ω–≥–∞ –±–ª–æ–∫–∏ html –∫–æ–º–º–µ–Ω—Ç–∞—Ä–∏–µ–≤
HTML::LinkExtractor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –æ–ø—Ü–∏—è Skip comment blocks, –∫–æ—Ç–æ—Ä–∞—è –ø–æ–∑–≤–æ–ª—è–µ—Ç –∏—Å–∫–ª—é—á–∏—Ç—å –∏–∑ –ø–∞—Ä—Å–∏–Ω–≥–∞ –±–ª–æ–∫–∏ html –∫–æ–º–º–µ–Ω—Ç–∞—Ä–∏–µ–≤ - –ü–æ–≤—ã—à–µ–Ω–∞ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å
 Shop::Yandex::Market
Shop::Yandex::Market - –í
 Check::RosKomNadzor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –≤—ã–±–∏—Ä–∞—Ç—å –∏—Å—Ç–æ—á–Ω–∏–∫ –¥–ª—è –ø—Ä–æ–≤–µ—Ä–∫–∏
Check::RosKomNadzor –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –≤—ã–±–∏—Ä–∞—Ç—å –∏—Å—Ç–æ—á–Ω–∏–∫ –¥–ª—è –ø—Ä–æ–≤–µ—Ä–∫–∏  Maps::Yandex –ø–µ—Ä–µ–ø–∏—Å–∞–Ω –Ω–∞ TypeScript, –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –ø–æ–¥–∫–ª—é—á–µ–Ω–∏—è —Å–µ—Ä–≤–∏—Å–æ–≤ —Ä–∞–∑–≥–∞–¥—ã–≤–∞–Ω–∏—è –∫–∞–ø—Ç—á
Maps::Yandex –ø–µ—Ä–µ–ø–∏—Å–∞–Ω –Ω–∞ TypeScript, –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –ø–æ–¥–∫–ª—é—á–µ–Ω–∏—è —Å–µ—Ä–≤–∏—Å–æ–≤ —Ä–∞–∑–≥–∞–¥—ã–≤–∞–Ω–∏—è –∫–∞–ø—Ç—á- –í
 Rank::Alexa::API –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –ø–æ–ª—É—á–∞—Ç—å –Ω–∞–∑–≤–∞–Ω–∏–µ —Å—Ç—Ä–∞–Ω—ã –≤–º–µ—Å—Ç–æ –µ–µ –∫–æ–¥–∞
Rank::Alexa::API –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –ø–æ–ª—É—á–∞—Ç—å –Ω–∞–∑–≤–∞–Ω–∏–µ —Å—Ç—Ä–∞–Ω—ã –≤–º–µ—Å—Ç–æ –µ–µ –∫–æ–¥–∞ - –í
 Rank::Ahrefs —Ä–∞—Å—à–∏—Ä–µ–Ω –ø–µ—Ä–µ—á–µ–Ω—å —Å–æ–±–∏—Ä–∞–µ–º—ã—Ö –¥–∞–Ω–Ω—ã—Ö
Rank::Ahrefs —Ä–∞—Å—à–∏—Ä–µ–Ω –ø–µ—Ä–µ—á–µ–Ω—å —Å–æ–±–∏—Ä–∞–µ–º—ã—Ö –¥–∞–Ω–Ω—ã—Ö - –í
 SE::Seznam –¥–æ–±–∞–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ —Å–µ—Å—Å–∏–π –∏ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Ä–∞–∑–≥–∞–¥—ã–≤–∞—Ç—å –∫–∞–ø—Ç—á–∏
SE::Seznam –¥–æ–±–∞–≤–ª–µ–Ω–∞ –ø–æ–¥–¥–µ—Ä–∂–∫–∞ —Å–µ—Å—Å–∏–π –∏ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Ä–∞–∑–≥–∞–¥—ã–≤–∞—Ç—å –∫–∞–ø—Ç—á–∏ - –Ý–µ–∞–ª–∏–∑–æ–≤–∞–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å –ø—Ä–æ–∫—Å–∏ —Å –æ–¥–Ω–∏–º IP:port, –Ω–æ —Å —Ä–∞–∑–Ω—ã–º–∏ –ª–æ–≥–∏–Ω–∞–º–∏
- –ú–Ω–æ–∂–µ—Å—Ç–≤–æ —Ä–∞–∑–ª–∏—á–Ω—ã—Ö –∞–¥–∞–ø—Ç–∞—Ü–∏–π –∫ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º –≤ –≤–µ—Ä—Å—Ç–∫–µ —Å—Ç—Ä–∞–Ω–∏—Ü —Å —Ä–µ–∑—É–ª—å—Ç–∞—Ç–∞–º–∏ –≤ SE::Google –∏ SE::Yandex
- –ú–Ω–æ–∂–µ—Å—Ç–≤–æ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–π –≤
 Rank::MajesticSEO, —Å–≤—è–∑–∞–Ω–Ω—ã—Ö —Å –ø–æ—Å—Ç–æ—è–Ω–Ω—ã–º–∏ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º–∏ –≤ –ª–æ–≥–∏–∫–µ –∑–∞–ø—Ä–æ—Å–∞ –∏ –≤–µ—Ä—Å—Ç–∫–µ —Å—Ç—Ä–∞–Ω–∏—Ü—ã
Rank::MajesticSEO, —Å–≤—è–∑–∞–Ω–Ω—ã—Ö —Å –ø–æ—Å—Ç–æ—è–Ω–Ω—ã–º–∏ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º–∏ –≤ –ª–æ–≥–∏–∫–µ –∑–∞–ø—Ä–æ—Å–∞ –∏ –≤–µ—Ä—Å—Ç–∫–µ —Å—Ç—Ä–∞–Ω–∏—Ü—ã - –í Rank::Alexa::API –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –ø–æ–ª—É—á–µ–Ω–∏–µ –∫–æ–¥–∞ —Å—Ç—Ä–∞–Ω—ã
–í Rank::Ahrefs –∏—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–∞—Ä—Å–∏–Ω–≥ —Ä–µ–π—Ç–∏–Ω–≥–∞ - –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ —Å –∫–∞–ø—Ç—á–∞–º–∏ –≤ SE::Yandex,
 SE::Yandex::SQI,
SE::Yandex::SQI,  SE::Yandex::Images
SE::Yandex::Images - –ò—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–∞—Ä—Å–∏–Ω–≥ $keywords –≤
 SE::Yandex::ByImage
SE::Yandex::ByImage - –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞
 SE::Yandex::Direct,
SE::Yandex::Direct,  SE::Ask,
SE::Ask,  SE::Baidu,
SE::Baidu,  SE::Bing::Suggest,
SE::Bing::Suggest,  Rank::KeysSo,
Rank::KeysSo,  SE::Google::TrustCheck,
SE::Google::TrustCheck,  SE::Google::ByImage, Check::RosKomNadzor, SE::Seznam,
SE::Google::ByImage, Check::RosKomNadzor, SE::Seznam,  SE::MailRu, Rank::Ahrefs,
SE::MailRu, Rank::Ahrefs,  Rank::Ahrefs::KeywordDifficulty, Rank::Ahrefs::KeywordGenerator
Rank::Ahrefs::KeywordDifficulty, Rank::Ahrefs::KeywordGenerator
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω —ç–∫—Å–ø–µ—Ä–∏–º–µ–Ω—Ç–∞–ª—å–Ω—ã–π –æ–±—Ö–æ–¥ –∑–∞—â–∏—Ç—ã Cloudflare —Å –ø–æ–º–æ—â—å—é Chrome
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ –≤ Maps::Yandex, –∏–∑-–∑–∞ –∫–æ—Ç–æ—Ä–æ–π –Ω–µ —Å–æ–±–∏—Ä–∞–ª–æ—Å—å –±–æ–ª—å—à–µ 1 —Å—Ç—Ä–∞–Ω–∏—Ü—ã, –∞ —Ç–∞–∫–∂–µ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –ø—Ä–æ–±–ª–µ–º–∞ —Å –ø–æ–ª—É—á–µ–Ω–∏–µ–º –∏—Å—Ö–æ–¥–Ω–æ–≥–æ –∫–æ–¥–∞ —Å—Ç—Ä–∞–Ω–∏—Ü
- –í SE::Youtube –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –∏–≥–Ω–æ—Ä–∏—Ä–æ–≤–∞–Ω–∏–µ –Ω–∞—Å—Ç—Ä–æ–µ–∫ –ø–æ–∏—Å–∫–∞, –ø—Ä–æ—Ö–æ–¥ –ø–æ –ø–∞–≥–∏–Ω–∞—Ü–∏–∏, –∞ —Ç–∞–∫–∂–µ –≤ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö —Å–ª—É—á–∞—è—Ö –Ω–µ –¥–µ–ª–∞–ª–∏—Å—å –ø–æ–≤—Ç–æ—Ä–Ω—ã–µ –ø–æ–ø—ã—Ç–∫–∏
- –í SE::Google::KeywordPlanner –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –∞–≤—Ç–æ—Ä–∏–∑–∞—Ü–∏—è
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —É—Ç–µ—á–∫–∞ –ø–∞–º—è—Ç–∏, –∫–æ—Ç–æ—Ä–∞—è –ø—Ä–æ—è–≤–ª—è–ª–∞—Å—å –ø—Ä–∏ –¥–æ–ª–≥–æ —Ä–∞–±–æ—Ç–∞—é—â–∏—Ö –∑–∞–¥–∞–Ω–∏—è—Ö —Å –±–æ–ª—å—à–∏–º —á–∏—Å–ª–æ–º –∑–∞–ø—Ä–æ—Å–æ–≤
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ —Å Buffer, –ø—Ä–æ–±–ª–µ–º–∞ –ø–æ—è–≤–∏–ª–∞—Å—å –≤ –æ–¥–Ω–æ–π –∏–∑ –ø—Ä–µ–¥—ã–¥—É—â–∏—Ö –≤–µ—Ä—Å–∏–π
- 0
- 14.05.2021 23:14–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–û–±–Ω–æ–≤–ª–µ–Ω–∏–µ –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏–∏ –∏ –∫—É—Ä—Å –ø–æ –∑–∞—Ä–∞–±–æ—Ç–∫—É –Ω–∞ PBN –∏—Å–ø–æ–ª—å–∑—É—è A-Parser
–û–±–Ω–æ–≤–ª–µ–Ω–Ω–∞—è –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏—è
–ú—ã –Ω–µ —Å—Ç–æ–∏–º –Ω–∞ –º–µ—Å—Ç–µ: –ø–æ—Å—Ç–æ—è–Ω–Ω–æ —Å–æ–≤–µ—Ä—à–µ–Ω—Å—Ç–≤—É–µ–º –Ω–∞—à –ø—Ä–æ–¥—É–∫—Ç, —Ä–∞—Å—à–∏—Ä—è–µ–º –µ–≥–æ —Ñ—É–Ω–∫—Ü–∏–æ–Ω–∞–ª, –æ—Ä–∏–µ–Ω—Ç–∏—Ä—É—è—Å—å –Ω–∞ —Å–µ–≥–æ–¥–Ω—è—à–Ω–∏–µ –ø–æ—Ç—Ä–µ–±–Ω–æ—Å—Ç–∏ –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ –Ω–∞ —É–¥–æ–±—Å—Ç–≤–æ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è A-Parser. –í —Å–æ–æ—Ç–≤–µ—Ç—Å—Ç–≤–∏–∏ —Å —ç—Ç–∏–º –º—ã –ø–æ–ª–Ω–æ—Å—Ç—å—é –æ–±–Ω–æ–≤–∏–ª–∏ –Ω–∞—à—É —Ç–µ—Ö–Ω–∏—á–µ—Å–∫—É—é –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏—é, –≤ –ø–µ—Ä–≤—É—é –æ—á–µ—Ä–µ–¥—å –∏–∑–º–µ–Ω–∏–ª–∏ –∏–Ω—Ç–µ—Ä—Ñ–µ–π—Å, —Å–æ–∑–¥–∞–ª–∏ –ª–æ–≥–∏—á–Ω—É—é —Å—Ç—Ä—É–∫—Ç—É—Ä—É —Ä–∞–∑–¥–µ–ª–æ–≤, –ø—Ä–µ–¥—É—Å–º–æ—Ç—Ä–µ–ª–∏ —É–¥–æ–±–Ω—É—é –Ω–∞–≤–∏–≥–∞—Ü–∏—é –∏ –ø–æ–∏—Å–∫.
–ö—Ä–æ–º–µ –¥–æ–ø–æ–ª–Ω–µ–Ω–∏—è –∏ –æ–±–Ω–æ–≤–ª–µ–Ω–∏—è —Å—É—â–µ—Å—Ç–≤—É—é—â–µ–π –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏–∏ –¥–æ–±–∞–≤–ª–µ–Ω—ã –Ω–æ–≤—ã–µ, —Ä–∞–Ω–µ–µ –Ω–µ –ø—É–±–ª–∏–∫–æ–≤–∞–≤—à–∏–µ—Å—è —Ä–∞–∑–¥–µ–ª—ã:- –Ω–∞—Å—Ç—Ä–æ–π–∫–∞ –∏ —Ä–∞–±–æ—Ç–∞ —Å Docker
- –Ω–æ–≤–æ–µ API v2 –¥–ª—è –Ω–∞–ø–∏—Å–∞–Ω–∏—è JS –ø–∞—Ä—Å–µ—Ä–æ–≤ —Å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ–º TypeScript
- –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ Chrome —Å –ø—Ä–æ–∫—Å–∏ —Å –ø–æ–º–æ—â—å—é Puppeteer
- –≤–∑–∞–∏–º–æ–¥–µ–π—Å—Ç–≤–∏–µ —Å A-Parser —á–µ—Ä–µ–∑ Redis API
- –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–µ Node.js –º–æ–¥—É–ª–µ–π
–¢–∞–∫–∂–µ, –¥–ª—è –≤—Å–µ—Ö –≤—Å—Ç—Ä–æ–µ–Ω–Ω—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –¥–æ–±–∞–≤–∏–ª–∏ –±–ª–æ–∫–∏ —Å –ø—Ä–∏–º–µ—Ä–∞–º–∏ –∏—Ö –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è. –í—Å—è –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏—è —Å–æ–ø—Ä–æ–≤–æ–∂–¥–∞–µ—Ç—Å—è —Å–∫—Ä–∏–Ω—à–æ—Ç–∞–º–∏ –∏ —Ä–∞–∑–ª–∏—á–Ω—ã–º–∏ –ø—Ä–∏–º–µ—Ä–∞–º–∏, –±–æ–ª—å—à–∏–Ω—Å—Ç–≤–æ –∏–∑ –∫–æ—Ç–æ—Ä—ã—Ö –º–æ–∂–Ω–æ –∏–º–ø–æ—Ä—Ç–∏—Ä–æ–≤–∞—Ç—å –≤ —Å–≤–æ–π –ê-–ü–∞—Ä—Å–µ—Ä –∏ –∏–∑—É—á–∏—Ç—å.
–û–±–Ω–æ–≤–ª–µ–Ω–Ω–∞—è –¥–æ–∫—É–º–µ–Ω—Ç–∞—Ü–∏—è –µ—â–µ –±—É–¥–µ—Ç —Ä–∞—Å—à–∏—Ä—è—Ç—å—Å—è –∏ –¥–æ–ø–æ–ª–Ω—è—Ç—å—Å—è, –Ω–æ –í—ã —É–∂–µ —Å–µ–π—á–∞—Å –º–æ–∂–µ—Ç–µ –æ–∑–Ω–∞–∫–æ–º–∏—Ç—å—Å—è —Å –Ω–µ–π, –ø–µ—Ä–µ–π–¥—è –ø–æ —Å—Å—ã–ª–∫–µ: https://a-parser.com/docs/
–ö—É—Ä—Å –ø–æ –∑–∞—Ä–∞–±–æ—Ç–∫—É –Ω–∞ PBN –∏—Å–ø–æ–ª—å–∑—É—è A-Parser(+–≤–∫–ª—é—á–∞–µ—Ç –ª–∏—Ü–µ–Ω–∑–∏—é)
Наш хороший друг Николай Кодий запускает второй набор на курсы по подбору дропов и построению качественных сеток PBN, с применением A-Parser в качестве одного из основных инструментов. Каждый из студентов бесплатно получает весь лицензионный софт (в том числе и A-Parser), необходимый для подбора дропов. Данный курс без "воды" — вы получите концентрат опыта и алгоритмы наработок, которые никто другой не показывает. Курс насыщен практикой на реальных задачах. Каждый выпускник сможет в дальнейшем сотрудничать с Николаем или получить рекомендацию от него и контакты компаний, которые часто ищут специалистов по PBN. Подробнее о курсе читайте в его телеграм-канале https://t.me/mypbn/1113

- 0
- 27.05.2021 17:23–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
–°–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤ #46: –ø–∞—Ä—Å–∏–Ω–≥ —Å–æ–æ–±—â–µ–Ω–∏–π –∏–∑ Viber, –∫–æ—Ä–µ–π—Å–∫–∏–π –ø–æ–∏—Å–∫–æ–≤–∏–∫ –∏ —Å–±–æ—Ä –∫–æ–Ω—Ç–∞–∫—Ç–æ–≤ –æ—Ä–≥–∞–Ω–∏–∑–∞—Ü–∏–π
46-–π —Å–±–æ—Ä–Ω–∏–∫ —Ä–µ—Ü–µ–ø—Ç–æ–≤, –≤ –∫–æ—Ç–æ—Ä—ã–π –≤–æ—à–ª–∏ –ø–∞—Ä—Å–µ—Ä —Å–æ–æ–±—â–µ–Ω–∏–π Viber, –ø–∞—Ä—Å–µ—Ä –∫–æ—Ä–µ–π—Å–∫–æ–≥–æ –ø–æ–∏—Å–∫–æ–≤–∏–∫–∞ –∏ –ø—Ä–µ—Å–µ—Ç –¥–ª—è —Å–±–æ—Ä–∞ –∫–æ–Ω—Ç–∞–∫—Ç–æ–≤ –æ—Ä–≥–∞–Ω–∏–∑–∞—Ü–∏–π –∏–∑ –∫–∞—Ç–∞–ª–æ–≥–∞.
–ü–∞—Ä—Å–µ—Ä Viber - —Å–±–æ—Ä —Å–æ–æ–±—â–µ–Ω–∏–π –∏–∑ –ø—É–±–ª–∏—á–Ω—ã—Ö –≥—Ä—É–ø–ø –≤–∞–π–±–µ—Ä
–í –ê-–ü–∞—Ä—Å–µ—Ä–µ —É–∂–µ –¥–æ–≤–æ–ª—å–Ω–æ –¥–∞–≤–Ω–æ —Å—É—â–µ—Å—Ç–≤—É–µ—Ç –ø–∞—Ä—Å–µ—Ä –¥–ª—è —Å–±–æ—Ä–∞ —Å–æ–æ–±—â–µ–Ω–∏–π –∏–∑ –ø—É–±–ª–∏—á–Ω—ã—Ö –≥—Ä—É–ø–ø –≤ Telegram. –ü—Ä–µ–¥—Å—Ç–∞–≤–ª—è–µ–º –∞–Ω–∞–ª–æ–≥–∏—á–Ω–æ–µ —Ä–µ—à–µ–Ω–∏–µ –¥–ª—è –Ω–µ –º–µ–Ω–µ–µ –ø–æ–ø—É–ª—è—Ä–Ω–æ–≥–æ –º–µ—Å—Å–µ–Ω–¥–∂–µ—Ä–∞ - Viber.

–ü–∞—Ä—Å–µ—Ä –∫–æ—Ä–µ–π—Å–∫–æ–≥–æ –ø–æ–∏—Å–∫–æ–≤–∏–∫–∞ Daum.net
–ï—â–µ –æ–¥–∏–Ω –ø–∞—Ä—Å–µ—Ä –ø–æ–∏—Å–∫–æ–≤—ã—Ö —Å–∏—Å—Ç–µ–º, –Ω–∞ —ç—Ç–æ—Ç —Ä–∞–∑ –∫–æ—Ä–µ–π—Å–∫–æ–π daum.net
–ü–∞—Ä—Å–∏–Ω–≥ –∫–æ–Ω—Ç–∞–∫—Ç–æ–≤ –æ—Ä–≥–∞–Ω–∏–∑–∞—Ü–∏–π –∏–∑ ua-region.info
–ü—Ä–µ—Å–µ—Ç –¥–ª—è —Å–±–æ—Ä–∞ —Ç–µ–ª–µ—Ñ–æ–Ω–æ–≤, –ø–æ—á—Ç, —Å–∞–π—Ç–æ–≤, –∞–¥—Ä–µ—Å–æ–≤ –∏ –ø—Ä–æ—á–µ–π –∏–Ω—Ñ–æ—Ä–º–∞—Ü–∏–∏ –∏–∑ –∫–∞—Ç–∞–ª–æ–≥–∞ –æ—Ä–≥–∞–Ω–∏–∑–∞—Ü–∏–π ua-region.info
–ï—â–µ –±–æ–ª—å—à–µ —Ä–∞–∑–ª–∏—á–Ω—ã—Ö —Ä–µ—Ü–µ–ø—Ç–æ–≤ –≤ –Ω–∞—à–µ–º –ö–∞—Ç–∞–ª–æ–≥–µ!
–ü—Ä–µ–¥–ª–∞–≥–∞–π—Ç–µ –≤–∞—à–∏ –∏–¥–µ–∏ –¥–ª—è –Ω–æ–≤—ã—Ö –ø–∞—Ä—Å–µ—Ä–æ–≤ –∑–¥–µ—Å—å, –ª—É—á—à–∏–µ –±—É–¥—É—Ç —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω—ã –∏ –æ–ø—É–±–ª–∏–∫–æ–≤–∞–Ω—ã.
–ü–æ–¥–ø–∏—Å—ã–≤–∞–π—Ç–µ—Å—å –Ω–∞ –Ω–∞—à –∫–∞–Ω–∞–ª –Ω–∞ Youtube - —Ç–∞–º —Ä–µ–≥—É–ª—è—Ä–Ω–æ –≤—ã–∫–ª–∞–¥—ã–≤–∞—é—Ç—Å—è –≤–∏–¥–µ–æ —Å –ø—Ä–∏–º–µ—Ä–∞–º–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏—è A-Parser, –∞ —Ç–∞–∫–∂–µ —Å–ª–µ–¥–∏—Ç–µ –∑–∞ –Ω–æ–≤–æ—Å—Ç—è–º–∏ –≤ Twitter.
–í—Å–µ —Å–±–æ—Ä–Ω–∏–∫–∏ —Ä–µ—Ü–µ–ø—Ç–æ–≤
- 0
- 16.06.2021 19:53–û–ø—ã—Ç–Ω—ã–π
- –Ý–µ–≥–∏—Å—Ç—Ä–∞—Ü–∏—è: 17.08.2010
- –°–æ–æ–±—â–µ–Ω–∏–π: 309
- –Ý–µ–ø—É—Ç–∞—Ü–∏—è: 23
1.2.1239 - –æ–±–Ω–æ–≤–ª–µ–Ω–∏–µ Node.js, –ø–æ–¥–¥–µ—Ä–∂–∫–∞ ReCaptcha v3 –∏ Smart captcha, –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–∏–µ –æ—à–∏–±–æ–∫

–£–ª—É—á—à–µ–Ω–∏—è- Node.js –æ–±–Ω–æ–≤–ª–µ–Ω –¥–æ –≤–µ—Ä—Å–∏–∏ 15.14.0
- –î–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å —Ä–∞–∑–≥–∞–¥—ã–≤–∞—Ç—å Google ReCaptcha v3 –≤ –≤–∏–¥–µ –Ω–æ–≤–æ–≥–æ –ø–∞—Ä—Å–µ—Ä–∞
 Util::ReCaptcha3
Util::ReCaptcha3 - –í SE::Yandex, –∞ —Ç–∞–∫–∂–µ –≤ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö –¥—Ä—É–≥–∏—Ö –ø–∞—Ä—Å–µ—Ä–∞—Ö –Ø–Ω–¥–µ–∫—Å–∞ —Ä–µ–∞–ª–∏–∑–æ–≤–∞–Ω–∞ –æ–±—Ä–∞–±–æ—Ç–∫–∞ –Ω–æ–≤–æ–π Smart captcha
- –í Rank::MajesticSEO –¥–æ–±–∞–≤–ª–µ–Ω —Ä–µ–∂–∏–º –ø–∞—Ä—Å–∏–Ω–≥–∞ —á–µ—Ä–µ–∑ Chrome
- –í
 SE::DuckDuckGo –∞–∫—Ç—É–∞–ª–∏–∑–∏—Ä–æ–≤–∞–Ω—ã —è–∑—ã–∫–∏ –∏ —Ä–µ–≥–∏–æ–Ω—ã
SE::DuckDuckGo –∞–∫—Ç—É–∞–ª–∏–∑–∏—Ä–æ–≤–∞–Ω—ã —è–∑—ã–∫–∏ –∏ —Ä–µ–≥–∏–æ–Ω—ã - –í
 SE::Google::Cache –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Å–µ—Ä–≤–∏—Å—ã —Ä–∞–∑–≥–∞–¥—ã–≤–∞–Ω–∏—è —Ä–µ–∫–∞–ø—Ç—á
SE::Google::Cache –¥–æ–±–∞–≤–ª–µ–Ω–∞ –≤–æ–∑–º–æ–∂–Ω–æ—Å—Ç—å –∏—Å–ø–æ–ª—å–∑–æ–≤–∞—Ç—å —Å–µ—Ä–≤–∏—Å—ã —Ä–∞–∑–≥–∞–¥—ã–≤–∞–Ω–∏—è —Ä–µ–∫–∞–ø—Ç—á - –í
 SE::YouTube –¥–æ–±–∞–≤–ª–µ–Ω —Å–±–æ—Ä —Å—Å—ã–ª–æ–∫ –Ω–∞ –∫–∞–Ω–∞–ª
SE::YouTube –¥–æ–±–∞–≤–ª–µ–Ω —Å–±–æ—Ä —Å—Å—ã–ª–æ–∫ –Ω–∞ –∫–∞–Ω–∞–ª - –ê–∫—Ç—É–∞–ª–∏–∑–∏—Ä–æ–≤–∞–Ω —Å–ø–∏—Å–æ–∫ —è–∑—ã–∫–æ–≤ –≤
 DeepL::Translator
DeepL::Translator - –¢–µ–ø–µ—Ä—å –≤ SE::Bing –ø—Ä–∏ –æ–±–Ω–∞—Ä—É–∂–µ–Ω–∏–∏ –±–∞–Ω–∞, –ø—Ä–æ–∫—Å–∏ –±–∞–Ω–∏—Ç—Å—è –ø–∞—Ä—Å–µ—Ä–æ–º –≤–º–µ—Å—Ç–æ –ø—Ä–æ—Å—Ç–æ–π —Å–º–µ–Ω—ã
- –í
 Shop::Amazon –æ–±–Ω–æ–≤–ª–µ–Ω —é–∑–µ—Ä-–∞–≥–µ–Ω—Ç, –∑–∞ —Å—á–µ—Ç —á–µ–≥–æ –≤—ã—Ä–æ—Å–ª–∞ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å
Shop::Amazon –æ–±–Ω–æ–≤–ª–µ–Ω —é–∑–µ—Ä-–∞–≥–µ–Ω—Ç, –∑–∞ —Å—á–µ—Ç —á–µ–≥–æ –≤—ã—Ä–æ—Å–ª–∞ –ø—Ä–æ–∏–∑–≤–æ–¥–∏—Ç–µ–ª—å–Ω–æ—Å—Ç—å
- –ú–Ω–æ–∂–µ—Å—Ç–≤–æ –∞–¥–∞–ø—Ç–∞—Ü–∏–π SE::Google –∏ SE::Yandex –∫ –∏–∑–º–µ–Ω–µ–Ω–∏—è–º –≤ –≤–µ—Ä—Å—Ç–∫–µ —Å—Ç—Ä–∞–Ω–∏—Ü —Å –≤—ã–¥–∞—á–µ–π
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–æ—Å—Ç–æ—è–Ω–Ω—ã–π –±–∞–Ω –∑–∞–ø—Ä–æ—Å–æ–≤ –≤ SE::Google::Cache –∏ SE::Bing
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω –ø—Ä–æ—Ö–æ–¥ –ø–æ –ø–∞–≥–∏–Ω–∞—Ü–∏–∏ –≤ SE::DuckDuckGo
- –í SE::Youtube –∏—Å–ø—Ä–∞–≤–ª–µ–Ω –ø–æ–¥—Å—á–µ—Ç –∫–æ–ª-–≤–∞ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –∏ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏–µ —Å—É—â–µ—Å—Ç–≤–æ–≤–∞–Ω–∏—è —Å–ª–µ–¥—É—é—â–µ–π —Å—Ç—Ä–∞–Ω–∏—Ü—ã
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ —Å –∫–∞–ø—Ç—á–µ–π –≤ Shop::Amazon
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–∑–±–∏–≤–∫–∞ –Ω–∞ –±–ª–æ–∫–∏ –±–æ–ª—å—à–∏—Ö –∑–∞–ø—Ä–æ—Å–æ–≤ –≤ SE::Yandex::Translate
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω—ã SE::Bing, SE::MailRu,
 SE::MailRu::Position,
SE::MailRu::Position,  SE::Google::Compromised, Rank::MajesticSEO, Rank::KeysSo, SE::Yandex::Direct,SecurityTrails::IP, Net::Whois, SE::Bing::Translator, SE::DuckDuckGo, Social::Instagram::Profile, Shop::Yandex::Market, Rank::Ahrefs::KeywordGenerator, Rank::Ahrefs::KeywordDifficulty,SE::Seznam, Shop::Amazon, Rank::Linkpad
SE::Google::Compromised, Rank::MajesticSEO, Rank::KeysSo, SE::Yandex::Direct,SecurityTrails::IP, Net::Whois, SE::Bing::Translator, SE::DuckDuckGo, Social::Instagram::Profile, Shop::Yandex::Market, Rank::Ahrefs::KeywordGenerator, Rank::Ahrefs::KeywordDifficulty,SE::Seznam, Shop::Amazon, Rank::Linkpad
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω –±–∞–≥ –≤ HTML::LinkExtractor, –∏–∑-–∑–∞ –∫–æ—Ç–æ—Ä–æ–≥–æ –ø–∞—Ä—Å–∏–Ω–≥ –ø–æ –∑–∞–ø—Ä–æ—Å—É –æ—Å—Ç–∞–Ω–∞–≤–ª–∏–≤–∞–ª—Å—è —Å –æ—à–∏–±–∫–æ–π
- –í Rank::MOZ –∏—Å–ø—Ä–∞–≤–ª–µ–Ω–æ –æ—Ç—Å—É—Ç—Å—Ç–≤–∏–µ –ø–æ–≤—Ç–æ—Ä–Ω—ã—Ö –ø–æ–ø—ã—Ç–æ–∫, –∞ —Ç–∞–∫–∂–µ –∏–∑–º–µ–Ω–µ–Ω–∞ –ª–æ–≥–∏–∫–∞ –æ–ø—Ä–µ–¥–µ–ª–µ–Ω–∏—è –Ω–µ—É–¥–∞—á–Ω—ã—Ö –∑–∞–ø—Ä–æ—Å–æ–≤
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –æ—à–∏–±–∫–∞ –ø—Ä–æ–≤–µ—Ä–∫–∏ –ø—Ä–æ–∫—Å–∏, –µ—Å–ª–∏ –≤ –ø–∞—Ä–æ–ª–µ –±—ã–ª —Å–∏–º–≤–æ–ª "*"
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω –±–∞–≥, –∏–∑-–∑–∞ –∫–æ—Ç–æ—Ä–æ–≥–æ –ø—Ä–∏ –∏—Å–ø–æ–ª—å–∑–æ–≤–∞–Ω–∏–∏ —à–∞–±–ª–æ–Ω–∏–∑–∞—Ç–æ—Ä–∞ –≤ Additional headers –ø–µ—Ä–µ—Å—Ç–∞–≤–∞–ª —Ä–∞–±–æ—Ç–∞—Ç—å Check content
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ –ª–æ–≥–∏–∫–∞ –ø—Ä–æ–≤–µ—Ä–∫–∏ —Ä–µ–∑—É–ª—å—Ç–∞—Ç–æ–≤ –≤
 SE::Bing::Images
SE::Bing::Images - –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ XPath
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —É—Ç–µ—á–∫–∞ –ø–∞–º—è—Ç–∏: –ø—Ä–∏ –¥–ª–∏—Ç–µ–ª—å–Ω–æ–π —Ä–∞–±–æ—Ç–µ –ø—Ä–æ—Ü–µ—Å—Å node.js –ø–æ—Å—Ç–µ–ø–µ–Ω–Ω–æ –∑–∞–ø–æ–ª–Ω—è–ª –≤—Å—é –¥–æ—Å—Ç—É–ø–Ω—É—é –æ–ø–µ—Ä–∞—Ç–∏–≤–Ω—É—é –ø–∞–º—è—Ç—å
- –ò—Å–ø—Ä–∞–≤–ª–µ–Ω–∞ —Ä–∞–±–æ—Ç–∞ —Å –ø—Ä–æ–∫—Å–∏ –Ω–∞ –Ω–µ–∫–æ—Ç–æ—Ä—ã—Ö —Å–∞–π—Ç–∞—Ö, –±–∞–≥ –ø–æ—è–≤–∏–ª—Å—è –≤ –æ–¥–Ω–æ–π –∏–∑ –ø—Ä–µ–¥—ã–¥—É—â–∏—Ö –±–µ—Ç–∞-–≤–µ—Ä—Å–∏–π

- 0





–¢—ç–≥–∏ —Ç–æ–ø–∏–∫–∞:
- a-parser,
- bing,
- dmoz,
- dns,
- google,
- harm,
- html,
- ip,
- linkextractor,
- nofollow,
- parser,
- parsers,
- qip,
- suggest,
- whois,
- wordstat,
- yahoo,
- yandex,
- –≤–µ—Ä—Å–∏—è,
- –≥—É–≥–ª,
- –¥–æ–º–µ–Ω,
- –∏–∑–º–µ–Ω–µ–Ω–∏–µ,
- –∫–µ–π–≤–æ—Ä–¥—ã,
- –∫–ª—é—á–µ–≤—ã–µ —Å–ª–æ–≤–∞,
- –Ω–æ–≤—ã–π,
- –ø–∞—Ä—Å–µ—Ä,
- –ø–æ–¥—Å–∫–∞–∑–∫–∏,
- –ø–æ–∏—Å–∫–æ–≤—ã–π,
- –ø—Ä–æ–¥–≤–∏–Ω—É—Ç—å,
- —Ä–µ–∑—É–ª—å—Ç–∞—Ç,
- —Å–≤—è–∑—å,
- —Å–∏—Å—Ç–µ–º–∞,
- —è–Ω–¥–µ–∫—Å
–ü–æ—Ö–æ–∂–∏–µ —Ç–µ–º—ã
| –¢–µ–º—ã | –Ý–∞–∑–¥–µ–ª | –û—Ç–≤–µ—Ç–æ–≤ | –ü–æ—Å–ª–µ–¥–Ω–∏–π –ø–æ—Å—Ç |
|---|---|---|---|
LTK Parser - –ø–∞—Ä—Å–µ—Ä –ø–æ–∏—Å–∫–æ–≤—ã—Ö –ø–æ–¥—Å–∫–∞–∑–æ–∫ –Ω–∞ —Ä–∞–∑–Ω—ã—Ö —è–∑—ã–∫–∞—Ö | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, –ª–∏—Ü–µ–Ω–∑–∏–∏ | 12 | 06.05.2012 21:10 |
–ü–∞—Ä—Å–µ—Ä –∫–æ–Ω—Ç–µ–Ω—Ç–∞ –ø–æ–¥ –¥–æ—Ä–≤–µ–∏ –∏ —Å–∞—Ç–µ–ª–ª–∏—Ç—ã X-Parser | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, —Å–µ—Ä–≤–∏—Å—ã | 0 | 15.08.2010 23:51 |
KD Parser - –ø–∞—Ä—Å–µ—Ä –∫–ª—é—á–µ–≤—ã—Ö —Å–ª–æ–≤ | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, –ª–∏—Ü–µ–Ω–∑–∏–∏ | 2 | 10.04.2010 21:47 |
–•–æ—Ä–æ—à–∏–π –ü–∞—Ä—Å–µ—Ä –Ø.–î–∏—Ä–µ–∫—Ç –∏ Wordstat - –ú–∞–≥–∞–¥–∞–Ω | –ü–æ–∏—Å–∫–æ–≤—ã–µ —Å–∏—Å—Ç–µ–º—ã | 10 | 24.11.2009 16:52 |
–•–æ—Ä–æ—à–∏–π –ü–∞—Ä—Å–µ—Ä –Ø.–î–∏—Ä–µ–∫—Ç –∏ Wordstat - –ú–∞–≥–∞–¥–∞–Ω | –°–æ—Ñ—Ç, —Å–∫—Ä–∏–ø—Ç—ã, —Å–µ—Ä–≤–∏—Å—ã | 4 | 15.09.2009 19:38 |
---------- adult dragon-soul kyrsor libraries m-analytics post proxy romanov-crowd traffic turbotext woocommerce zennoposter –∞–¥–º–∏–Ω–∫–∞ –±–∞–Ω–∞–ª—å–Ω—ã–π –±–∞–Ω–Ω–µ—Ä –±—ã—Ç—å –≤–µ—Ä—Å—Ç–∫–∞ –≤–∫–æ–Ω—Ç–∞–∫—Ç –≤–æ–∑–º–æ–∂–Ω—ã–π –≤—ã–±–∏—Ä–∞—Ç—å –≤—ã–π—Ç–∏ –≥–µ–Ω–¥–∞–ª—å—Ñ –≥–æ–¥ –¥–µ—Ç—å –¥—É–º–∞—Ç—å –∑–∞–∫–∞–∑—á–∏–∫ –∏—Å–∫–∞—Ç—å –∫–∞—Ä—Ç–∏–Ω–∫–∞ –∫–µ–π—Å –∫–∏–Ω–æ—Å–∞–π—Ç –∫–æ–Ω—Ç–µ–Ω—Ç –º–æ–±–∏–ª—å–Ω—ã–π –º–æ–¥—É–ª—å –º–æ–∂–µ—Ç –Ω–∞–¥–µ–∂–Ω—ã–π –Ω–∞–∫—Ä—É—Ç–∫–∞ –Ω–µ–º–Ω–æ–≥–æ –æ–ø—ã—Ç –æ—á–µ–Ω—å –ø–∞—Ä—Å–∏–Ω–≥ –ø–æ–≥–æ–¥–∞ –ø–æ–ª–æ–≤–∏–Ω–∞ –ø–æ–ª—å–∑–æ–≤–∞—Ç—å—Å—è –ø–æ—Å–ª–µ –ø—Ä–æ–≥—Ä–∞–º–º–∞ –ø—Ä–æ–≥—Ä–∞–º–º–∏—Å—Ç –ø—Ä–æ–¥–≤–∏–∂–µ–Ω–∏–µ –ø—Ä–æ–∫—Å–∏ —Ä–∞–±–æ—Ç–∞—Ç—å —Ä–∞–∑–º–µ—â–µ–Ω–∏–µ —Ä—É–∫–∞ —Å–∞–π—Ç —Å–∏–¥–µ—Ç—å —Å–∫—Ä—ã—Ç—å —Å–æ—Ç—Ä—É–¥–Ω–∏—á–µ—Å—Ç–≤–æ —Å—Ç–∞—Ç—å —Å—Ç–∞—Ç—å—è —Ñ–æ–ª–ª–æ–≤–µ—Ä —à–∞–±–ª–æ–Ω—ã
–¢–µ–º:
77,604–°–æ–æ–±—â–µ–Ω–∏–π:
763,372–ü–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π:
30,081–°–µ–π—á–∞—Å –Ω–∞ —Å–∞–π—Ç–µ:
0 –ø–æ–ª—å–∑–æ–≤–∞—Ç–µ–ª–µ–π –∏ 143 –≥–æ—Å—Ç–µ–π